1介绍
由于最近卷积神经网络(CNNs)在各种计算机视觉任务中取得了突破(He et al,2015;Taigman等2014;Karpathy等,2014),cnn是一项被高度重视的技术,可用于现实生活中的视觉应用。然而,由于对抗样本,cnn有很高的失败风险,这些例子不断地在自然图像上添加小扰动,人类肉眼无法检测到。
为了降低这一风险,有人提出在一些现有算法生成的干净训练样本和相应的对抗例子上训练cnn (Goodfellow等人2014;Szegedy等人,2013;moosavii - dez愚等人,2016;Sabour等人,2015)。虽然这种训练有素的cnn对特定类型的对抗样本是鲁棒的,但它们并不一定受到所有可能类型的保护。为了提高cnn的鲁棒性,有人提出在各种各样的对抗集合上训练它们,用各种算法为任何单个图像生成对抗示例(Rozsa等人,2016)。然而,仍然有可能产生其他类型的对手,由目前的设置,显著影响cnn的可靠性。此外,针对某些类型对抗训练已经证明会损害干净测试样本的性能(Jin et al., 2015;moosavii - dez愚等人,2016)。
我们更愿意把对抗样本的识别看作是一个开放集识别(open set recognition)问题,未知的样本应该被潜在的模型检测和拒绝。Bendale &Boult(2016)通过添加一个额外的层来识别未知样本,这些未知样本可以来自未知类,也可以愚弄Nguyen等人(2015)的对抗样本,从而适应了cnn。然而,正如作者所提到的,该方法无法检测到目标类和对手的真实类接近的硬对手,例如由Fast Gradient Sign (FGS) (Goodfellow等人,2014)和DeepFool (DF) (moosavii - dez愚等人,2016)生成的对手。
我们建议使用一个由不同专家组成的集合,其中专业是根据混淆矩阵来定义的。事实上,我们观察到,对于来自给定类的对抗性实例,标签往往是在(不正确的)类的一个小子集中完成的。因此,我们认为专家团队应该能够更好地识别和拒绝对抗样本,在对手面前对决策具有很高的熵(即分歧)。实验结果证实了这一解释,即拒绝机制可以提供一种手段,使系统对对抗的例子更具鲁棒性,而不是试图以任何代价对它们进行适当的分类。
2专家+1 集成
集成结构
FGS生成的对抗样本的混淆矩阵(图1)揭示了来自每个类别的样本都有很大的被有限数量的类别愚弄的倾向。
从这些训练对手的混淆矩阵中,我们定义了类的子集,类似于Hinton等人(2015)在训练干净样本方面的做法。考虑K类 ,混淆矩阵的每一行是用来识别identify 两个子集类:1)迷惑目标子集类
,混淆矩阵的每一行是用来识别identify 两个子集类:1)迷惑目标子集类 (子集
(子集 )这是通过按降低ci相关混淆值的顺序依次添加类,直到至少80%的混淆被覆盖, 2)其余具有较低混淆的类,作为子集形成的形成
)这是通过按降低ci相关混淆值的顺序依次添加类,直到至少80%的混淆被覆盖, 2)其余具有较低混淆的类,作为子集形成的形成 子集。应该忽略重复的子集,尽管我们在MNIST和CIFAR-10中没有遇到它们。
子集。应该忽略重复的子集,尽管我们在MNIST和CIFAR-10中没有遇到它们。
