Ensembles of Multiple Models and Architectures(EMMA) for Robust Brain Tumour Segmentation 脑肿瘤分割鲁棒的(多种模型和体系结构集成) MICCAL2017 被引:240 https://arxiv.org/abs/1711.01468 三个模型(DeepMedic、FCN、u-net)的代码开源,但是这个方法的整体不开源
摘要
深度学习方法,如卷积神经网络,在诸如密集、语义分割等具有挑战性的任务上一直优于以前的方法。然而,不同的网络表现不同,其行为很大程度上受架构选择和训练设置的影响。本文探讨了多种模型和体系结构的集成(EMMA),通过对各种方法的预测进行聚合来实现健壮性能。该方法减少了单个模型元参数的影响,以及对特定数据库过度拟合配置的风险。EMMA可以被视为一个公正的、通用的深度学习模型,它有出色的表现,在2017年BRATS大赛中获得了50多支参赛队伍中的第一名。
1介绍
脑瘤是最致命的[1]癌症之一。在最初产生于大脑的肿瘤中,胶质瘤是最常见的[2]。它们起源于胶质瘤细胞,根据其侵袭性,它们被广泛地分为高级别和低级别胶质瘤[3]。高级别胶质瘤(HGG)发展迅速,侵袭性强,形成异常血管和坏死核心,并伴有周围水肿和血肿。它们是恶性的,死亡率高,即使在治疗[3]后平均存活率也不到2年。低级别胶质瘤(LGG)可以是良性的,也可以是恶性的,生长速度较慢,但它们可能会复发并进化为HGG,因此治疗是有必要的。治疗方面,病人接受放射治疗、化疗及手术治疗。
首先是为了诊断和监测肿瘤的进展,然后是为了制定治疗计划,然后是评估治疗的效果,使用了各种神经成像方案。磁共振成像(MRI)广泛应用于临床常规和研究研究。它通过允许估计其子成分[2]的范围、位置和调查来促进肿瘤分析。然而,这需要对肿瘤进行精确的描绘,这证明具有挑战性,因为其复杂的结构和外观,磁共振图像的3D性质和多个磁共振序列,需要同时咨询,以进行明智的判断。这些因素使得人工描述非常耗时,而且会受到评分者之间和评分者内部[4]变化的影响。
自动分割系统旨在提供一个目标和可扩展的解决方案。早期的代表性研究有基于atlas的离群值检测方法[5]和关节分割-配准框架,通常以肿瘤生长模型为指导[6,7,8]。在过去的几年里,机器学习方法发展迅速,其中随机森林是最成功的方法之一[9,10]。
最近,卷积神经网络(CNN)在脑肿瘤分割方面表现出了非常有前途的结果,因而受到了欢迎[11,12,13]。人们提出了各种各样的CNN架构,每一种都有不同的优缺点。此外,网络有大量的元参数。系统的多种配置选择不仅会影响性能,还会影响其行为(图1)。例如,不同的模型在不同类型的预处理下可能会表现得更好。因此,当调查他们在特定任务中的行为时,结果可能是有偏见的。最后,在给定数据库上高度优化的配置可能过于适合,而不能泛化到其他数据或任务。
