Ensemble of Deep Convolutional Neural Networks for Learning to Detect Retinal Vessels in Fundus Images
Published 2016,Computer Science, Mathematics-ArXiv。被引:107 https://arxiv.org/abs/1603.04833 @article{maji2016ensemble, title={Ensemble of deep convolutional neural networks for learning to detect retinal vessels in fundus images},
author={Maji, Debapriya and Santara, Anirban and Mitra, Pabitra and Sheet, Debdoot},
journal={arXiv preprint arXiv:1603.04833},
year={2016}
}
摘要
通过眼底彩色成像的定期筛查可以很大程度上预防由于视网膜的病理损伤而导致的视力障碍。 但是,大规模筛查面临的挑战是无法彻底检测对疾病诊断至关重要的细血管。 在这项工作中,我们提出了一种使用深度和整体学习的计算成像框架,用于可靠检测眼底彩色图像中的血管。 深度卷积神经网络的集成经过训练,可以分割彩色眼底图像的血管和非血管区域。 在推理过程中,对集合中各个ConvNet的响应求平均以形成最终的分割。 在使用DRIVE数据库进行的实验评估中,我们达到了血管检测的目的,最大平均准确度为94.7%,ROC曲线下面积为0.9283。
索引词-计算成像,深度学习,卷积神经网络,集成学习,血管检测。
I.引言
通过定期筛查[1],[2]检查的视网膜病理状况可在很大程度上帮助预防视力障碍。 眼底成像是最广泛使用的方式,用于早期筛查和检测导致失明的疾病,如糖尿病性视网膜病变,糖瘤,年龄相关性黄斑变性[3],高血压和中风诱发的变化[4]。 从基于胶片的摄影相机到使用电子成像传感器的进步,眼底的成像已大大改善。 以及无红成像,立体摄影,高光谱成像,血管造影等[5],从而减少了观察者之间和观察者之间的报告差异。 视网膜图像分析也为这项技术发展做出了重要贡献[5],[6]。 由于眼底成像主要用于第一阶段的异常筛查,因此研究重点包括:(i)视网膜结构(血管,中央凹,视盘)的检测和分割,(ii)异常分割,以及(iii)图像质量量化 获得评估报告适应性[5]。
相关工作:视网膜异常的临床报告过程是系统的,并且从血管或视盘上报告了病变的位置。 因此,正在开发计算机辅助诊断系统以改善临床工作流程[5]。 一些进展包括图像质量评估[8]; 血管检测[7],分支模式,直径和血管树分析[3],[4],[9],[10];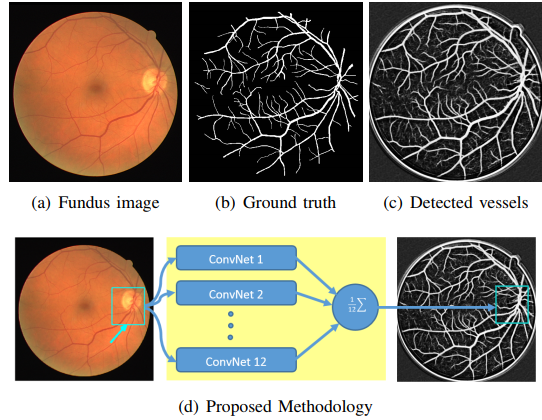
图1.使用我们提出的集成ConvNets检测视网膜血管。
然后报告病变及其在血管中的位置[4],[10]。 在这种情况下,一个重要的挑战是利用计算机辅助诊断的潜力[5],[11]并协助常规筛查[3],[4],对彩色眼底图像中的视网膜血管进行可靠,彻底的检测。
挑战:血管检测和分割的方法[5] – [7],[9],[10],[12]主要使用图像滤镜,矢量几何,统计分布研究以及针对低阶特征和光子分布模型的机器学习来血管检测。这样的方法依赖于使用手工制作的功能或启发式假设来解决问题,并且没有被普遍用于从数据本身中学习模式属性,因此由于方法固有的弱点,使它们容易受到性能主观性的影响。最近,已经提出了完全数据驱动的,基于深度学习的模型[13]。 然而,与使用常规范例的现有技术方法相比,它们的性能较弱。 这里的主要挑战是设计一个端到端框架,该框架无需任何基于领域知识的启发式信息就可以从数据中学习模式表示,以识别粗细血管结构和精细血管结构,并且至少要比基于启发式的算法好得多。