对于每一个类子集,一个专家CNN从相关的类中训练样本,其他类的实例被忽略。该集合还包括一个根据完整标签( 子集)训练的generalistCNN,因此被称为“专家们+1集合”。
子集)训练的generalistCNN,因此被称为“专家们+1集合”。
投票机制
使用generalist来激活相关专家的投票机制是不可能的,因为它通常会被对抗样本们愚弄。在算法1中,我们提出了一个投票机制来计算最终的预测。由于每个类 在M个类子集中出现K + 1次,所以对类的最大期望投票数为K + 1。同样,我们将
在M个类子集中出现K + 1次,所以对类的最大期望投票数为K + 1。同样,我们将 定义为给定输入图像x对类的实际投票数(算法1的第1行方程)。如果只有一个类有其实际的票数等于它的最大预期的票数,例如,
定义为给定输入图像x对类的实际投票数(算法1的第1行方程)。如果只有一个类有其实际的票数等于它的最大预期的票数,例如, ,这意味着所有K相关专家和generalist同意投票获胜的类。然后,只有那些投票给获胜者的cnn才会被激活,以便计算最终的预测结果。否则,如果没有一个类获得它们期望的最大票数,这就意味着至少有一个个体被愚弄了。所以,有些选票在不同类之间分配不正确。在这种熵存在的情况下,没有获胜的类,所有的个体都应该被激活来计算最终的预测。
,这意味着所有K相关专家和generalist同意投票获胜的类。然后,只有那些投票给获胜者的cnn才会被激活,以便计算最终的预测结果。否则,如果没有一个类获得它们期望的最大票数,这就意味着至少有一个个体被愚弄了。所以,有些选票在不同类之间分配不正确。在这种熵存在的情况下,没有获胜的类,所有的个体都应该被激活来计算最终的预测。
3实证评估
与Hinton等人(2012)类似,我们使用的cnn有三个卷积层,分别有32个、32个和64个滤波器,以及一个全连接层,然后是一个softmax。
该网络在常规MNIST和CIFAR-10的训练集和测试集上进行训练,不进行任何数据增强。关于每个数据集使用的网络架构和超参数的详细信息,请参阅附录部分。需要注意的是,实验中呈现的所有cnn都具有相同的架构。
实验
我们将我们提出的专家+1集成与纯集成进行了比较,纯集成包括5个具有不同随机初始化的全能型CNN和一个朴素型CNN,其权值初始化不同于GA-CNN(即用来生成对抗样本的CNN)。使用这个GA-CNN,三种类型的对抗样本,即FGS、DF和Szegedy等人(2013)的对抗样本,为正确分类干净的测试样本生成。
根据图2和图3中nist和CIFAR-10对正确分类干净测试样本及其对应对抗样本的置信度分布,比较Naive CNN、pure ensemble和specialists+1 ensemble。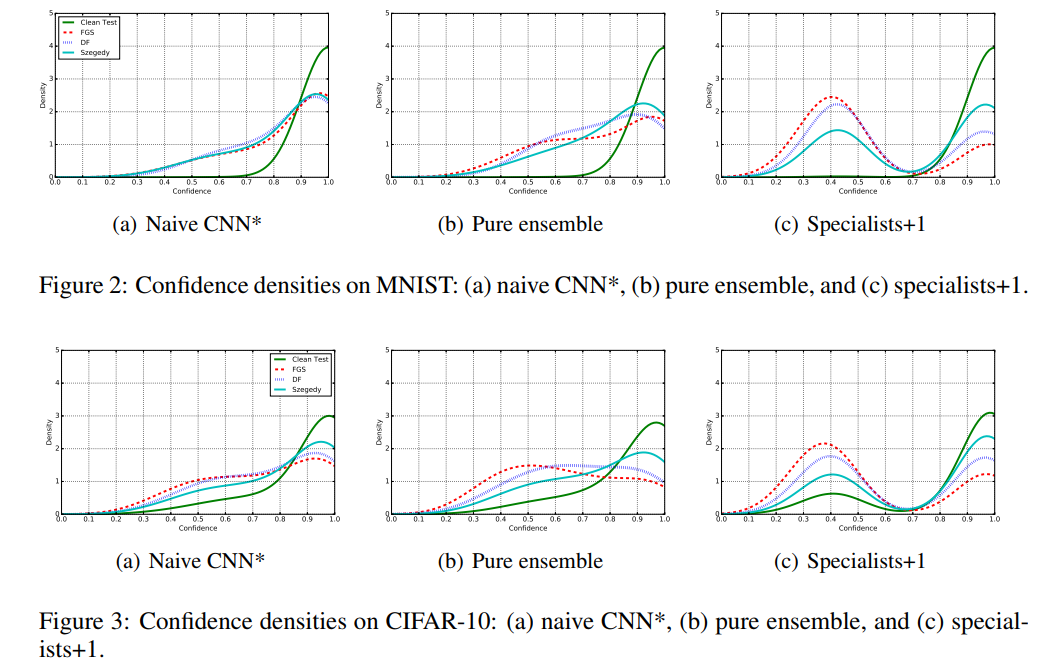
根据对MNIST的这些观察,与naive CNN和纯集合相比,专家+1成功地为大多数被错误分类的对手(不管他们的类型)提供了明显较低的信心。同时,从图2(a)、2(b)、2(c)可以看出,这三种框架对MNIST正确分类的干净测试样本的置信度分布大致相似。对于CIFAR-10,我们观察到敌手的行为与MNIST相同(图3)。但对于正确分类的干净测试样本,专家+1将这些样本中的一些移至较低的置信度(图3(c)中的绿色曲线)。