在这项工作中,我们推动构建一个更可靠和客观的深度学习模型。我们汇集了各种CNN架构,以不同的方式配置和训练,以便在它们之间引入高方差。通过将它们组合起来,我们构建了一个多模型和架构的集成(EMMA),目的是平均掉差异,并使用它来实现模型和配置特定的行为。我们的方法导致:(1)系统对独立组件的不可预测故障具有鲁棒性;(2)通过无偏行为的通用深度学习模型实现客观分析;(3)引入了集成的新视角以提高客观性。这与普通的集成形成了鲜明的对比,在普通的集成中,单个模型被训练成小的变化,比如初始的种子,这使得集成被主要的架构选择所偏向。作为这项努力的第一个里程碑,我们在2017年脑瘤分割(BRATS)挑战中评估了EMMA。在最后的测试阶段,我们的方法在50多支参赛队伍中获得了第一名。这表明了该方法的可靠性,并为进一步的分析奠定了基础。
2背景:模型偏差,方差和集成
前馈神经网络已被证明能够逼近任何函数[14]。因此,它们是零偏差的模型,可能没有系统误差。然而,它们并不是万灵药。如果不进行正则化,它们可能会对训练数据中的噪声进行过拟合,这将导致在调用它们进行泛化时出现错误。再加上优化过程的随机性和多个局部极小值,这将导致不同实例之间出现不可预测的不一致错误。这构成了具有高方差的模型。正则化减少了方差但增加了偏差,如偏差/方差困境[15]所示。正则化可以是显式的,比如权重衰减,防止网络学习罕见的噪声模式;也可以是隐式的,比如CNN核的局部连通性,然而,这并不允许模型学习比其接收场更大的模式。因此,架构和配置的选择会引入偏差,改变网络的行为。
解决偏差/方差困境的一种方法是集成。通过组合多个模型,ensemble试图创建一个具有低方差的性能更高的模型。最流行的组合规则是平均,它对单例[16]的不一致错误不敏感。通常,用不同的初始权值或多个最终局部极小值训练的网络实例被集成起来,其中大多数修正不规则误差。直观地说,只有不一致的误差才能被平均出来。缺乏一致的故障可以解释为统计上的独立性。因此,已经开发了解除实例关联的方法。最流行的是bagging[17],通常用于随机森林。它使用自举抽样从不同的数据子集中学习相关性较低的实例。
上面的工作经常讨论集成作为一种提高性能的手段。[18]接近不可靠范围的高差异。他们将集成作为n版本编程的一种,它提倡通过冗余来实现可靠性。当产生一个程序的n个版本时,版本可能独立失败,但通过多数投票,它们表现得像一个可靠的系统。他们对可靠性形成了直观的要求:a)目标功能要被整体覆盖,b)大多数都要正确。这反过来又提倡组件的多样性、独立性和整体质量。
生物医学应用的可靠性是关键的,高方差会阻碍神经网络的使用。为此,我们开始研究不同集成体的鲁棒性。从上面的工作转移,我们引入了集成的另一个角度:创建一个目标的、构型不变的模型来促进目标分析。
3多个模型和架构的集合
