Chen, Y., Wang, W., Zhou, Y., Yang, F., Yang, D., & Wang, W. (2020). Self-Training for Domain Adaptive Scene Text Detection. Retrieved from http://arxiv.org/abs/2005.11487
Introduction
背景:作者认为大量的labled数据是必不可少的在现今的表现好的强监督文本检测器,然后data collection和 annotation是成本很高而且代价很高的
因此改论文提出了一个self-trianing框架去为一些unannotated videos or images产生一些pseudo-label用于训练提升target domian 的表现。
为了减少FP和FN,该论文利用了detection and tracking results去产生更好的pseudo-label。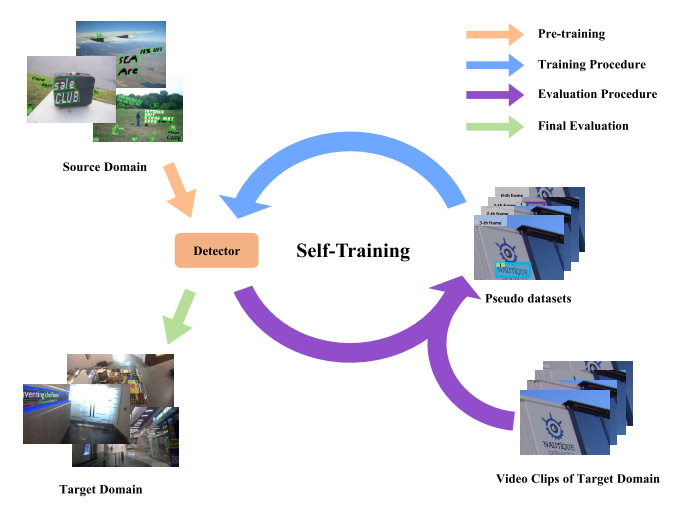
Methods
The contributions are as follows:
1、提出一个domain adaptive 场景文本检测器,使用unlabeled videos和image进行训练。
2、提出一个Text Mining Module(TMM)融合detection 和 tracking的结果,mine hard examples of less noise
3、对于只有image的数据,设计了一种image-to-video的方式去产生video,从而帮助只有image的数据集也能使用论文中提出的这种方法。
Framework Overview
整个网络框架主要包含三个部分:
1、Detection module
2、Tracking module
3、Text Mining Module(TMM)
首先在source domain上面训练模型,然后使用detector和tracker对target domain上的video数据(如果target domain没有video形式的数据,使用image形式的数据去生产)进行处理产生pseudo-label,最后结合detection和tracking的结果,使用TMM对pseudo-label的hard example进行mine。具体的pseudo-label计算如下: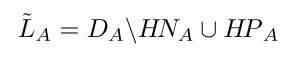
 是Image A的检测结果,
是Image A的检测结果, 代表在中但是不在
代表在中但是不在 中,指的是hard negatives和
中,指的是hard negatives和 hard positives。
hard positives。
整体网络框架如下: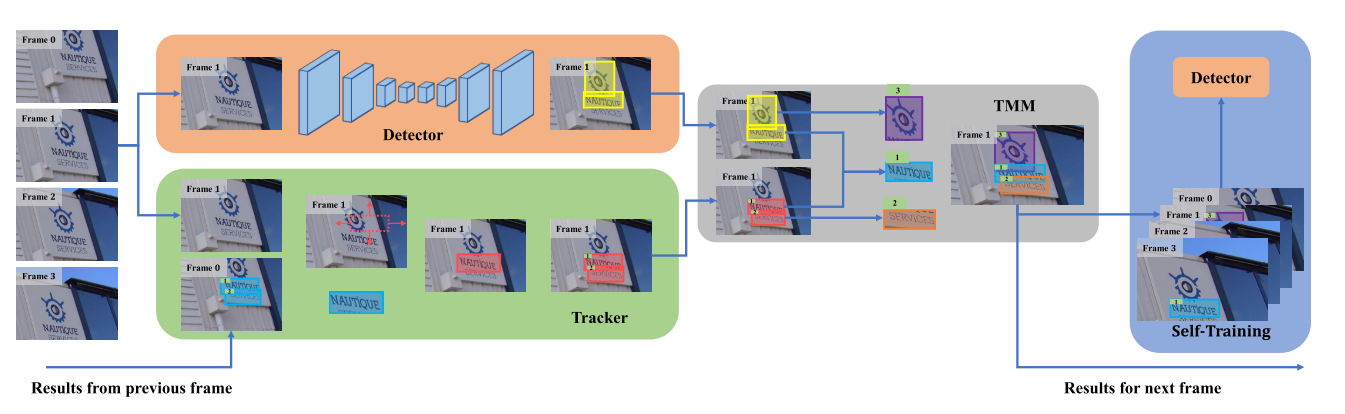
如上图所示:
yellow box是 the detection results
red box 是 the tracking results
blue, purple (hard negative) and orange (hard positive) 是 trajectory results
