论文:https://arxiv.org/abs/1906.05849
代码:https://github.com/HobbitLong/CMC/
关键词: multiview contrastive learning , mutual information , sensory channels
Tian, Yonglong, Dilip Krishnan, and Phillip Isola. “Contrastive multiview coding**.” arXiv preprint arXiv:1906.05849 (2019).
人是可以从很多sensory channels中去看这个世界:如long-wavelength light channel,high-frequency vibrations channel 。 每个view是有噪声不完整的,但是重要的是physics, geometry, and semantics是共享的,比如一只狗在所有的view里面是可以被看见,听见和感受到的。在该论文中认为好的representation是view-invariant 的。
Motivation
想要学到一个好的representation,论文中利用了multiview contrastive learning最大化mutual information在different views中对于同一个scene。
在CMC 这边文章中表明了,使用不同场景 (View Point, Depth, Color Space) 来计算 Contrastive Loss 能达到非常好的效果,因此 Contrastive 本身 (也就是辨认 Positive & Negative Sample 之间的 Consistency) 才是关键。
Main Contributions:
1、使用contrastive learning去maximize 同一个场景的不同view的mutual information。
Proposed method
对于一个输入的image,首先得到很多sensory views,我们可以学习到一个好的deep representation通过使用这些sensory view,下面是四个views和学到的representation,每个视图的编码可以结合起来形成一个场景的完全表示。
因此该论文得目的是学习到shared feature 来自于 multiple sensory channels,舍弃channel-specific nuisance factors 。为了实现这个目的,论文使用了Contrastive Predictive Coding去实现学习,在这里叫做Contrastive Multiview Coding,目的是最大化 mutual information between the representations of multiple views of the data。
论文中使用 去代表不同的views,
去代表不同的views, 代表representation:
代表representation: .
.
下面先介绍Predictive Learning vs Contrastive Learning的区别,红点框表示的是loss应用在这个part。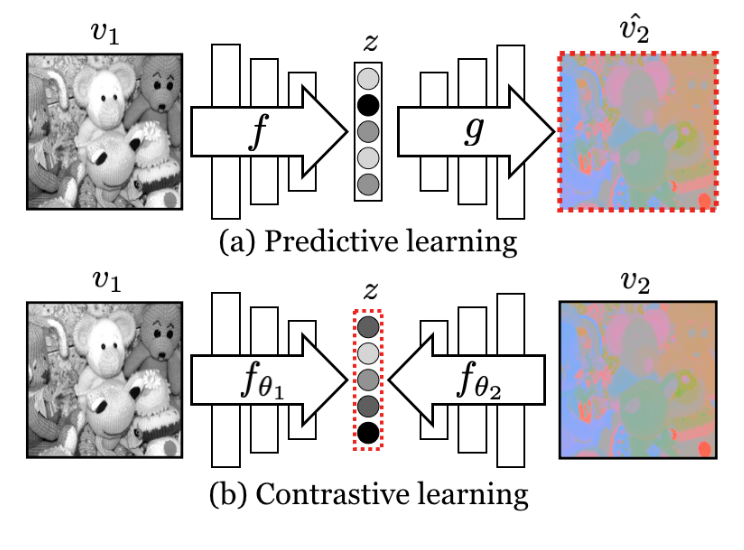
Contrastive Learning with Two Views
对于sample来着相同的分布 ,我们把这个叫做是positive sample,对于sample来自不同分布
,我们把这个叫做是positive sample,对于sample来自不同分布 ,我们把这个叫做negative sample。
,我们把这个叫做negative sample。
和之前的contrastive learning一样,我们训练一个model去从k个negative中挑选出正确的positive。 。为了实现这个效果我们固定两个views中的一个,然后收集positive和大量的negative来自其他view:
。为了实现这个效果我们固定两个views中的一个,然后收集positive和大量的negative来自其他view: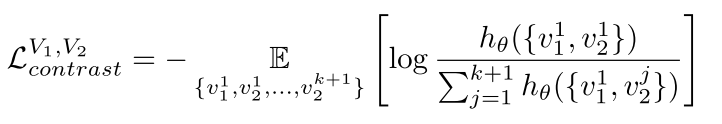
Implementing the critic
two encoders  和
和 被使用去提取latent representions:
被使用去提取latent representions:  ,
,  ,然后通过计算他们的cosine similarity 调整他们的动态范围:
,然后通过计算他们的cosine similarity 调整他们的动态范围: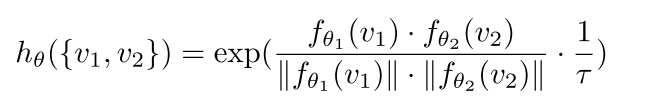
最终的一个loss可以如下所示: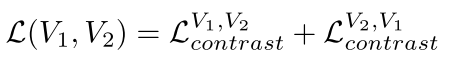

若有收获,就点个赞吧
0 人点赞
