Resource:
Awesome-Learning-with-Label-Noise https://github.com/gorkemalgan/deep_learning_with_noisy_labels_literature
Algan, Görkem, and Ilkay Ulusoy. “Image classification with deep learning in the presence of noisy labels: A survey.” arXiv __preprint arXiv:1912.05170 (2019).
以下内容大多数都是总结了综述[1]
标注数据存在错误怎么办?MIT&Google提出用置信学习找出错误标注(附开源实现)
背景及意义:
现金深度学习都需要大量的正确的标注数据,然而这些标注经常是需要巨大的成本,或者一些数据(例如医学图像)对于专家而言,也难以正确分类数据。在实际应用过程中,标签噪声是数据集中的常见问题,因此如何有效的使用noise label进行训练,消除其负面影响是十分具有意义的方向。
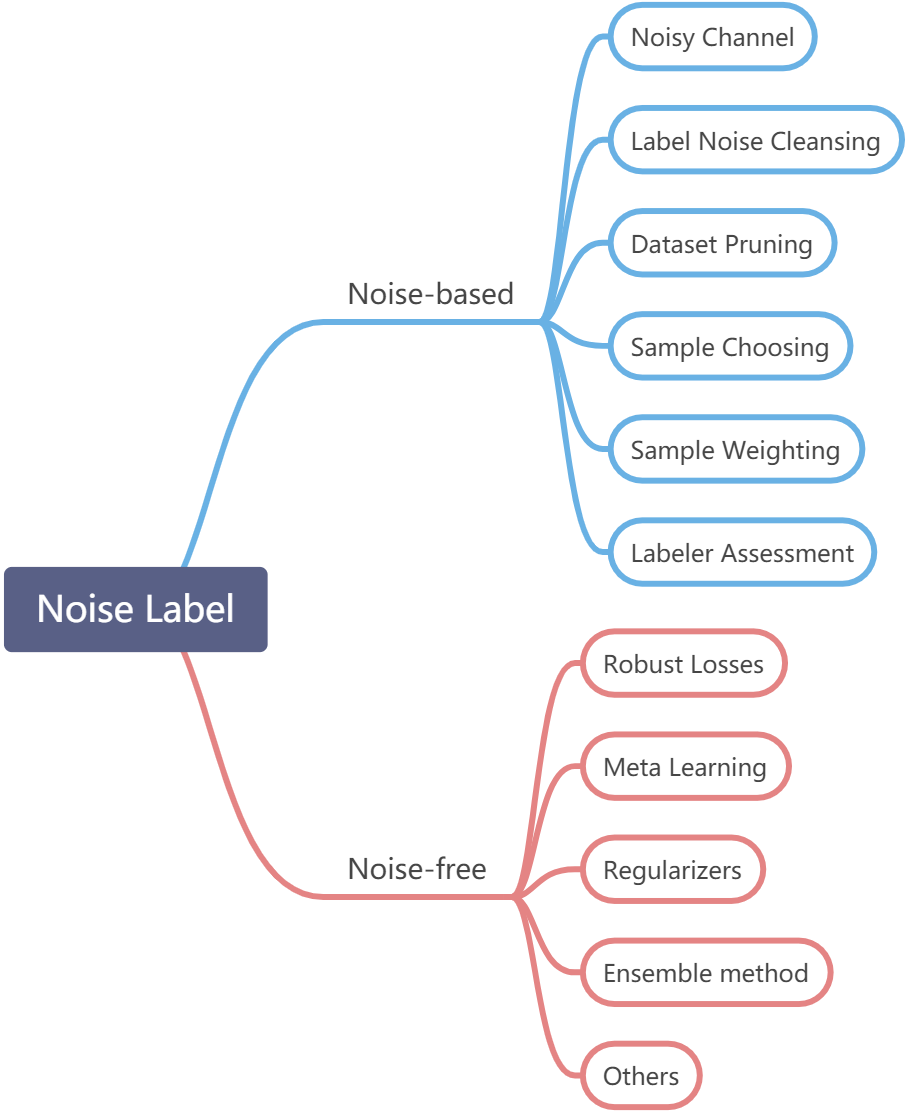
按照[1]我们可以把解决noise label的方式分为以下两类:
- Noise model free methods
- Noise model based methods
Noise model based methods
1、Noisy Channel
关键:求从正确class预测成其他class的概率,然后相应的最惩罚。
Noisy Channel-based 的方式主要做的就是minimize下面这个东西(loss里面作用):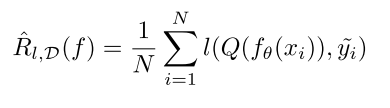
这里的 ,
, 是网络输出,
是网络输出, 是一个矩阵matrix,代表从true label预测到false label的可能性,如果有c个类别,那这个T应该就是c*1的矩阵。因此优化上面这个公式可以使得分类错误的可能性越小。
是一个矩阵matrix,代表从true label预测到false label的可能性,如果有c个类别,那这个T应该就是c*1的矩阵。因此优化上面这个公式可以使得分类错误的可能性越小。
在这类工作中主要去求这个 。求出Q之后加惩罚之类的。
。求出Q之后加惩罚之类的。
部分论文:
Making deep neural networks robust to label noise: A loss correction approach[2]
Using trusted data to train deep networks on labels corrupted by severe noise[3]
Webly supervised learning of convolutional networks[4]
2、Label Noise Cleansing
关键:label**清洗算法,通过feature extractor在高维空间区分noise label进行清洗。**
大概过程可以用下面这个公式表示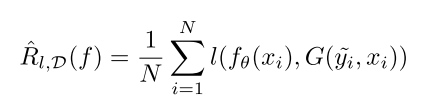
这里的 代表label清洗算法。
代表label清洗算法。
主要分下面三种清洗算法:
- Using data with clean labels:
Iterative cross learning on noisy labels[6]使用不同子集的数据集训练网络,如果对于image的预测都相同,则该设置该image的label为这个预测,反之设置为任意值
Toward robustness against label noise in training deep discriminative neural networks[7]使用一种 graph-based的方法, noisy labels和clean labels之间的关系由条件随机场提取。
