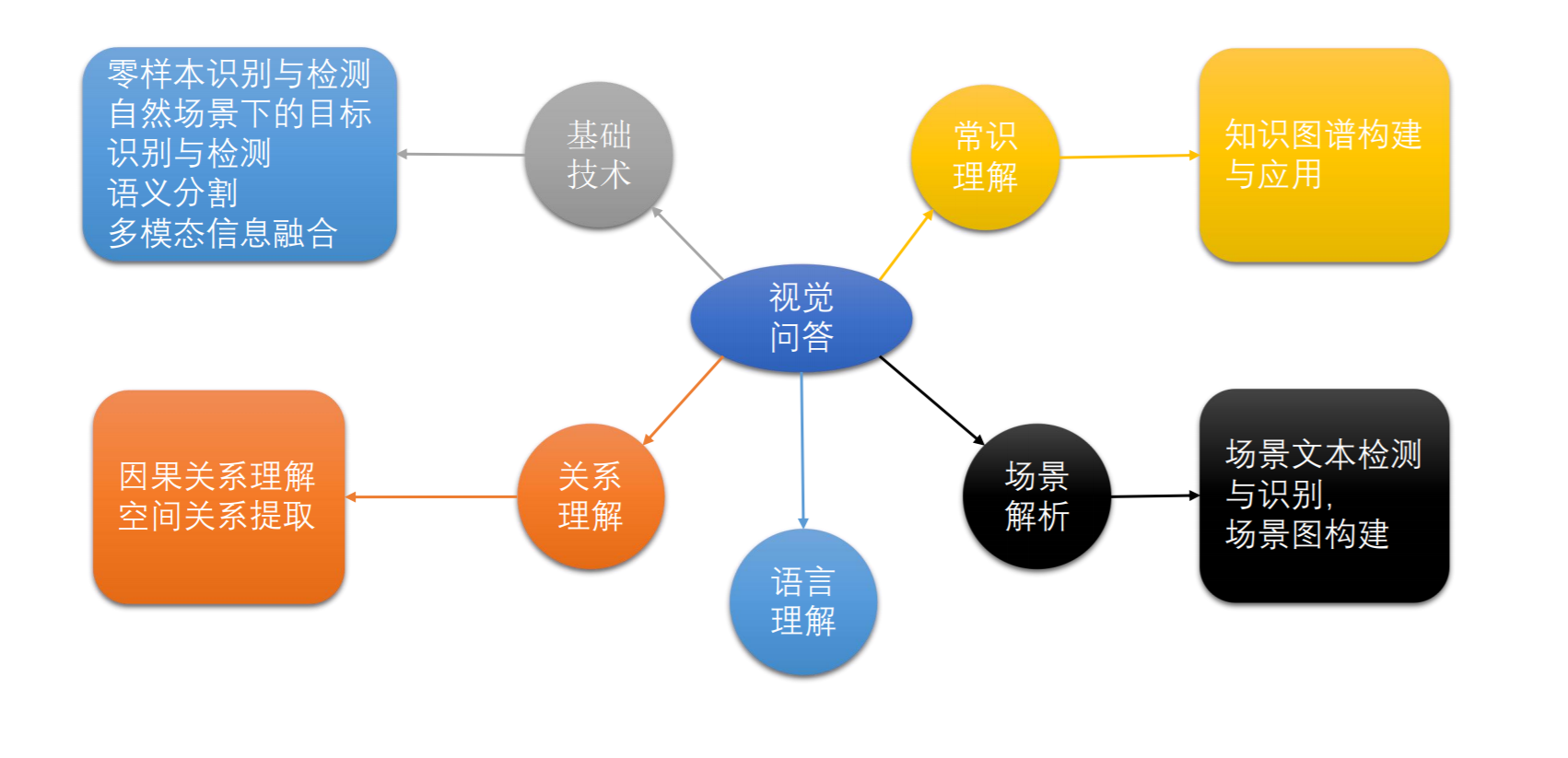
基于注意力的VQA方法
- 现在的注意力机制有一个很大的缺陷在于处理数字问题的时候存在局限性,这其实很容易理解.回到提出注意力机制的出发点,就是定位到图像中的某一块区域,这个区域作为整个图像的特征.我们画张图示意当前基于注意力的模型每个部分在做什么.这样的话问题就来了.假设当模型获得一个问题 What is on the grass?模型期望可以定位到草地上的目标,比如羊,那么选取羊的特征送入到分类器,分类器训练良好,所以它给出了答案sheep.但是假如对于同一张图片,问题变成了How many sheeps are on the grass?我们同样假设模型理解了问题,并且这时候定位到了所有羊,那么这些羊的特征经过一个加权求和后得到新的特征,输入到分类器,分类器顺利输出正确答案3.这时候事情就变得诡异了,因为羊的特征比较类似,那么分类器理应输出的是羊,为什么是3呢?为了描述模型更不合理的地方,我们假设把所有的羊用牛替换,模型同样定位到了所有的牛,然后把他们的组合后的特征输入给分类器,凭什么期望模型可以输出3呢?