在最近的文献中,各种CNN架构都显示出了很有前途的结果。就架构而言,它们通常在深度、过滤器数量和处理多尺度上下文的方式上有所不同。这样的架构选择会使模型行为产生偏差。例如,具有大接收域的模型可能显示出改进的本地化能力,但与强调局部信息的模型相比,对精细纹理的敏感性较低。处理类不平衡的策略是另一个与性能相关的参数。常用的训练策略是用类加权抽样或类加权交叉熵进行训练。正如[13]中分析的那样,这些方法强烈地影响了模型对每一类的敏感性。此外,损失函数的选择也会影响结果。例如,我们观察到,通过结合(IoU)、骰子或类似损失[19]训练优化交叉口的网络,往往比使用交叉熵训练时给出更差的置信估计(图1)。最后,优化超参数的设置会强烈影响性能。实践者经常观察到,优化器的选择及其配置,例如学习速率计划,会决定分割的好坏。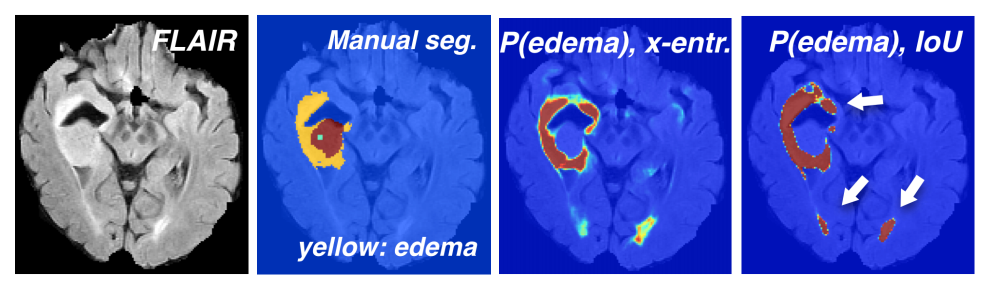
图1:从左到右:FLAIR; 手工注释的一个BRATS’17主题,其中黄色表示肿瘤核心周围的水肿; 经过交叉熵或IoU损失训练的CNN预测水肿的置信度。 尽管总体表现相似,但是使用IoU(或Dice,未显示)损失进行训练会改变CNN的行为,即使错误的情况下,也往往只会输出高度自信的预测
对这些元参数的敏感性是一个比手工优化配置更大的问题:
- 在一组训练数据上优化的配置设置可能会过拟合它们,在看不见的数据或另一个任务上不能很好地执行。这可以看作是另一个高模型方差的来源(第2节)。
- 通过偏见的行为的模型,它也偏见的发现的任何分析与它执行。
现在,我们对问题进行形式化,并按照如下方式将集合作为解决方案。 给定带有标签Y的训练数据X,我们需要学习生成过程P(y|x)。 这通常由模型 近似,该模型具有可训练参数θm,通过最小化的优化过程来学习:
近似,该模型具有可训练参数θm,通过最小化的优化过程来学习: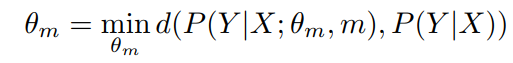
其中d是在训练数据给定的点上计算出的距离(由损失的类型定义),而m表示选择元参数。 尽管它限制(biases)学习的估计量,但它通常被忽略。 为了考虑到这一点,我们改为将m定义为元参数配置空间上的随机变量,并具有相应的先验P(m)。 为了学习一个不受m偏的P(y|x)模型,我们将其作用边缘化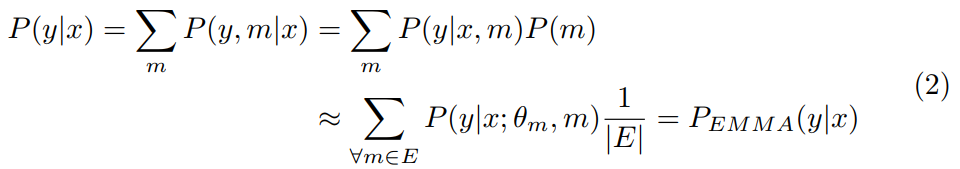
这里E是集合中的一组模型。 先验P(m)在m的子空间中被认为是均匀的,该子空间被E中的模型覆盖,而其他地方为零。 注意,通过考虑每个单独的模型 近似于m上的条件
近似于m上的条件 ,我们得出了平均的标准集合,而真实的后验近似于使效应边缘化的整体的m。 注意,通过设置狄拉克先验P(m)=δ(m),可以从上面推导由m配置的单个模型的情况。因此,集成relaxes了先前被忽略的强先验。
,我们得出了平均的标准集合,而真实的后验近似于使效应边缘化的整体的m。 注意,通过设置狄拉克先验P(m)=δ(m),可以从上面推导由m配置的单个模型的情况。因此,集成relaxes了先前被忽略的强先验。
以上公式从新的角度提出了平均集成:joint 的子空间上的边缘化提供了泛化,规范了(手动)优化过程,使m在给定的训练数据
的子空间上的边缘化提供了泛化,规范了(手动)优化过程,使m在给定的训练数据 上,从
上,从 过度拟合
过度拟合 的最小值(图2)
