为什么要学习Kafka?
互联网蓬勃发展的这些年涌现出了很多令人眼花缭乱的新技术。以我个人的浅见,截止到2019 年,当下互联网行业最火的技术当属 ABC 了,即所谓的 AI 人工智能、BigData 大数据和 Cloud 云计算云平台。
作为工程师或架构师,你在实际工作过程中一定参与到了很多大数据业务系统的构建。由于这些系统都是为公司业务服务的,所以通常来说它们仅仅是执行一些常规的业务逻辑,因此它们不能算是计算密集型应用,相反更应该是数据密集型的。
对于数据密集型应用来说,如何应对数据量激增、数据复杂度增加以及数据变化速率变快,是彰显大数据工程师、架构师功力的最有效表征。
我们欣喜地发现 Kafka 在帮助你应对这些问题方面能起到非常好的效果。就拿数据量激增来说,Kafka 能够有效隔**离上下游业务,将上游突增的流量缓存起来,以平滑的方式传导到下游子系统中,避免了流量的不规则冲
击**。
由此可见,如果你是一名大数据从业人员,熟练掌握 Kafka 是非常必要的一项技能。刚刚所举的例子仅仅是 Kafka 助力业务的一个场景罢了。事实上,Kafka 有着非常广阔的应用场景。不谦虚地说,目前 Apache Kafka 被认为是整个消息引擎领域的执牛耳者,仅凭这一点就值得我们好好学习一下它。另外,从学习技术的角度而言,Kafka 也是很有亮点的。
我们仅需要学习一套框架就能在实际业务系统中实现消息引擎应用、应用程序集成、分布式存储构建,甚至是流处理应用的开发与部署,听起来还是很超值的吧。
不仅如此,再给你看一个数据。援引美国 2019 年 Dice 技术薪资报告中的数据,在 10 大薪资最高的技术技能中,掌握 Kafka 以平均每年 12.8 万美元排名第二!排名第一位的是13.2 万美元 / 年的 Go 语言。
2019 年两会上再一次提到了要深化大数据、人工智能等研发应用,而 Kafka 无论是作为消息引擎还是实时流处理平台,都能在大数据工程领域发挥重要的作用。
总之 Kafka 是个利器,值得一试!既然知道了为什么要学 Kafka,那我们就要行动起来,把它学透,而学透 Kafka 有什么路径吗?
如果你是一名软件开发工程师的话,掌握 Kafka 的第一步就是要根据你掌握的编程语言去寻找对应的 Kafka 客户端。当前 Kafka 最重要的两大客户端是 Java 客户端和 libkafka 客户端,它们更新和维护的速度很快,非常适合你持续花时间投入。一旦确定了要使用的客户端,马上去官网上学习一下代码示例,如果能够正确编译和运行这些样例,你就能轻松地驾驭客户端了。
下一步你可以尝试修改样例代码尝试去理解并使用其他的 API,之后观测你修改的结果。如果这些都没有难倒你,你可以自己编写一个小型项目来验证下学习成果,然后就是改善和提升客户端的可靠性和性能了。到了这一步,你可以熟读一遍 Kafka 官网文档,确保你理解了那些可能影响可靠性和性能的参数。
最后是学习 Kafka 的高级功能,比如流处理应用开发。流处理 API 不仅能够生产和消费消息,还能执行高级的流式处理操作,比如时间窗口聚合、流处理连接等。
如果你是系统管理员或运维工程师,那么相应的学习目标应该是学习搭建及管理 Kafka 线上环境。如何根据实际业务需求评估、搭建生产线上环境将是你主要的学习目标。**
另外对生产环境的监控也是重中之重的工作,Kafka 提供了超多的 JMX 监控指标,你可以选择任意你熟知的框架进行监控。有了监控数据,作为系统运维管理员的你,势必要观测真实业务负载下的 Kafka 集群表现。之后如何利用已有的监控指标来找出系统瓶颈,然后提升整个系统的吞吐量,这也是最能体现你工作价值的地方。
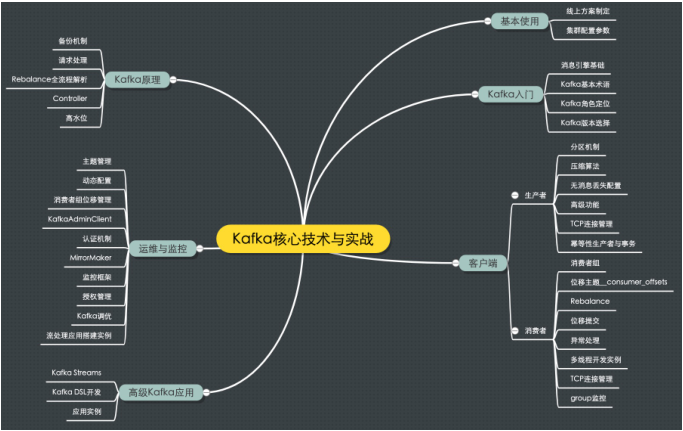
下面是我特意为专栏画的一张思维导图,可以帮你迅速了解这个专栏的知识结构体系是什么
样的。专栏大致从六个方面展开,包括 Kafka 入门、Kafka 的基本使用、客户端详解、Kafka 原理介绍、Kafka 运维与监控以及高级 Kafka 应用。

若有收获,就点个赞吧
0 人点赞
