一、概述
假设有如下数据:
:observed data
:unobserved data(latent variable)
:complete data
:parameter
EM算法的目的是解决具有隐变量的参数估计(MLE、MAP)问题。EM算法是一种迭代更新的算法,其计算公式为:

这个公式包含了迭代的两步:
①E step:计算 在概率分布
在概率分布 下的期望
下的期望
②S step:计算使这个期望最大化的参数得到下一个EM步骤的输入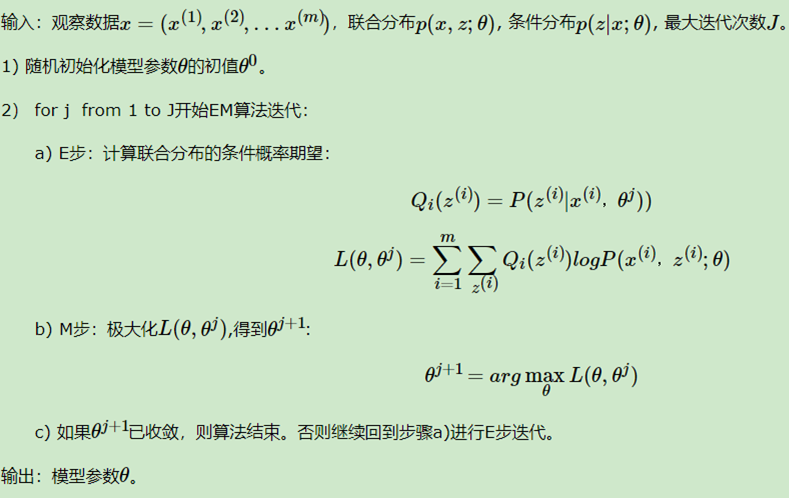
二、EM的算法收敛性
现在要证明迭代求得的 序列会使得对应的
序列会使得对应的 是单调递增的,也就是说要证明
是单调递增的,也就是说要证明 。首先我们有:
。首先我们有:

接下来等式两边同时求关于 的期望:
的期望:

这里我们定义了 ,称为Q函数(Q function),这个函数也就是上面的概述中迭代公式里用到的函数,因此满足
,称为Q函数(Q function),这个函数也就是上面的概述中迭代公式里用到的函数,因此满足 。
。
接下来将上面的等式两边 分别取
分别取 和
和 并相减:
并相减:

我们需要证明 ,同时已知
,同时已知 ,现在来观察
,现在来观察 :
:

因此得证 。这说明使用EM算法迭代更新参数可以使得
。这说明使用EM算法迭代更新参数可以使得 逐步增大。
逐步增大。
另外还有其他定理保证了EM的算法收敛性。首先对于 序列和其对应的对数似然序列
序列和其对应的对数似然序列 有如下定理:
有如下定理:
①如果 有上界,则
有上界,则 收敛到某一值
收敛到某一值 ;
;
②在函数 与
与 满足一定条件下,由EM算法得到的参数估计序列
满足一定条件下,由EM算法得到的参数估计序列 的收敛值
的收敛值 是
是 的稳定点。
的稳定点。
三、EM的算法的导出
- ELBO+KL散度的方法

因此我们得出 ,由于KL散度恒
,由于KL散度恒 ,因此
,因此 ,则
,则 就是似然函数
就是似然函数 的下界。
的下界。
使得 时,就必须有
时,就必须有 ,也就是
,也就是 时。
时。
在每次迭代中我们取 ,就可以保证
,就可以保证 与
与 相等,也就是:
相等,也就是:

也就是说 与
与 都是关于
都是关于 的函数,且满足
的函数,且满足 ,也就是说
,也就是说 的图像总是在
的图像总是在 的图像的上面。对于
的图像的上面。对于 ,我们取
,我们取 ,这也就保证了只有在
,这也就保证了只有在 时
时 与
与 才会相等,因此使
才会相等,因此使 取极大值的
取极大值的 一定能使得
一定能使得 。该过程如下图所示:
。该过程如下图所示: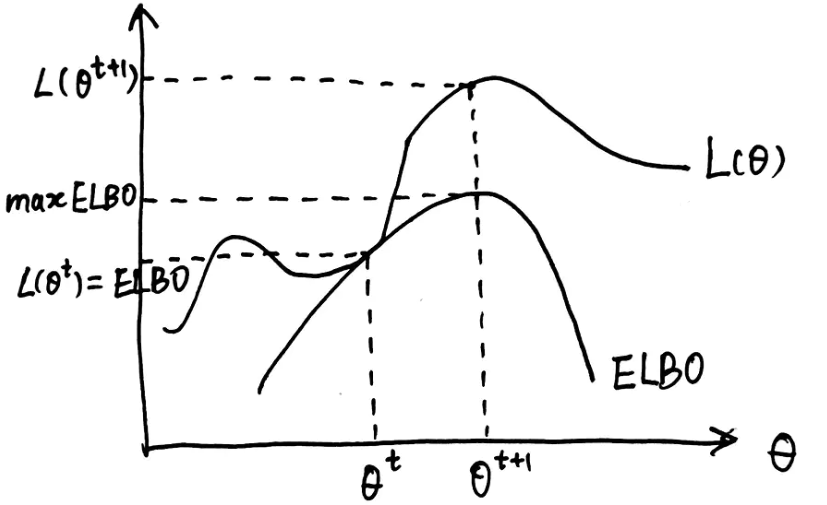
ELBO
然后我们观察一下 取极大值的过程:
取极大值的过程:

由此我们就导出了EM算法的迭代公式。
- ELBO+Jensen不等式的方法
首先要具体介绍一下Jensen不等式:对于一个凹函数  (国内外对凹凸函数的定义恰好相反,这里的凹函数指的是国外定义的凹函数),我们查看其图像如下:
(国内外对凹凸函数的定义恰好相反,这里的凹函数指的是国外定义的凹函数),我们查看其图像如下: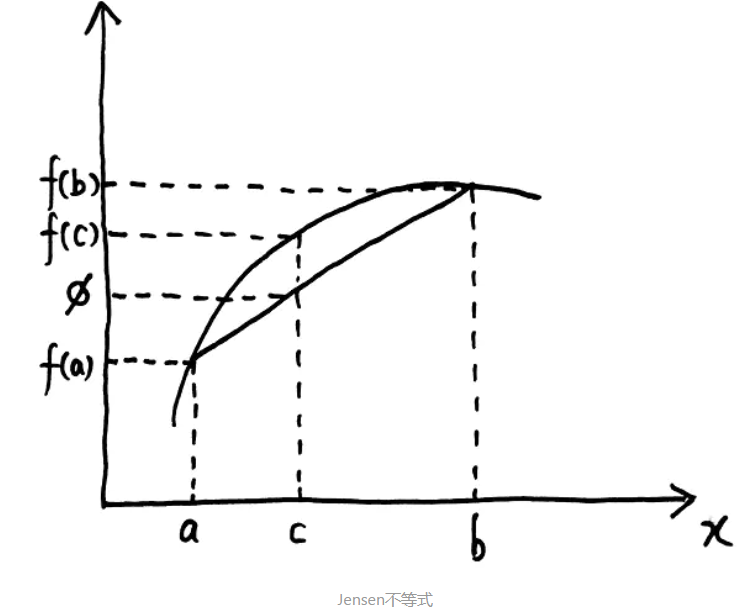
Jensen不等式

接下来应用Jensen不等式来导出EM算法:

这里应用了Jensen不等式得到了上面出现过的 ,这里的
,这里的 函数也就是
函数也就是 函数,显然这是一个凹函数。当
函数,显然这是一个凹函数。当 这个函数是一个常数时会取得等号:
这个函数是一个常数时会取得等号:

这种方法到这里就和上面的方法一样了,总结来说就是:


若有收获,就点个赞吧
0 人点赞