的最小值(图2)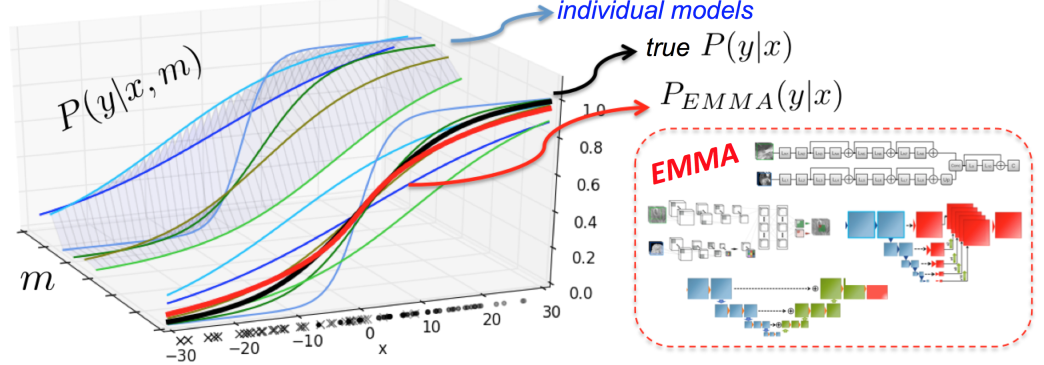
图2:我们的EMMA(红,集成了不同的网络),对各个模型配置m所注入的偏差进行平均,以更可靠地近似真实后验(黑),同时对次优配置具有鲁棒性。 左侧的后验者是从多个感知器获得的,经过训练后将以10和-10为中心的聚类分类为一个示例,训练标签中具有不同的损失,正则化和噪声。 它们的集成提供了可靠的估计。
此外,该过程导致P的更客观逼近 ,其中m的偏置作用已被边缘化。 exposed限制与第二节中提到的集合要求一致。 我们需要将m的子空间限制在相对高质量模型的区域中,并且需要用相对少量的模型进行覆盖,因此多样性是关键。
,其中m的偏置作用已被边缘化。 exposed限制与第二节中提到的集合要求一致。 我们需要将m的子空间限制在相对高质量模型的区域中,并且需要用相对少量的模型进行覆盖,因此多样性是关键。
在本节的其余部分中,我们将描述用于构建EMMA集合E的模型的主要属性,这些模型涵盖各种当代架构,并在不同的环境下进行配置和培训。
3.1 DeepMedic
模型描述:我们采用的第一个架构是DeepMedic,最初在[20,13]中提出。这是一个全3D,多尺度的CNN,设计的重点是高效处理3D图像。为此,它采用了并行路径作为输入下采样上下文,避免在全分辨率下进行大量的卷积,以保持计算成本低。虽然最初是为分割脑病变,它被发现在不同的任务上有希望,如分割胎盘[21],使它成为一个良好的组成部分的稳健集成。我们在EMMA中包括两个deepMedic模型。第一个是BRATS 2016[22]之前使用的残余版本,如图3所示。第二种是更广泛的变体,每一层的特征地图数量是原来的两倍。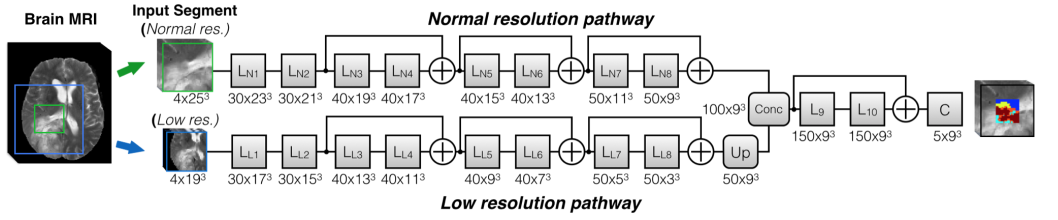
图3:我们在实验中使用了两个DeepMedics [13]。 描绘了两者中较小的一个,其中特征图的数量及其在每一层的尺寸以格式(Num×Size)描绘。 集成中使用的第二个模型更宽,每层的特征图数量增加了一倍。所有内核和特征图都是3D的(为简单起见没有描述)
训练细节:根据[13]中提出的方法,通过提取以50%概率集中于健康组织和50%概率集中于肿瘤的多尺度图像片段来训练模型。较宽的变体The wider variant分别针对两个比例尺在宽度34和22的较大输入上进行训练。它们用交叉熵损失进行训练,所有元参数均采用原始配置。
3.2 FCN
模型描述:我们在EMMA中集成了三个3D FCNs[23]。图4描绘了第一种结构的示意图。第二个FCN构造得更大,用一个带有两个卷积的剩余块替换每个卷积层。第三种方法也是基于残差的,但是少了一个降采样步骤。所有的层使用批归一化,ReLUs和零填充。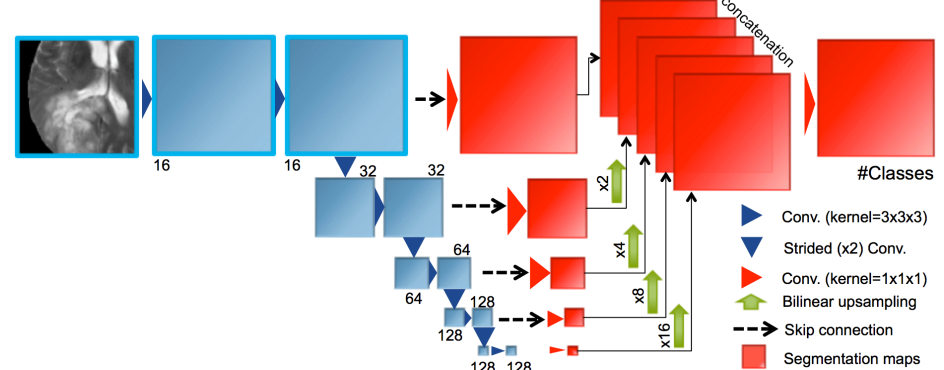
图4:EMMA中使用的FCN架构之一的示意图。 显示的是每层要素地图的数量。 所有内核和特征图都是3D的(为简单起见没有描述)