虽然专家+1没有从任何对手那里受训,但它似乎能够自动降低大多数被错误分类的对手的预测的可信度,而不管他们的类型,同时保留对干净样本的可信度到一定程度。然而,它降低了一些干净的测试样品的置信度。因此,开发一个对未知样本不自信但对已知样本有信心的学习模型可以用于识别和拒绝对手。出于空间考虑,我们在附录图5中描述了拒绝低置信对手对不同类型对手错误率的影响。
总结 简而言之,无需来自对手的训练,并通过对标签的专门化来利用集成中的多样性,专家+1集成方法能够更好地区分合法样本和敌对实例。与纯集成和朴素的CNN相比,该方法在拒绝对手的同时接受基于信心的干净样本方面表现得更好。为了提高CNN对精心设计的攻击的鲁棒性,这是很重要的事情,它宁愿拒绝处理可疑实例,而不是被精心设计的攻击所愚弄。作为未来的工作,我们将比较我们的方法与CNN明确(explicitly)训练,以稳健地应对特定类型的对手。
附录
A.1实验程序
我们考虑具有三个卷积层和一个完全连接层的CNN,其中每个卷积层与ReLU,局部对比度归一化和池化层交织。 为了进行正规化,在最后一层,即完全连接的层,使用p = 0.5进行dropout。 所有的超参数,如初始学习率,训练时间表等,均根据Hinton等人的方法进行设置。 (2012)。
MNIST
该数据集包含大小为28x28的灰度图像,其中每个图像都包含一个手写数字。 训练集和测试集分别具有60,000和10,000个样本。 所有图像均缩放为[0,1]。 利用了150个训练时间段,批量大小为128,初始学习率为0.1,动量为0.9。 在训练期间,在时期50和100,学习率两次衰减10倍。
CIFAR-10
此数据集由50,000个RGB图像(大小为32x32)作为训练集和10,000 32x32 RGB图像作为测试集。 每个图像包含10个类别之一中的一个对象。 来自火车或测试集的所有图像均缩放为[0,1],然后通过均值减法归一化,其中均值是在训练集上计算的。 像MNIST一样,150个epochs,批量大小为128,初始学习率为0.01,动量为0.9。 在120和130epochs,在终止训练之前不久,学习率下降了两倍,为10倍。
A.2生成对抗
使用了快速梯度符号(FGS)(Goodfellow等人,2014),DeepFool(DF)(Moosavi-Dezfooli等人,2016)和(Szegedy等人,2013)提出的算法。 用于对抗性示例生成。
后一种算法以高计算量找到最小的所需扰动,而FGS和DF生成对手的速度要快得多,即少于3次迭代。
使用GA-CNN(用于生成对抗样本的基准CNN),可以识别正确分类的干净样本,然后将其用于生成对手示例。 因此,分别从MNIST和CIFAR-10测试集中生成了9943和8152个对抗样本。 FGS和(Szegedy等,2013)的超参数的最佳值是针对每个数据集获得的,GA-CNN在添加扰动后,对正确分类的干净样本进行了100%的误分类。
在图4中,描绘了由每种算法针对MNIST和CIFAR-10生成的平均失真(扰动)。 同样,它们的平均错误分类置信度也用蓝色表示。
对于每对干净样本(x 2 RD)及其对应的对抗样本(x0),通过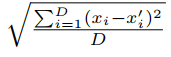 测量失真。
测量失真。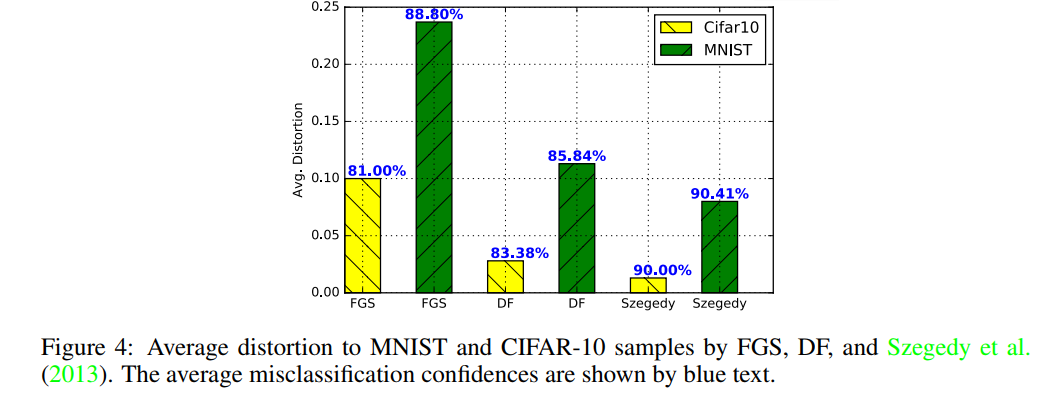
A.3额外的实验结果