可以很明显地看出基于注意力的模型是有局限的,它可以很好地回答yes/no和分类的问题,但是对于计数问题无能为力,可以说它几乎就是靠记忆,因为它本质上无法理解图片.对于改进模型,这是一个突破口,如何加强模型的计数能力.

视觉问答实现技术随想
视觉问答作为一个人工智能的高级任务,具有重大的意义,如果可以解决视觉问答的难题,基本上标志着实现了强人工智能.
实现视觉问答需要计算机具备的能力:
- 对语言真正的理解
- 对图像实现真正的理解
- 语言和图像的融合理解(我认为,对图像的理解和对语言的理解是分不开的,这两者一定是统一的)
现在流行的方案
- 注意力机制(定位)
- 多模态融合(交互)
基本架构:
 从逻辑上来讲,这种方法是不可能真正解决视觉问答这个任务,因为它只能输出固定的答案,而现实世界中的问题和答案则要复杂得多.考虑一个很简单的任务,给定一张桌子上放着一个苹果的图片,问题是放在桌子上的是什么?这个时候基于注意力机制的方法都希望模型能达到这个效果,通过问题定位到苹果,让苹果的特征占据更大的注意力,理想情况是1,然后再输入分类器.但是它的分类器不是专门的分类模型,所以分类效果不见得好,更好的方法是将苹果特征输入到一个在image net上预训练过的分类器去进行分类.但是由于现有方法的限制,它不能实现这一点.
从逻辑上来讲,这种方法是不可能真正解决视觉问答这个任务,因为它只能输出固定的答案,而现实世界中的问题和答案则要复杂得多.考虑一个很简单的任务,给定一张桌子上放着一个苹果的图片,问题是放在桌子上的是什么?这个时候基于注意力机制的方法都希望模型能达到这个效果,通过问题定位到苹果,让苹果的特征占据更大的注意力,理想情况是1,然后再输入分类器.但是它的分类器不是专门的分类模型,所以分类效果不见得好,更好的方法是将苹果特征输入到一个在image net上预训练过的分类器去进行分类.但是由于现有方法的限制,它不能实现这一点.
所以从本质上来讲,它还是在进行模式识别,进行数据拟合,和智能扯不上关系.我们再来看一个例子:
在现有的技术框架下实现的模型:
问题1:桌面上有几个苹果? 模型输出:2(假设分类类别里存在2,而且模型分类正确)
问题2:桌面上的是什么? 模型输出:橙子(分类类别里没有苹果)
模型这样的表现是不是很诡异,它甚至没有正确识别到苹果,怎么可以回答有几个苹果这种问题?模型理解了图片吗?可能是的,因为它正确计数了;但是模型真的理解吗?它甚至连桌上的是苹果都不知道.这个问题其实是比较严重的,除了在固定数据集上自娱自乐,基本没什么实用价值.
人类为什么是唯一的智能生物?
语言是人类具有智慧的重要一环,语言会帮助我们进行思考,如果没有语言,或者语言的词汇量太少,我们的思考就会被限制.这个语言无所谓是哪个国家的语言,也可以是数学语言,只要能表示对应的意思,它是经过高度抽象化过的,所以它具有很强的泛化性和适应性.而我们的思维也会受语言的影响.