训练细节:我们为第一个体素(三维像素)绘制宽度为64的训练补丁,为基于残差的FCNs绘制宽度为80的训练补丁,每个标签获得训练补丁的概率相等。他们是用Adam训练的。第一个训练用IOU损失[19]来优化,而另外两个Dice被同样地使用。
3.3 U-Net
模型描述:我们采用了U-Net架构[24]的两个3D版本。第一个架构的主要元素如图5所示。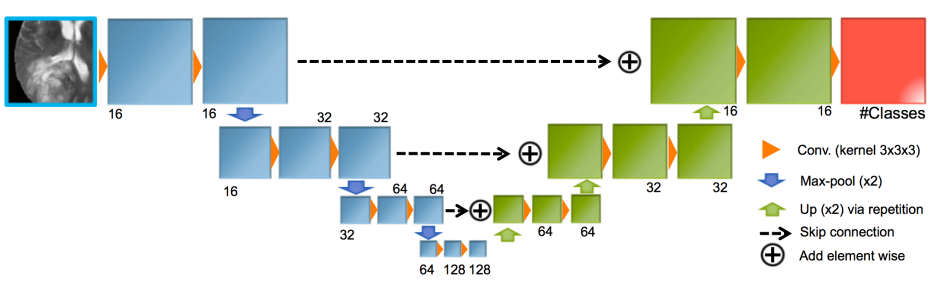
图5:在我们的实验中使用的改编Unet的示意图。 描述了每层特征地图的数量。 所有内核和特征图都是3D的(为简单起见并未进行描述)
在这个版本中,我们遵循[25]中提出的降低模型复杂性的策略,其中skip连接是通过网络的上采样部分中信号的求和来实现的,而不是最初使用的级联。第二个体系结构类似,但连接了skip连接和使用大步卷积代替最大池化。所有的层使用batch normalisation,ReLUs和零填充。
训练细节:使用大小为64×64×64的输入patch训练U-Nets。这些贴片仅从大脑内部采样,以相同的概率围绕着四个标签中的每个个体素进行采样。使用不同的优化、正则化和增强元参数,分别通过AdaDelta和Adam训练它们最小化交叉熵。
3.4集成
以上模型都是完全分开训练的。在测试时,每个模型分别分割一个不可见的图像,并输出其类置信度映射。据公式2,这些模型随后会被集成到EMMA。为此,每个类的集成置信度映射是通过计算每个体素的个体模型的平均置信度来创建的。EMMA的最终分割是通过给每个体素分配具有最高置信度的类来完成的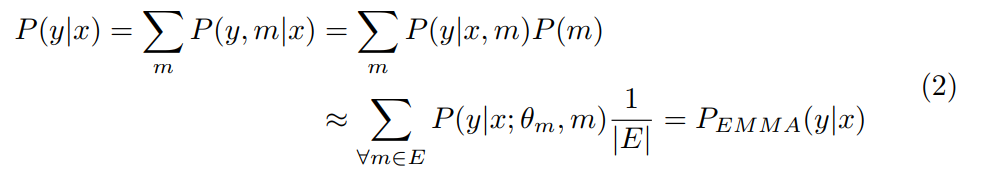
3.5实施细节
DeepMedic的原始实现用于相应的两个模型,以及默认的元参数,
可在https://biomedia.doc.ic.ac.uk/software/deepmedic/上公开获得。 FCN使用DLTK实施,DLTK是一个深度学习库,其重点是允许快速实施和实验的医学成像应用程序(https://github.com/DLTK/DLTK)。 最后,Unet的改编版将在https://gitlab.com/eferrante上发布。
4评估
4.1Material
我们的系统是根据2017年脑肿瘤分割挑战赛(BRATS)的数据进行评估的[4,26,27,28]。 训练集包括210例高级别神经胶质瘤(HGG)和75例低级别神经胶质瘤(LGG),并提供了手动分割方法。 分割包括以下肿瘤组织标记:1)坏死核心和非增强性肿瘤,2)水肿,4)增强核心。 不使用标签3。 验证集包括46个案例,包括HGG和LGG,但未透露等级。 隐藏验证集的参考细分,并通过允许多个提交的在线系统进行评估。 在比赛的测试阶段,向团队提供了146个案例的测试集,并且团队具有48小时的窗口,可以一次提交给系统。 为了进行评估,将3个预测标记合并为不同的整个肿瘤组(所有标记),核心(label1,4)和增强性肿瘤(label4)。 对于每个对象,可以使用四个MRI序列:FLAIR,T1,T1对比度增强(T1ce)和T2。 数据集由组织者进行了预处理,并以骷髅头skull-stripped的形式提供,注册到公共空间并重新采样为各向同性1mm3分辨率。 每个体积的尺寸为240×240×155。
