报告链接:https://aiindex.stanford.edu/report/ 更多精读论文:https://github.com/mli/paper-reading
背景
斯坦福2022年AI指数报告精读
报告是由斯坦福下的一个机构HAI撰写
全称是以人为中心的人工智能,虚拟机构,是一个由李飞飞老师和另一位斯坦福做逻辑的老师共同建立
从2017年开始每年发布一个AI指数报告,今年第5期
2020年因为疫情未发布
8个重点
- 2021年私人投资在AI上增加很多,将近1000亿美金投资,比2020年多1倍,投资更加集中
中美跨国研究合作最多
李:技术可能有国界,但科研应该无国界(科研本身来讲是整个人类的共同财产)
语言模型更强也更有偏见,2018年bert1亿参数,2021年2800亿参数模型生成出来的那些带有偏见的有毒的结果增加了29%,因为大模型使用更大的数据,这些数据不像小数据那么能够给你精心准备,而且大模型更容易把大数据里带有偏见的一些东西显现出来
- AI伦理文章越来越多
- AI变得越来越便宜,性能越来越高,训练一个图片分类器的开销从2018年到现在相比的话下降了3.6%,训练的时间缩短了94.4%,这是因为gpu做的越来越大了,如果不计算挖矿导致的GPU价格升高的话,其实他的成本是往下降的,而且我们现在能够用更大的集群,用更好的算法能做分布式的训练,所以它的整体计算时间是下降的
- 在报告的10个数据集上面,9个数据集最好的方法用了额外的数据
- 在全球范围内关于AI的立法也越来越多了
- 机械臂变得越来越便宜了,在2017年平均一个机械臂的价格是4万美金,现在基本只要一半的价格
技术发展曲线:刚刚冒出来-做大做便宜-更安全 
目前所在阶段:偏向安全伦理(很多突破性工作已经做出,这两年没有很大突破性工作)
文章目录
第一章 论文专利情况 Research and Development
文章数量:过去11年AI相关论文的个数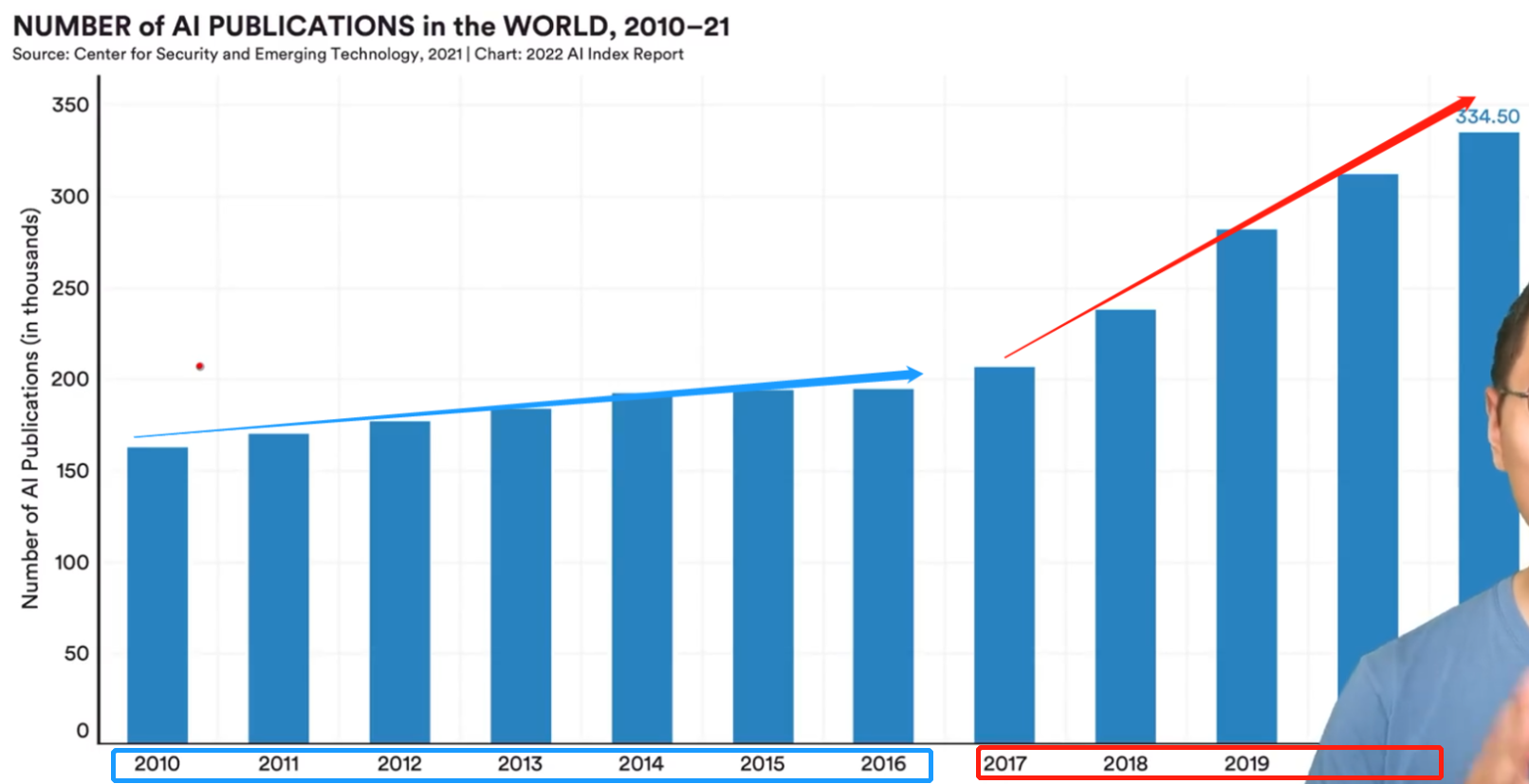
现象:每年发表论文非常多(现在一年30万篇,很多是同学们的练习题)
建议:论文虽多,但99%的文章可能是没有太多意义的,一年读50篇已经是非常好了
文章类别
repository 是ArXiv文章未经过同行审议 杂志和会议比较认可为学术成果 杂志比会议赚钱要交版面费
论文标签汇总
机器学习和模式识别的区别在于
模式识别讲的是一个任务,在数据里面去识别某一个任务出来,比如图片识别,目标检测都是模式识别的任务
机器学习是其中的一个技术,可以使用机器学习技术解决模式识别
机器学习不一样的地方是,从数据里面训练一个模型,再去数据里面发现规律
每篇文章的作者都来自什么机构