现在假想一种情况,我生活在一个社会,然后没有学会吃这个词,也没有学会对应的这个意思的词,我所知道有苹果和他,那现在有下面这样一个场景,有个人问我,这个人在干什么? 我只能回答 他 ,苹果. 他,苹果。因为我不知道吃是什么概念,所以我回答不了这个问题.这种时候我就显得很弱智。
接下来,换一种情况,在我生活的社会,所有的吃和切的意思完全调换,也就是上面这张图我来描述的话就变成了切苹果,而原来的切苹果会变成吃苹果。那其实于我而言没有什么影响,因为我的切和你们的“吃”代表的是同一个意思。于我而言重要的是学习到了吃这个词代表的抽象的概念,这个概念通常以视觉的形式表现出来,我在学习的过程中是将吃所展现的画面结合我原来学到的一些概念进行交融来理解的,吃只是一个记号,方便地记录这么一个概念,让我之后需要这个概念时可以更方便地调用。由于吃这个概念和人以及苹果无关,所以当我面临另外的情况时,例如吃西瓜、吃橘子,我依然可以正确地表述,即使遇到吃某种不认识的食物x,我还是可以描述出人在吃某种我不知道的食物,即使换掉主体,把人换成狗,或者某种不认识的动物,我还是可以描述出某种动物在吃苹果。
现在回到神经网络模型学习上,按照现有的思路,假设我们训练一模型,希望模型学会辨别人在吃苹果这样一个场景,我们会给它输入一些类似上图的人在吃苹果的图片,作为正样本 ,同时给它一些负样本,经过训练之后,我们使用模型进行推理,如果模型输出为1,则表示人在吃样本。这个任务应该是很简单的,模型的准确率可以很高。但是模型真的学会了吃这个概念吗?如果给它一张狗吃苹果的照片,它能正确预测吗?直观上来看,模型的参数是固定的,它会对人的特征产生很强的响应,但是狗的特征和人的特征完全不同,它经过模型之后产生的响应肯定和之前是完全不同的。现在来让模型的实力更进一步,我们给模型提供 人吃苹果,狗吃苹果,人吃梨,狗吃梨这四种类别的图片和没有东西在吃东西的图片,标签用一个5维的one-hot编码表示。经过训练之后,模型可以对这些情况进行很好的分类。但是这明显不满足我们的要求,机器还是很笨。我们不可能穷尽所有的情况并采集图片让模型进行学习。一个很关键的原因在于机器学习的过程中把人吃苹果、狗吃苹果作为一个整体,这样就造成了组合爆炸。
现在的视觉问答模型技术体系基本都是处于这种阶段,尽管随着多年的发展,在特征提取和特征融合上采用了一些新方法,但是它的标签还是以整体的形式展现的,例如on grass,on field,答案是无法穷尽的。
 为了让模型具有类人的智能,那么模型需要具备一些基础的能力,目标识别,目标检测等,还要学到一些高级的概念,对关系(空间和语义)的建模能力。这里存在几个难点,第一个是仅仅使用CNN无法单独对关系建模,这是由CNN的结构决定的,它的结构导致它的归纳偏置是确定的,而这种归纳偏置并不适合对关系建模,所以需要另寻它途。图结构是一种很好的对关系建模的方式,顶点表示实物,边表示实物间的关系,非常清晰明了。第二个难点是高级的概念学习,在上面的一段提到过概念的学习通常与视觉信息和语言都是分不开的。抽象的视觉概念难以理解,但是当它同时也有一个具体的名词表示时,它就变得容易理解了。对于概念的学习是非常重要的,但是如何同时利用语言和视觉去进行概念学习,我也不知道,只是隐隐有这种感觉。
为了让模型具有类人的智能,那么模型需要具备一些基础的能力,目标识别,目标检测等,还要学到一些高级的概念,对关系(空间和语义)的建模能力。这里存在几个难点,第一个是仅仅使用CNN无法单独对关系建模,这是由CNN的结构决定的,它的结构导致它的归纳偏置是确定的,而这种归纳偏置并不适合对关系建模,所以需要另寻它途。图结构是一种很好的对关系建模的方式,顶点表示实物,边表示实物间的关系,非常清晰明了。第二个难点是高级的概念学习,在上面的一段提到过概念的学习通常与视觉信息和语言都是分不开的。抽象的视觉概念难以理解,但是当它同时也有一个具体的名词表示时,它就变得容易理解了。对于概念的学习是非常重要的,但是如何同时利用语言和视觉去进行概念学习,我也不知道,只是隐隐有这种感觉。
怎么解决视觉问答任务?