Each frame of the video 都会被detector和tracker处理。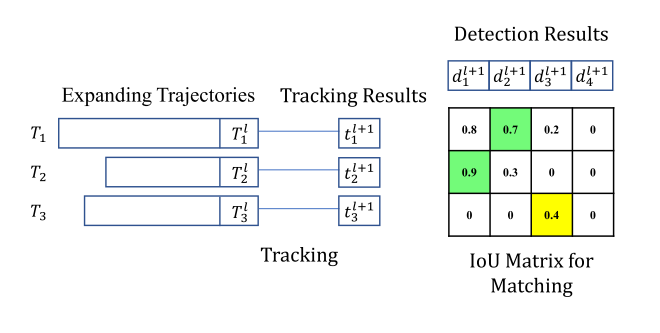
上面这个图是trajectories, tracking results and detection results的关系,绿色代表匹配成功,黄色代表应该被ignore的weak match。
具体是用maximum intersection-over-union (IoU)去匹配这个关系,last item  in a trajectory
in a trajectory  is the trajectory result . 在
is the trajectory result . 在 帧中,有一个tracking result
帧中,有一个tracking result 
 is the matching index,计算如下:
is the matching index,计算如下: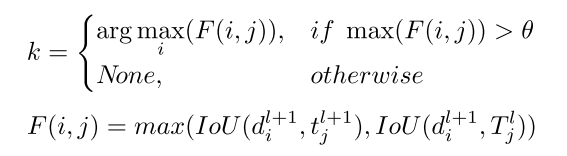
如果 , 就会被
, 就会被 代替,因此这个时候detection result or a tracking result 有一个会被 joined into . 通过这种方式去融合detection和tracking获得一个more accurate trajectory。
代替,因此这个时候detection result or a tracking result 有一个会被 joined into . 通过这种方式去融合detection和tracking获得一个more accurate trajectory。
Text Mining Module(TMM)
TMM主要有三个作用:
(1).选择合适的detection和tracking result作为最终的trajectory result.。
(2).预测一个segmentation mask作为轨迹trajectory result.
(3).第三个任务是hard example mining
在trajectory中,如果一个 tracking result 如果伴随 several consecutive detection results,作者任务这个是hard positive。
如果trajectories是很短的或者有很少的 few detection results认为这个是hard negatives。
When No Video Available
使用sophisticated data enhancement techniques (Gen-Straight) 去将image合成产生video。对于一个image先随机产生一个a rotation angle θ、scaling factor δ和transformation center c。
使用这些参数基于affine transformation matrix去产生ending frame of the video。一旦starting frame  and the ending frame
and the ending frame 确定以后,video of length
确定以后,video of length  can be generated by interpolation.
can be generated by interpolation.