4.2预处理:集成强度归一化方法
我们对强度归一化进行了三种不同版本的预处理实验:1)每种情况下每种模态的Z分数归一化,分别具有大脑强度的均值和标准差。 2)(1)后 偏置场校正。 3)偏置场校正,然后进行分段线性归一化[29],然后是(1)。 初步比较尚无定论。 相反,我们选择平均化使用EMMA进行标准化的效果。 训练了每个网络的三个实例,每个实例都使用经过不同规范化处理的数据。 将它们应用于相应处理的图像以进行推断,并将所有结果在EMMA中平均(图6)。
4.3结果
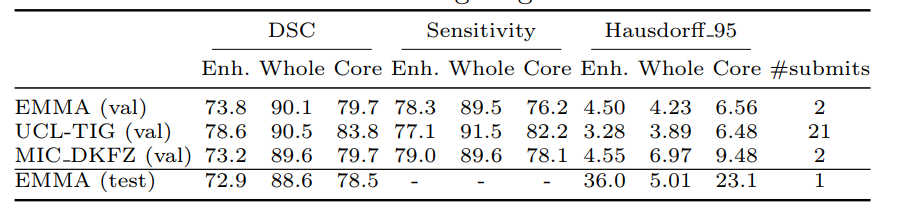
我们提供EMMA在表1上的BRATS 17挑战2的验证和测试集上获得的结果。我们的系统通过基于Dice分数(DSC)和Haussdorf距离在测试阶段获得总体最佳性能,从而赢得了竞争。 我们还将显示在测试阶段排在后两个位置的团队在验证集上获得的结果。
我们没有针对这些方法的测试阶段指标。 我们注意到EMMA在验证和测试集上达到了相似的性能水平,即使后者包含来自不同来源的数据也表明了该方法的鲁棒性。 相比之下,竞争方法非常适合验证集,但未能在测试集上保持相同的水平。这强调了对强大而可靠的系统进行研究的重要性。
表1:EMMA在BRATS 2017验证和测试集上的性能(提交ID biomedia1)。 我们的系统在比赛的测试阶段达到了最高的细分效果。 为了进行比较,我们显示了排名在下两个位置的团队在验证集上的表现。我们无法获得测试阶段其他团队的表现
5结论
事实证明,神经网络非常有效,但估计量不够完善,常常会产生无法预测的错误。 然而,生物医学应用对可靠性至关重要。 因此,我们首先专注于提高鲁棒性。 为了实现这一目标,我们引入了EMMA,这是一个广泛变化的CNN集合。 通过组合网络的异构集合,我们构建了一个对CNN组件的独立故障不敏感的模型,因此可以很好地概括(图7)。我们还介绍了客观整合的新观点。 通过整合配置选择所引入的有偏见的行为来边缘化EMMA,它是一种更适合于客观分析的模型。 即使单个网络具有简单的体系结构且未针对任务进行优化,EMMA仍在BRATS 2017竞赛的最后测试阶段赢得了50多个团队的第一名,这表明了强大的概括性。
图7:训练集中案例的FLAIR,T1ce和手动注释,以及由六个模型组成的EMMA初始版本的自动分段。 绿色箭头指出各个模型的不一致错误,这些错误可以通过集合进行纠正,而红色箭头则表明一致的错误。
通过对组件的次优配置具有鲁棒性,EMMA可以在不同任务上提供可重用性,我们打算在将来进行探索。
EMMA还可以用于无偏见地研究诸如CNN对域迁移的不同来源的敏感性等因素,这些因素对大规模研究有很大影响[30],或者估计一项任务所需的训练数据量。 最后,EMMA的不确定性可以更客观地衡量哪种类型的患者或肿瘤最难以学习。

若有收获,就点个赞吧
0 人点赞