令 是在干净的训练样本上训练的多分类系统(例如,单个分类器h(x)或集成h(x))。 像Bendale&Boult(2016)一样,我们考虑拒绝置信度低的实例的阈值(τ),将其分配给拒绝类别
是在干净的训练样本上训练的多分类系统(例如,单个分类器h(x)或集成h(x))。 像Bendale&Boult(2016)一样,我们考虑拒绝置信度低的实例的阈值(τ),将其分配给拒绝类别 。 使用以下经典决策函数:
。 使用以下经典决策函数: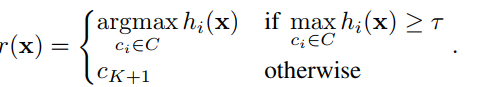
应该考虑两种类型的错误:干净集 上的错误
上的错误 ,并且对抗样本的错误
,并且对抗样本的错误 设置为A = fx0 i; yi0gN i = 1 0(
设置为A = fx0 i; yi0gN i = 1 0( 是
是 的真实标签)。 错误
的真实标签)。 错误 同时考虑了分类错误的干净样本和正确分类的拒绝干净样本:
同时考虑了分类错误的干净样本和正确分类的拒绝干净样本: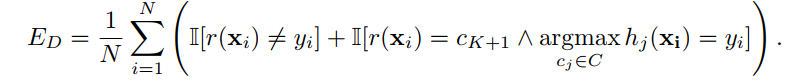
错误EA认为错误分类的对抗实例未被拒绝: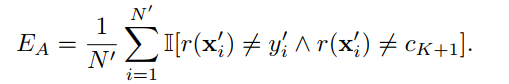
图5给出了带有干净样本和三种类型对手的MNIST和CIFAR-10数据集的错误率ED(公式2)和EA(公式3)。 对于单纯的CNN 和纯集成,随着阈值的增加,不同类型的对手(EA)的错误率会单调降低。 但是,专家+1团队的对手的错误率不会单调降低。 由于专家+1集成对大多数错误分类对手的置信度低于0:5,因此与该天真的CNN 和使用该阈值的纯集成相比,在此阈值下拒绝低置信度预测会大大降低对手误差EA 。 因此,可以确定专家+1可以将大多数错误分类的对手转移到低置信度,因此他们被拒绝了。
可以被CNN正确分类的一些干净样本由于置信度低而被专家+1集成拒绝,因此在阈值0:5时稍微增加了ED。 请注意,将阈值提高到更高的值会导致拒绝大多数对手以及更干净的样本。 因此,这需要在保持较低的干净测试样本拒绝率与拒绝对手之间进行权衡,否则将使网络蒙混。
此外,从FGS和DF对手(EA)在零阈值处的错误率(图5),可以看出FGS和DF对手可以严重欺骗新模型,因为它们是可转移的,即他们的跨模型概括属性,而Szegedy等人的对手。 (2013)对不同模型的归纳较少。 因此,可以通过不同于GA-CNN(对手生成模型)的模型正确,可靠地对大量塞格迪对手进行分类。 请注意,专家0的阈值0:5之后,专家+1的塞格迪对手的EA并没有太大变化。 由于这种类型的对手的大多数高置信度预测(图6(e)和图7(e)中的高置信度显示为青色镐)由专家+1集成正确且可靠地分类。
为了更好地了解,在图6和7中分别显示了MNIST和CIFAR-10的拒绝率与置信度阈值的关系。 根据这些观察,与天真的CNN *和纯集成相比,专家+1成功地为大多数对手(无论其类型如何)提供了低得多的信心。 因此,其对手的拒绝率曲线以较低的置信度增加,并以0:5的阈值非常快地达到某些选择。 但是,通过合并阈值,纯合奏的拒绝率会单调增加,而当同时清除干净样本和对手样本时,则达到更高的阈值。 另外,从图6(b),6(d)和6(f)可以看出,通过这三个框架对MNIST正确分类的干净测试样品的拒绝率曲线几乎相似。

若有收获,就点个赞吧
0 人点赞