发表国家划分
美国情况
中国情况
中美科学家合作写论文的数量
其他国家合作情况
杂志的文章主要来自哪些国家
所有杂志文章按国家划分的总引用数
会议文章统计按国家分
会议引用数对比,中国的引用数还是比美国少很多
发在ArXiv上文章来自不同国家的情况分布
更关心文章影响力和跟别的科学家进行交流
发在ArXiv上文章引用数
AI相关的专利
分析比较大的会议的人数情况
第二章 技术的进展 Technical Performance
目录 按领域划分
计算机视觉——图片
图片分类
ImageNet
按年份划分准确率的提升情况
TOP5精度情况
ImageNet刷精度的必要没有那么大,2017年就精度超过人类,但对计算机视觉图片识别上还是有一点差距
对于各种情况的识别,数据不充分,很难收集足够数据,齐全分类上还是有距离需要继续做
大家都刷ImageNet的原因:
有名
没有比ImageNet好很多的数据来能够测试
ImageNet数据集还是够大,所以一个模型在上面表现得很好,比如A比B好,因此A很有可能在其他任务上也比B好,因此算是一个比较靠谱的数据集
图片生成上进展很大
衡量指标FID
真实图片和生成图片的区别
衡量关系,高斯分布
STL-10数据集上的情况
Deepfake 检测
GAN出来后
把一个人的换到另外一个人的脸上
出现了一些法律,禁止Deepfake用在一些领域
以防虚假信息生成等误导大众
主要数据集:FaceForensics++ 来自youtube主要判断视频的真假,用模型跑生成的视频和真实视频对比
名人数据集Celeb-DF
这一段判断还没有那么准确
人姿态估计
找关键点,做体育分析,人监控,交通手语识别
传感器采集,有场地限制
主要数据集:PCK
在Flickr上采集的2000张运动员图片
判断14个关节的不同位置
精度
Human3.6:3D的人姿势识别
17种不同姿势,判断关节点的位置和真实位置的误差
误差已经缩小到2厘米
语义分割:对图片的每一个像素去判断他属于哪一类
主要应用在无人车,看到地方什么是可以开的路面什么是人行道,什么地方是建筑,什么地方是天空,或者做一些图片的分析,哪个是前景哪个是后景,比如相机照片背景模糊
医疗诊断里面判断有没有肿瘤
数据集Cityscapes
在50个城市里面开车然后录下的一些视频做分割
评测标准IoU
进展迅速
医疗图片语义分割
两数据集,精度提升
误诊伤害不大,漏诊就严重
人脸检测与识别
检测把脸找出来,识别人是谁
识别检测率误差下降明显
但是人脸识别的应用带来了隐私的安全问题
有国家出台法律禁止人脸技术在公共场合被使用
戴口罩的人脸检测识别
错误率相对没带口罩还是大
视觉推理
参考
视频 笔记1

若有收获,就点个赞吧
0 人点赞