Balance Loss
为了抑制pseudo label中的noise label,提出了一个balance loss如下所示:针对different samples different labels有不同的loss权重相当。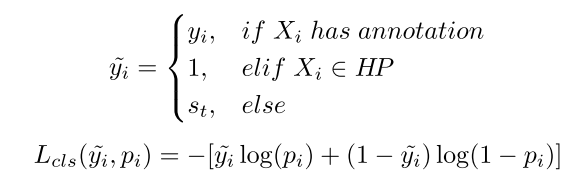
Experiments
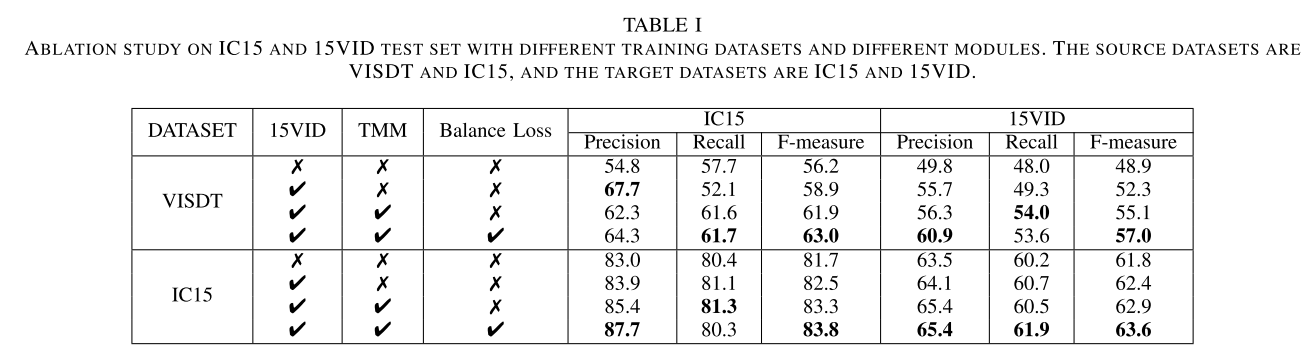
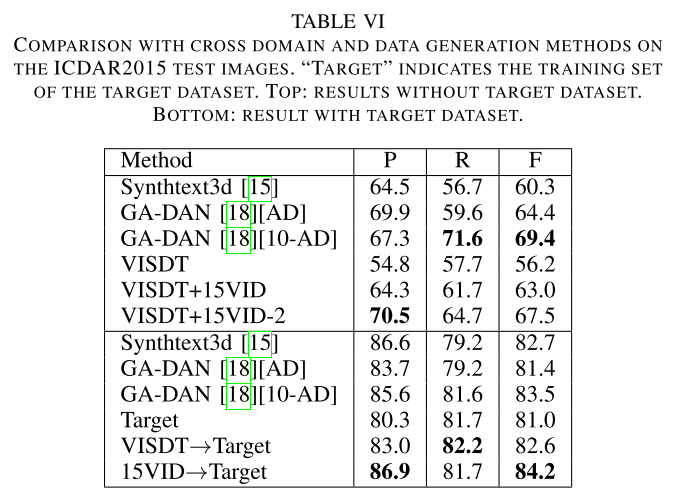
Curved Text Detection in Natural Scene Images with Semi- and Weakly-Supervised Learning
https://arxiv.org/abs/1908.09990
Introduction
背景:pixel-level annotations是高成本的,为了降低成本论文中作者提出使用a small amount of pixel-level annotated data和大量的rectangles标注的数据进行训练。
首先使用少量的pixel-level的标注数据去训练一个baseline,然后使用这个baseline去annotate unlabeled或者weakly labeled data.