视觉问答作为一个既大且难的任务,应该由多个模块共同协作完成的,现在的端到端的VQA模型完全就是空中楼阁,在自娱自乐。从现实的角度来讲,找工作,它和现实比较脱节,缺乏技术含量又不实用,一旦这个任务不再火了,那么你如果做这个方向的,没什么对口的工作岗位。做底层技术的识别检测等你不会;做高层应用的需要眼界开阔,涉猎广泛,底子好,和你做什么研究方向关系不大;做特定应用的,现在的这种视觉问答根本不实用。
总结就是视觉问答这个任务非常好,如果我们把他作为一个需要综合应用其他技术的高级任务任务,它需要你对神经网络和其他技术的深入了解以及综合运用能力,这是我当时想把自己和实验室的方向转到视觉问答(视觉理解)的原因,因为有很多东西可以做,而且现在距离真的解决这个问题还有一段比较长的路要走。但是如果按照现在那种基于注意力的方法去做,那除了可以发论文以外没什么用处,可做的工作也不多。对于想做VQA的同学来说,我的建议是从完成视觉问答(视觉理解)需要的一些技术选择一个或多个方向去做,这样既能提高自己的技术水平,至少让自己有一技之长,方便找工作,同时也对实验室的长期目标有帮助。我在投完11月的会议后也会转到底层技术去做。
在上段中有说到,图结构是对关系建模建模的一种很好的结构,图网络是一个非常有前景的方向,它可以适应更多的场景,更多的任务需求。CNN可以完成基础的视觉感知任务,对于应用感知能力的高级应用,CNN是无能为力的,但是图网络也许可以,它可以链接多个完全不一样的实体,因为有关系,个体才有了更多的价值,单独存在的个体在某种程度上是不存在价值的。关于图网络的内容,有必要的话我会在后面分享,有兴趣的可以找我交流。
视觉问答中的attention机制真的有效吗
attention机制在视觉问答任务中取得不错的成绩,最近效果最好的模型几乎都是基于attention机制的,但是attention真的有效吗?还是因为一些其他的原因,比如信息的流动变得更加复杂了才让模型开始生效呢?
实验
起因是我想建立36个特征之间的联系,所以我希望让模型学习一个线性变换 为线性变换之后得到的新的36个特征.具体实现中,我们不小心保留了attention层.在bottom-up and top-down方法中,我对视觉特征进行了进一步的处理,在输入到attention层之前,使用一个36*36的全连接层对视觉特征的转置进行了线性变换,再转置回去,经过转置之后这36个特征其实不再是其对应区域的视觉特征表示了,而是由所有区域的特征加权求和之后得到,但是我们发现,模型的精度并没有降多少,但是这里attention其实是失效的.所以这只能得出两种结论:
为线性变换之后得到的新的36个特征.具体实现中,我们不小心保留了attention层.在bottom-up and top-down方法中,我对视觉特征进行了进一步的处理,在输入到attention层之前,使用一个36*36的全连接层对视觉特征的转置进行了线性变换,再转置回去,经过转置之后这36个特征其实不再是其对应区域的视觉特征表示了,而是由所有区域的特征加权求和之后得到,但是我们发现,模型的精度并没有降多少,但是这里attention其实是失效的.所以这只能得出两种结论:
- 这个线性变换层改善了模型的效果,因为其某种意义上和self-attention起到的是一样的效果.这个改善的精度抵消了attention失效带来的精度下降
注:其实好像这个注意力机制是有效的,因为当我把视觉特征的线性变换放到attention层之后,模型的精度没有下降,而是增加了.
- 基于注意力机制的视觉问答模型学到了什么?
- 问题:模型是否学到了和语义和对象的匹配?