方法:本文尝试通过在原始彩色眼底图像上训练12个卷积神经网络(ConvNets)[14]的集合来区分特征表达中的主观性引起的偏差问题 非血管像素的血管像素。 图1示出了使用这种方法的详尽的视网膜血管检测的示例。 每个ConvNet具有三个卷积层和两个完全连接的层,并分别从训练图像中随机选择的补丁上进行训练。 在推论时,对每个ConvNet独立输出的血管概率进行平均,以形成每个像素的最终血管概率。
第2节给出了该方法的简要理论背景。 问题陈述在第三节中正式定义,提出的方法在IV中描述。 DRIVE数据集上的实验评估结果已用V表示。 本文最后总结了所提出的方法,并讨论了基于端到端深度学习的解决方案对VI中医学图像分析的可能影响。
2.理论背景
本节介绍有关ConvNet和集成学习的一些概念,这些概念构成了提出的解决方案的基础。
卷积神经网络:卷积神经网络(CNN或ConvNet)是一类特殊的人工神经网络,旨在处理具有网格状结构的数据[14],[15]。 ConvNet体系结构基于稀疏交互和参数共享,对于有效学习图像中的空间不变性非常有效[16],[17]。 在典型的ConvNet体系结构中,共有四层:卷积(conv),池化(pool),完全连接(仿射)和整流线性单元(ReLU)。 每个卷积层通过使用一组过滤器进行卷积,将一组特征图转换为另一组特征图。 在数学上,如果Wil和bl分别表示第l个卷积层的第i个滤波器的权重和偏差,而H1则表示其激活图,则:
Hl i = Hl-1⊗Wil + bl i(1)
其中where是卷积算符。 池化层对输入要素图执行空间下采样。 合并有助于使表示形式对于输入的小翻译变得不变。 完全连接的层类似于普通神经网络中的层。 令W1表示传入的权重矩阵,b1表示完全连接层的偏置向量l。 然后:
Hl = flatten(H-1) Wl bl(2)
其中,flatten(:)运算符沿高度平铺输入体积的特征图,0 0是矩阵乘法,0 and0是逐元素加法。 ReLU层执行输入的逐点整流,并对应于激活功能。 对于第l层的第i个单元:
Hli = max(Hil-1; 0)(3)
在较深的ConvNet中,较深层中的单元与输入的较大区域间接交互,从而形成输入数据的高级抽象。
集成学习:集成学习是一种使用多个模型或专家来解决特定人工智能问题的技术[18]。 集成方法寻求促进模型组合中的多样性,并减少与训练数据过度拟合相关的问题。集合的各个模型的输出被组合(例如通过平均)以形成最终预测。具体来说,如果为{ }是集合的k个模型,而
}是集合的k个模型,而 是在模型
是在模型 下输入x被归为
下输入x被归为 的概率,则集合预测:
的概率,则集合预测:
集成学习促进更好的泛化并且通常提供比单个模型更高的预测准确性。
3.问题陈述
让我成为由彩色眼底照相机的RGB传感器获取的图像。 在位置x处观察到的强度用g(x)表示。 令N(x)是x的局部邻域中的一组像素。 让 ,是位置x处像素的类别标签集。 在机器学习框架中,找到类型组织的概率! 在位置x处,p(!jI; x)由一类函数H(!jI; N(x); x;θ1;θ2)建模,其中θ1是从训练数据和θ2中获知的一组参数, 使用验证数据调整的一组超参数。在所提出的方法中,H(:)是ConvNets的集合,其结构将在下面描述。
,是位置x处像素的类别标签集。 在机器学习框架中,找到类型组织的概率! 在位置x处,p(!jI; x)由一类函数H(!jI; N(x); x;θ1;θ2)建模,其中θ1是从训练数据和θ2中获知的一组参数, 使用验证数据调整的一组超参数。在所提出的方法中,H(:)是ConvNets的集合,其结构将在下面描述。
