设存储元素ai的结点为q,要实现将结点q删除单链表的操作,
其实就是将它的前继结点的指针绕过,指向它的后继结点即可,如图所示。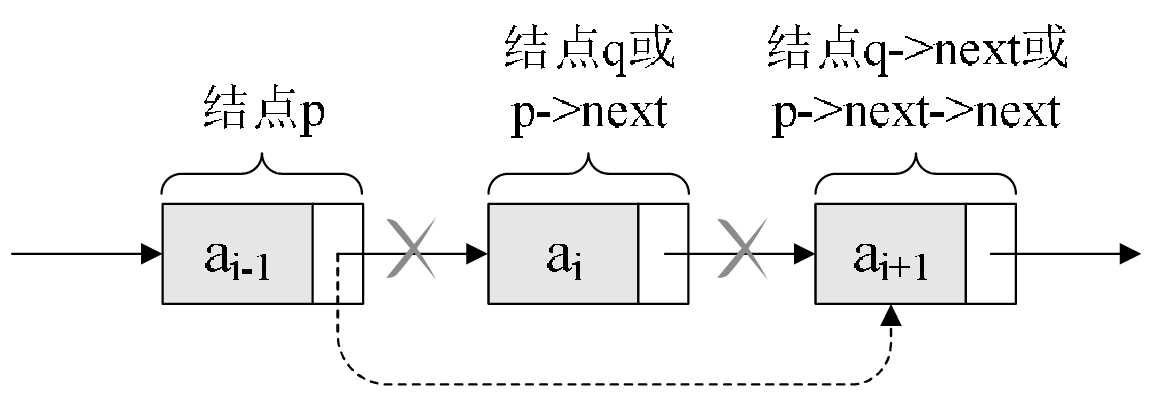
我们所要做的,实际上就一步,p->next=p->next->next,用q来取代p->next,即:
q = p->next;//p的后继结点换名为q结点p->next=q->next;//p结点指向q结点的后继结点,即是p结点指向p结点的后继后继结点
解读这两句代码,
也就是说把p的后继结点改成p的后继的后继结点。
单链表第i个数据删除结点的算法思路:
- 声明一指针p指向链表头结点,初始化j从1开始;
- 当j<i时,就遍历链表,让p的指针向后移动,不断指向下一个结点,j累加1;
- 若到链表末尾p为空,则说明第i个结点不存在;
- 否则查找成功,将欲删除的结点p->next赋值给q;
- 单链表的删除标准语句p->next=q->next;
- 将q结点中的数据赋值给e,作为返回;
- 释放q结点;
- 返回成功。
实现代码算法如下:
/* 初始条件:顺序线性表L已存在,1 ≤ i ≤ ListLength(L) *//* 操作结果:删除L的第i个结点,并用e返回其值,L的长度减1 */Status ListDelete(LinkList *L, int i, ElemType *e){int j;LinkList p, q;//typedef struct Node *LinkList;//所以p是结点类型指针p = *L;//j = 1;/* 遍历寻找第i-1个结点 */while (p->next && j < i)//p->next是首结点的地址, 防止链表为空,空无可删{p = p->next;++j;}/* 第i个结点不存在 */if (!(p->next) || j > i)return ERROR;//换名q = p->next;/* 将q的后继赋值给p的后继 */p->next = q->next;/* 将q结点中的数据给e */*e = q->data;/* 让系统回收此结点,释放内存 */free(q);return OK;}
这段算法代码里,我们又用到了另一个C语言的标准函数free。它的作用就是让系统回收一个Node结点,释放内存。
分析一下刚才我们讲解的单链表插入和删除算法,我们发现,它们其实都是由两部分组成:
- 第一部分就是遍历查找第i个结点;
- 第二部分就是插入和删除结点。
从整个算法来说,我们很容易推导出:它们的时间复杂度都是O(n)。
- 如果在我们不知道第i个结点的指针位置,单链表数据结构在插入和删除操作上,与线性表的顺序存储结构是没有太大优势的。
但如果,我们希望从第i个位置,插入10个结点,对于顺序存储结构意味着,每一次插入都需要移动n-i个结点,每次都是O(n)。
而单链表,我们只需要在第一次时,找到第i个位置的指针,此时为O(n),接下来只是简单地通过赋值移动指针而已,时间复杂度都是O(1)。
显然,对于插入或删除数据越频繁的操作,单链表的效率优势就越是明显。

若有收获,就点个赞吧
0 人点赞