- 验证:对于一个问题,模型似乎学到了要正确回答问题需要关注的对象,而且此对象和语义中需要关注的对象是对应的,但是我们想知道换一句话看看模型是否还能关注到对应的对象。就是把fire hydrant放入另一句话中,可视化注意力权重。
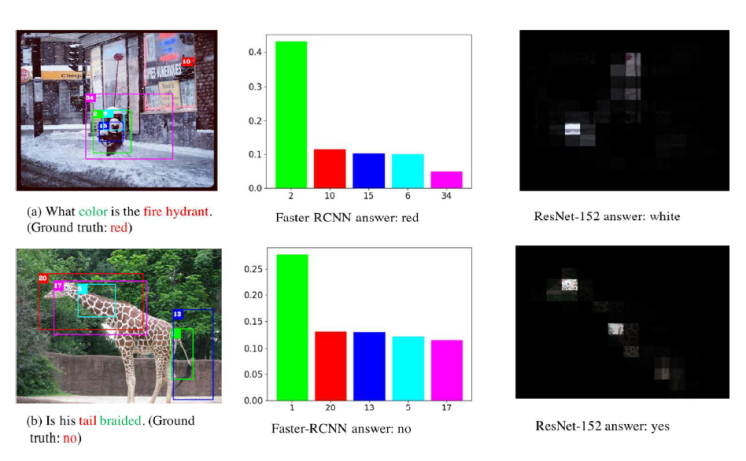
- 方法:
- 主要目标不变,修改问题,查看整个问题对视觉特征的注意力权重
- 问题不变,查看每一个词对视觉特征的注意力权重
- 更多:如果在上述的实验中我们发现模型确实学到了语义和目标的对应关系,证明了机器的学习其实具有了一定的逻辑性,类似于人类。按照人类的学习过程来讲,我们对于视觉的认知和语言的学习是不能分离的,没有语言的话视觉信息是毫无意义的,因为我们没有合适的符号来辅助我们思考,所以语言是人类思想的基础。
基于注意力机制的视觉问答中模型学到了什么
现在我们通常是使用基于Faster-RCNN预处理的图像特征,尽管我们并没有告诉模型任何关于这些特征的信息(类别信息),但是我们认为,在经过大量的训练之后,模型其实学到了语言和视觉信息之间的一些关系,例如它学会了用语言去定义一个目标(不一定是完整的目标,但是是faster-rcnn提出的一个检测框代表的对象),尽管这个目标的定义可能和我们人类的定义不同。这个可以从基于注意力机制的模型中看出来,当模型正确回答一个问题的时候,它的注意力会更集中在与问题提及的主要视觉目标上。从一种新的角度看待,注意力模型之所以有效,可能是因为我们告诉这个模型,你需要学习用语言信息去匹配一个视觉目标,而模型确实能做到这一点,为了让你能更高效地去匹配一个具体的目标,我们将每一个目标的特征独立给你。这就是为什么基于faster-rcnn的目标视觉特征在VQA任务中的效果远远好于图像级别的特征的原因,模型确实有这种能力。但是对于图像级别的特征,模型需要用语言去匹配区域,难度变得很大。我们看下图可以看到不同视觉特征下,同一种模型训练之后的效果差别。图来自Wei Li et al.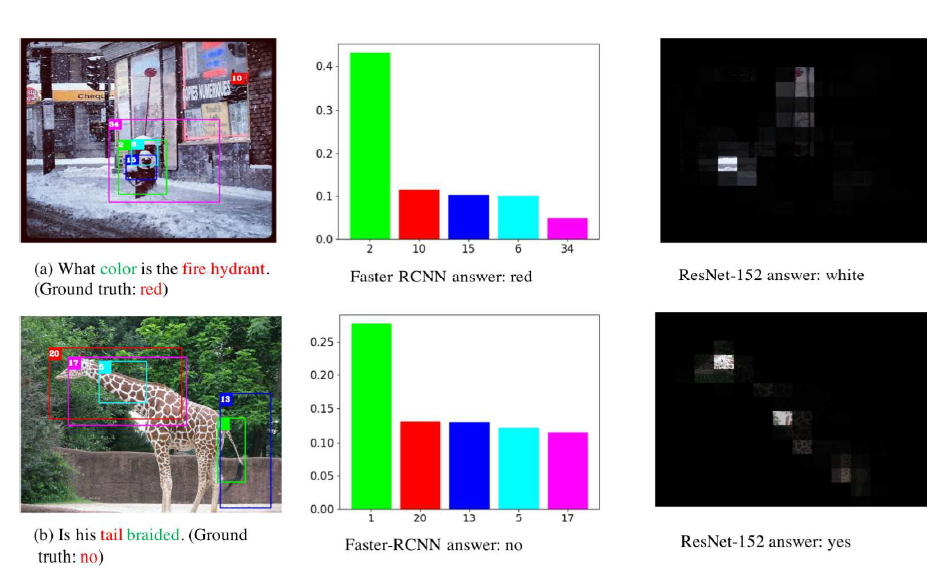