IV。 建议的解决方案
ConvNet的每一层都将一个特征量转换为另一个特征量。 特征量描述为N×V×H,其中N是空间维数V×H的特征图的数量。所提出的集合中每个ConvNet的输入是3×31×31彩色眼底图像块。 ConvNet具有相同的层次结构,可以描述为:输入-[conv -relu]-[conv-relu-pool] x 2-仿射-relu-[仿射与dropout]-softmax。
图2给出了该组织的示意图。 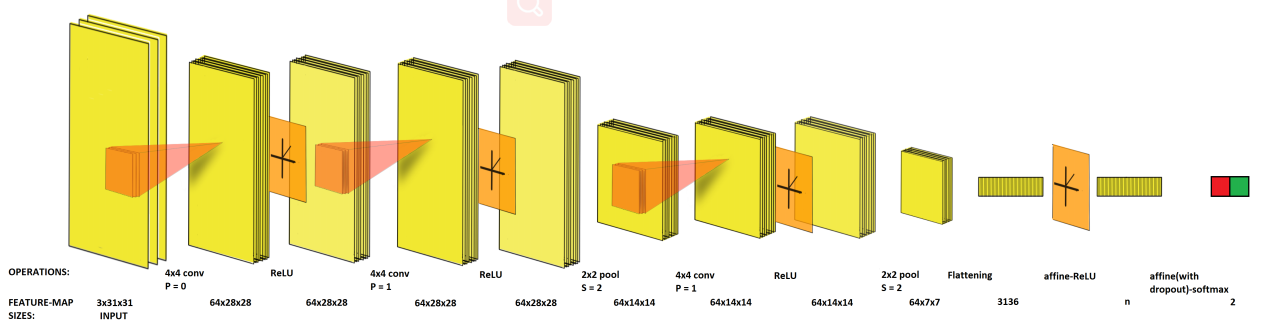
图2.提出的集成卷积网络中的层组织。 S-步长,P-零填充,n-不同ConvNet中倒数第二个仿射层变量中的隐藏单位数(有关详细信息,请参见V)
每个conv层的接收字段大小为4×4,步长为1,输出量为64×32×32。池化层的接收字段大小为2×2,步长为2。Dropout [19]是一种正则化方法,用于 增强稀疏性,防止特征的共同适应并通过在每次学习过程中强迫一部分神经元不被激活来促进更好的泛化的神经网络。 最后一层的输出传递到softmax函数,该函数将输出转换为类概率。 令 表示完全连接的输出层的第i个神经元的激活,而
表示完全连接的输出层的第i个神经元的激活,而 表示第i个输出类的后验概率。 然后:
表示第i个输出类的后验概率。 然后: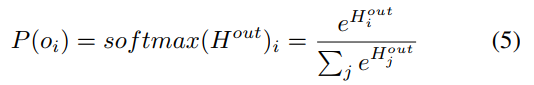
五,实验结果与讨论
本节介绍了该技术的实验验证,以及与早期方法的性能比较[11]。
数据集:通过学习DRIVE训练集(图像ID:21-40)并在DRIVE测试集(图像ID:1-20)1上进行测试,来评估ConvNets的集成。
学习机制:每个ConvNet在一组60000个随机选择的3×31×31patches上进行独立训练。 各个模型的学习率1e-4,动量项0.95。 分别从U([0.5, 0.9]),U([1e-3,2.5e-3])中采样不同模型的dropout概率,L2正则化系数和倒数第二个仿射层中的隐藏单元数。 )和U({128,256,512})其中U(.)表示给定范围内的均匀概率分布。 使用RMSProp算法[20](最小批量为200)对模型进行了训练。
性能评估:表I列出了与早期技术报道的准确性和一致性的检测结果。 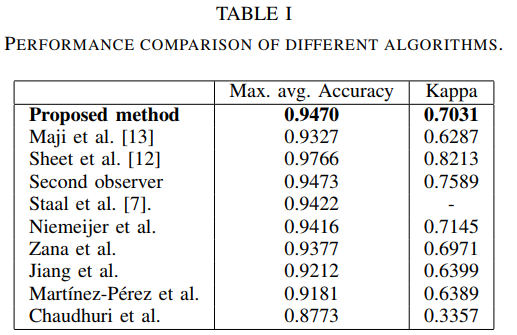
显然,尽管我们的方法与其他方法相比没有最高的准确性,但它的确比以前提出的基于深度学习的方法从数据中学习血管表示具有更好的性能[13]。kappa评分是观察者一致性的研究,表明该技术检测粗血管和细血管的灵敏度。 图3显示了对粗血管和细血管检测的典型响应。
图3.在[7]中检测样品#5中的(a-d)粗血管以及样品#16中的(e-h)粗血管和(i-1)细血管。
图4给出了所提出方法的接收器工作特性(ROC)曲线。 获得的ROC曲线下的面积为0:9283。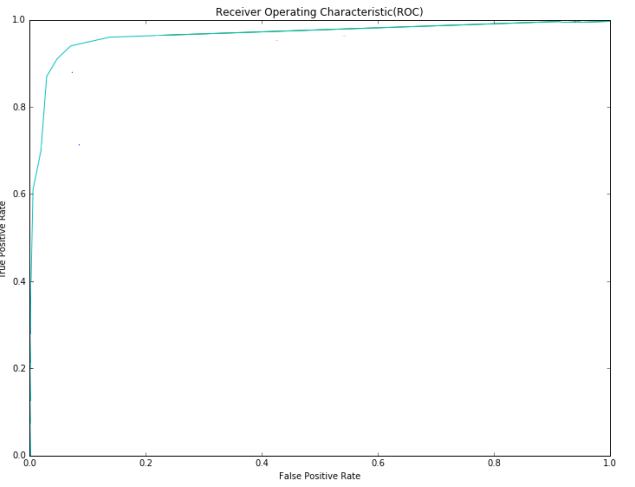
图4.接收器工作特性(ROC)曲线图像分析。
VI。 结论
本文提出了一个基于ConvNet集成的框架,用于处理彩色眼底图像以检测粗细血管。 该方法在DRIVE数据集上进行了实验评估。识别图像,并利用概括学习的整体学习来设计一种启发式独立的,数据驱动的方法来分析医学图像。 这为医学上的主观性偏见提出了可行的解决方案。这是对我们以前对眼底图像进行数据驱动分析的工作[13]的改进。 通常,此方法还提供了一种强大的替代方法,可通过深度学习与集成学习的强大功能来解决复杂的医学数据分析问题。
参考
博客1

若有收获,就点个赞吧
0 人点赞