- Using data with both clean and noisy labels:
Learning from noisy large-scale datasets with minimal supervision[8] 提出一个label cleaning network,这个网络有两个输入extracted features和对应的corresponding noisy labels。label cleaning network和分类器同时训练,一边矫正一边将较真后正确的label用于监督。
- Using data with just noisy labels:
Probabilistic end-to-end noise correction for learning with noisy labels[9]在标签后验上附加compatibility loss condition。考虑到noise label占少数,这一项保证了posterior label distribution不会与given noisy label distribution有太多的偏离,从而不会损失大部分的clean label贡献.
3、Dataset Pruning
关键:删除小部分training sample(最有可能是noise label),抑制noise label负面影响
O2u-net: A simple noisy label detection approach for deep neural networks[10]循环调整学习率,使网络状态在欠拟合和过拟合之间变化。存在noise label样本的loss更大,因此在此循环过程中,noise label较大的样本将被去除。
4、Sample Choosing
关键:有选择的输入sample进行优化网络,抑制带来负面影响的noise label的干扰,这个选择是一直更新。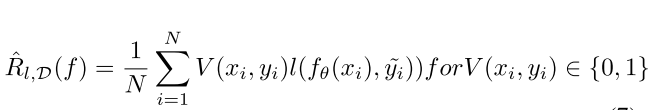
这这个公式里面, 是一个binary operator,决定是否使用这个输入data。当这个
是一个binary operator,决定是否使用这个输入data。当这个 是一个static function提取确定的筛选方法,这个问题就变成了Dataset Pruning。不同的是,sample choosing methods不断的更新选择sample用于下一个iteration。
是一个static function提取确定的筛选方法,这个问题就变成了Dataset Pruning。不同的是,sample choosing methods不断的更新选择sample用于下一个iteration。
- Curriculum Learning
Progressive stochastic learning for noisy labels[11]提出了各种屏蔽损失函数,以根据实例的噪声级别对实例进行排序。
Curriculumnet: Weakly supervised learning from large- scale web images[12] 数据根据其复杂性被分成subgroups,这些subgroups由一个预先训练过的网络在整个数据集上提取。由于不太复杂的subgroups趋向于更干净的label,因此训练将从不太复杂的subgroups开始,随着网络的改善,将会经过更复杂的subgroups。通过检验label与网络预测的一致性,可以选择下一个待训练的样本。
- Multiple Classifiers
Co-mining: Deep face recognition with noisy labels[13] 通过对两个网络不一致的数据进行迭代,co-teaching的想法得到了进一步的改进,以防止两个网络随着epoch的增加而相互融合.