The contributions are as follows:
1、提出一个weakly-supervised 场景文本检测器,使用a small amount data with strong polygon/pixel-level annotations 和 a large amount of unannotated or weakly annotated data.进行训练。
2、使用ground-truth bounding boxes as proposals去产生pseudo label。

Feature Extractor: ResNet50 和 FPN
Text Proposal Network: 基于提取到的feature产生text proposal。。 使用a fully convolutional network 产生 text proposals. 采用{0.2, 0.5, 1, 2, 5} 的anchors 比例 on five FPN stages {P2, P3, P4, P5, P6}
Region Feature Sampler: 基于proposal 和feature使用region feature sampler调整定位。。。 ROI-Align
Coarse Localization Network: 使用two fully- connected layers 做 text/non-text classification, coarsely localize curved text with rectangles
Fine Localization Network: made up of four convolution layers is to localize curved text finely with binary mask within given rectangles
Learning strategies
1、Naive strategy
使用unannotated data 直接产生pseudo label进行训练
在小数据上训练得到一个baseline之后,在unlabled数据集上产生candidate pseudo annotation set,
满足公式 取个阈值进行监督。
取个阈值进行监督。
2、Filter strategy
使用 a large amount of weakly annotated data  with horizontal rectangles
with horizontal rectangles  作为辅助去产生这个pseudo label
作为辅助去产生这个pseudo label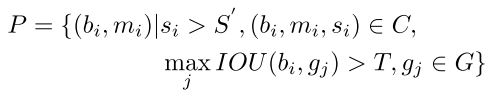
其实就是用box和pseudo label做个iou计算,过滤掉一些iou小的pseudo label。
3、Local strategy
we directly take the ground-truth bound- ing boxes as proposals,感觉和我们不一样的只是他这个conv feature应该是用整个图训的,就是mask rcnn提取到的backbone的feature。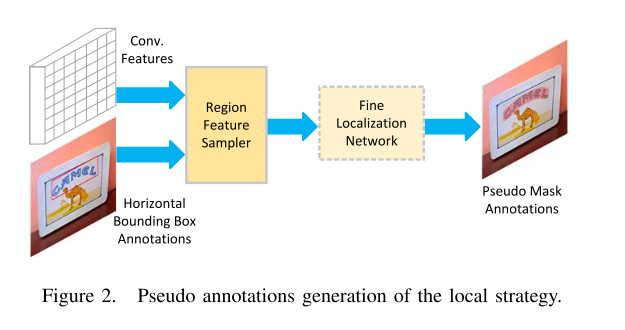
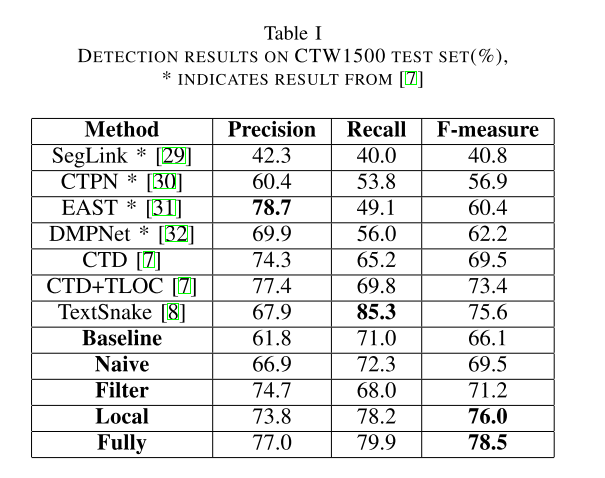
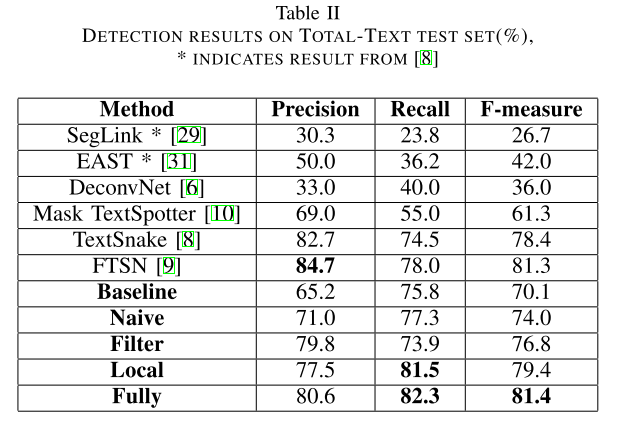
Experiments
WeText: Scene Text Detection under Weak Supervision
https://arxiv.org/abs/1710.04826
WordSup: Exploiting Word Annotations for Character based Text Detection
https://arxiv.org/abs/1708.06720
[1] R. Li, M. En, J. Li, and H. Zhang, “Weakly supervised text attention network for generating text proposals in scene images,” in ICDAR, vol. 1, 2017, pp. 324–330
[2] L. Neumann and J. Matas, “A method for text localization and recognition in real-world images,” in ACCV, 2010, pp. 770–783
[3] S. Tian, Y. Pan, C. Huang, S. Lu, K. Yu, and C. Lim Tan, “Text flow: A unified text detection system in natural scene images,” in ICCV, 2015, pp. 4651–4659
[4] C. Bartz, H. Yang, and C. Meinel, “SEE: towards semi-supervised end-to-end scene text recognition,” in AAAI, 2018.

若有收获,就点个赞吧
0 人点赞