但是我们知道,即使我们使用的是faster-rcnn特征,它提供了大多数检测框的位置信息,但是在很多的VQA模型中并没有使用这些位置信息,那对于一个涉及到目标之间的空间关系的问题,那些模型理论上是不能正确回答这些问题的,即使它们注意到了和问题对应的目标,但是它对目标的空间关系一无所知,这是一个可以改进的地方。MUREL这篇文章就注意到了这一点,要对目标之间的关系进行建模,想法非常简单,但是效果非常好,而且reviewer也很认可,但是肯定还有更好的方法可以实现对目标相互之间的空间进行建模并加以利用,有一个不成熟的想法是利用所有目标的位置信息和注意力权重来重构图片(怎么重构是个问题,因为这些目标特征本身已经丧失了空间信息),但是可能这么做不如仅仅对检测框坐标进行建模来得有效,因为并没有获得更多的信息,也没有让信息的流动性变得更好。
关系建模
由于大部分基于注意力模型并没有很好地关注目标的位置关系,所以会导致语义和视觉目标匹配不准确,也就是注意力图不准确,这会影响分类器的性能,尤其是一些关于多目标的问题,模型准确率就会迅速下降。也有一些模型是对位置关系建模,使用双线性融合的方法,但是没有使用注意力机制,例如下图。这个方法最优秀的地方在于在编码位置信息之前进行了早期融合,导致在对目标关系建模的时候,语言信息也参与了这个建模的过程,增强了语言和视觉的匹配度,最终学到的向量会包含所有信息,所以它不需要使用注意力机制。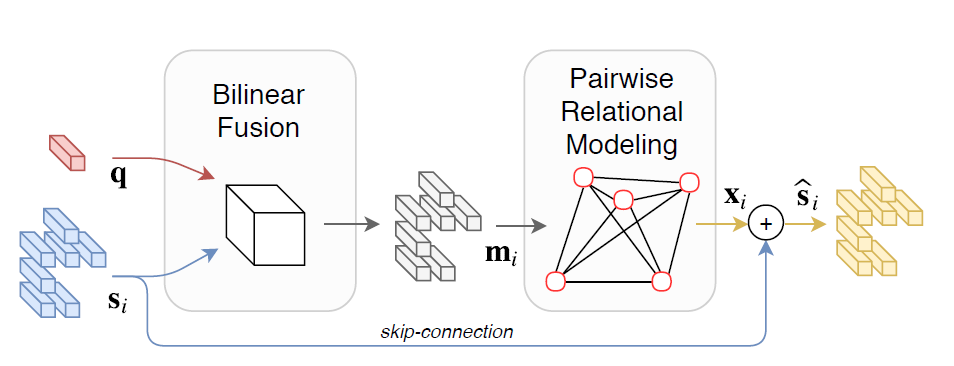
图网络是关系建模的一把好手,尤其是结构不定的关系建模,确实有很多方案是用图模型来解决VQA的,所以是否可以将注意力和图模型结合起来做一个模型呢?(因为对图模型还不了解,所以不能确定是否已有方案,但是我也需要想想如何整合这两种模型)
计数问题
在当前的模型框架下,计数问题是无解的,因为在软注意力机制方法中,会对注意力权重进行归一化,模型最终会对目标的特征进行加权叠加,毫无疑问会丧失个数的信息。举个极端点的例子,假设对于一个计数问题,图片中有三个特征一模一样的目标,且注意力图非常精确地关注到了这些目标,赋予相同的权重1/3,那么输入到分类器的是一个加权求和的特征,这时候我们修改一下假设条件,图片中有4个目标,且特征和上述提到的一模一样,经过加权求和后得到的特征竟然是和3个目标的特征加权求和后一模一样,分类器无法分类,只能转而寻求数据集中的偏置。无论如何改进信息的交互过程,都无法解决,这是软注意力模型天生存在的缺陷。需要转而寻求其他的方法。

若有收获,就点个赞吧
0 人点赞