5、Sample Importance Weighting
关键:与sample choosing类似,根据sample估计的噪声水平给不同的sample分配权重,提高训练的效率。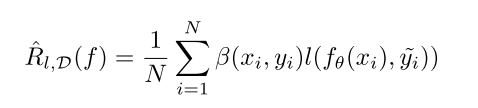
 是不同的sample对应的权重,
是不同的sample对应的权重, 是一个dynamic function,他的值在训练过程中是持续变化的.
是一个dynamic function,他的值在训练过程中是持续变化的.
Deep bilevel learning[14]使用meta-learning paradigm确定权重因子。在每次迭代中,每个mini-batch的gradient descent step的weighting factor被确定,从而使在clean data上数据的loss最小化。
Iterative learning with open-set noisy labels[15]考虑了Open-set noisy labels,其中与noisy labels相关的数据样本可能属于训练数据中不存在的class。
6、Labeler Quality Assessment
关键:由于标注者的掺插不齐,标注质量有好有坏,将标注质量进行建模也是有必要的。
Deep learning from crowds[16] 增加crowd-layer 在network最后面,使得混淆矩阵更为稀疏。
Discussion
Noise-based model很大程度上依赖对噪声结构的准确分析,这东西有特殊性
缺点:这类方法通常对数据noise label分布、特点做出假设,这个损害了不同noise label设置的适用性。
优势:引入先验假设也是有利的,有利于解决domain- specific noise,比较有针对更容易实施起来。
Noise model free methods
这类方法的目的是在没有明确建模的情况下实现noise label的鲁棒性,而不是在提出的算法增强鲁棒性。noise label被当作异常处理,因此这些方法与解决over-fitting的方法类似。
1、Robust Losses
关键:提出Robust Losses使得模型在使用noisy 或者 noise-free data都能达到相同的表现效果。
**
On symmetric losses for learning from corrupted labels[17] 某些非凸损失函数,如0-1损失,比常用的凸损失具有更强的噪声容忍度。
L dmi: A novel information- theoretic loss function for training deep nets robust to label noise[18]提出了基于information-theoretic loss,给定的label和prediction之间的mutual information是被评估的加入loss function。
论文:链接
代码:https://github.com/LiJunnan1992/MLNT
关键词: “synthetic noisy labels” ,“noise-tolerant” , “underlying knowledge”
为了消除noise label的负面影响,本文提出了一种noise-tolerant training algorithm。该算法模拟现实训练通过生成合成噪声label。使用合成noise labels训练模型的输出应该和teacher model的输出保持一致,通过self-ensembling method来构建teacher model使得,使其更可靠不受noise label的影响。
2、Meta Learning
关键:Meta lea**rning的目的是通过学习任务所需的复杂函数,以及学习学习本身来减少人为参与。
Learning from noisy labels with distillation[19] 在存在clean data情况下,可以定义一个meta来利用这些信息。在这个方法中使用的方法是在一个clean数据集中训练一个teacher网络,并将其知识转移到student网络中,以便在存在noise label数据的情况下也能指导训练。
3、Regularizers
关键:使用正则化去防止模型拟合noise label,这个假设在随机噪声中大部分适用,对于复杂的噪声可能不行。
一些方式如下:
- dropout:Dropout: [20] a simple way to prevent neural networks from overfitting.
- adversarial training: [21] Explaining and harnessing adversarial examples.
- mixup: [22] mixup: Beyond Empirical Risk Minimization,
- label smoothing: [23] Regularizing neural networks by penalizing confident output distributions
4、Ensemble Methods
关键:由于bagging和boosting的不同,使得bagging是更加鲁棒的对于nosiy label。
Bagging,Boosting二者之间的区别
Bagging和Boosting的区别:
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。5、Others
关**键:例如Prototype learning的目的是构建原型,使其能够代表一个类的特征,从而学习干净的表示。文献[25]、[26]提出了对noise label的数据创建干净的代表性原型,从而分类器可以训练的在clean representative prototypes**,而不是对noise label进行训练
**Discussion
Noise model free methods和overfit avoidance 或者 anomaly detection相似的
缺点:对于复杂、结构化的噪声可能效果不好。没办法处理一些特殊情况下的noise label。
优势:这类算法具有普遍性,对于任意噪声是高效的。
Conclusion
建议:如果噪声结构是特定领域的,并且对其noise label结构有先验信息或假设,则noise model based的方法更为合适。在这些模型中,可以根据需要选择最合适的方法。
- 如果可以将噪声表示为noise transition matrix,Noisy channel 或者 Labeler quality assessment 可能有更好的效果。
- 如果目的是净化数据集或者预处理阶段,Dataset pruning 或者 Label noise cleansing methods可以更好的应用的。
- 如果可以根据实例在训练中的信息量对其进行排序,那么Sample choosing 或者 Sample importance weighting algorithms是很方便的。
- 如果噪声是随机的,Noise model free methods是更合适的,更容易实现,性能下降是由于过拟合,一些
Regularizers可以被采用。
- 如果没有干净的数据子集,Robust losses 或者 Regularizers是适当的选择,因为他们对待所有的sample是相同的。
- 元学习技术可以在clean subset of data中使用,因为它们可以很容易地适应来利用这个子集。
2020.7.8尝试方向:
- 2020-ICML - Improving Generalization by Controlling Label-Noise Information in Neural Network Weights [论文] [代码]
- 2020-ICML -
DIVIDEMIX: LEARNING WITH NOISY LABELS AS SEMI-SUPERVISED LEARNING [论文] [代码] - 2019-ICML -
Confident Learning: Estimating Uncertainty in Dataset Labels. [Paper] [Code] - 2019-NIPS -
Noise-tolerantfair classification. [Paper][Code] - 2019-ICCV -
Symmetric Cross Entropy for Robust Learning With Noisy Labels. [Paper][Code] - 2019-CVPR - Learning to Learn from Noisy Labeled Data. [Paper] [Code]
- 2018-ECCV -
CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images. [Paper] [Code] - 2018-CVPR -
CleanNet: Transfer Learning for Scalable Image Classifier Training with Label Noise. [Paper] [Code] - 2020-CVPR - Noise-Aware Fully Webly Supervised Object Detection. [Paper][Code]
- 2019-CVPR -
Probabilistic End-to-end Noise Correction for Learning with Noisy Labels[Paper][Code]
[1] Algan, Görkem, and Ilkay Ulusoy. “Image classification with deep learning in the presence of noisy labels: A survey.” arXiv __preprint arXiv:1912.05170 (2019).
[2] G. Patrini, A. Rozza, A. Krishna Menon, R. Nock, and L. Qu, “Making deep neural networks robust to label noise: A loss correction approach,” in Proceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 1944–1952.
[3] D. Hendrycks, M. Mazeika, D. Wilson, and K. Gimpel, “Using trusted data to train deep networks on labels corrupted by severe noise,” in Advances in neural information processing systems, 2018, pp. 10 456– 10 465.
[4] X. Chen and A. Gupta, “Webly supervised learning of convolutional networks,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 1431–1439.
[5] J. Lee, D. Yoo, J. Y. Huh, and H.-E. Kim, “Photometric Transformer Networks and Label Adjustment for Breast Density Prediction,” may 2019
[6] B. Yuan, J. Chen, W. Zhang, H. S. Tai, and S. McMains, “Iterative cross learning on noisy labels,” in Proceedings - 2018 IEEE Winter Conference on Applications of Computer Vision, WACV 2018, vol. 2018-Janua, 2018, pp. 757–765
[7] A. Vahdat, “Toward robustness against label noise in training deep discriminative neural networks,” in Advances in Neural Information Processing Systems, 2017, pp. 5596–5605.
[8] A. Veit, N. Alldrin, G. Chechik, I. Krasin, A. Gupta, and S. Belongie, “Learning from noisy large-scale datasets with minimal supervision,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 839–847.
[9] K. Yi and J. Wu, “Probabilistic end-to-end noise correction for learning with noisy labels,” in Proceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 7017–7025
[10] J. Huang, L. Qu, R. Jia, and B. Zhao, “O2u-net: A simple noisy label detection approach for deep neural networks,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 3326– 3334.
[11] B. Han, I. W. Tsang, L. Chen, P. Y. Celina, and S.-F. Fung, “Progressive stochastic learning for noisy labels,” IEEE transactions on neural networks and learning systems, no. 99, pp. 1–13, 2018.
[12] S. Guo, W. Huang, H. Zhang, C. Zhuang, D. Dong, M. R. Scott, and D. Huang, “Curriculumnet: Weakly supervised learning from large- scale web images,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 135–150.
[13] X. Wang, S. Wang, J. Wang, H. Shi, and T. Mei, “Co-mining: Deep face recognition with noisy labels,” in Proceedings ofthe IEEE International Conference on Computer Vision, 2019, pp. 9358–9367.
[14] S. Jenni and P. Favaro, “Deep bilevel learning,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 618–633.
[15] Y. Wang, W. Liu, X. Ma, J. Bailey, H. Zha, L. Song, and S.-T. Xia, “Iterative learning with open-set noisy labels,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8688–8696.
[16] F. Rodrigues and F. C. Pereira, “Deep learning from crowds,” in 32nd AAAI Conference on Artificial Intelligence, AAAI 2018, 2018, pp. 1611–1618.
[17] N. Charoenphakdee, J. Lee, and M. Sugiyama, “On symmetric losses for learning from corrupted labels,” arXiv preprint arXiv:1901.09314, 2019.
[18] Y. Xu, P. Cao, Y. Kong, and Y. Wang, “L dmi: A novel information- theoretic loss function for training deep nets robust to label noise,” in Advances in Neural Information Processing Systems, 2019, pp. 6222– 6233.
[19] Y. Li, J. Yang, Y. Song, L. Cao, J. Luo, and L.-J. Li, “Learning from noisy labels with distillation,” in Proceedings ofthe IEEE International Conference on Computer Vision, 2017, pp. 1910–1918
[20] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhut- dinov, “Dropout: a simple way to prevent neural networks from overfitting,” The journal of machine learning research, vol. 15, no. 1, pp. 1929–1958, 2014.
[21] I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” arXiv preprint arXiv:1412.6572, 2014.
[22] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, “mixup: Beyond Empirical Risk Minimization,” oct 2017.
[23] G. Pereyra, G. Tucker, J. Chorowski, Ł. Kaiser, and G. Hinton, “Regularizing neural networks by penalizing confident output distributions,” arXiv preprint arXiv:1701.06548, 2017.
[24] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2818–2826.
[25] W. Zhang, Y. Wang, and Y. Qiao, “Metacleaner: Learning to hallucinate clean representations for noisy-labeled visual recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 7373–7382
[26] P. H. Seo, G. Kim, and B. Han, “Combinatorial inference against label noise,” in Advances in Neural Information Processing Systems, 2019, pp. 1171–1181

若有收获,就点个赞吧
0 人点赞
