On the Robustness of Semantic Segmentation Models to Adversarial Attacks
结论:短期来看,我们的观察结果表明,基于ResNet并执行Multiscale处理的Deeplab v2之类的网络因其固有的
鲁棒性而应在安全性至关重要的应用中优先使用。
@inproceedings{arnab2018robustness, title={On the robustness of semantic segmentation models to adversarial attacks}, author={Arnab, Anurag and Miksik, Ondrej and Torr, Philip HS}, booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, pages={888—897}, year={2018} }
摘要
深度神经网络(DNN)在大多数识别任务(例如图像分类和分割)上均表现出出色的性能。但是,他们也被证明容易受到对抗样本的攻击。最近,这种现象引起了很多关注,但尚未在多个大规模数据集和结构化预测任务(例如语义分段)上进行广泛研究,而语义预测这些任务通常需要具有附加组件(例如CRF,膨胀卷积,跳过连接和多尺度)的更专业的网络。加工。
在本文中,我们介绍了据我们所知是使用两个大规模数据集对现代语义细分模型进行的对抗攻击的首次严格评估。我们分析了不同网络体系结构,模型容量和多尺度处理的影响,并表明对分类任务所做的许多观察并不总是转移到这一更复杂的任务上。此外,我们展示了深度结构化模型,多尺度处理(更一般而言,输入转换)中的均值场推理如何自然地实现最近提出的对抗性防御。我们的观察结果将有助于将来在理解和防御对抗性例子方面做出更大的努力。此外,在短期内,我们将展示如何有效地对稳健性进行基准测试,并说明由于其固有的稳健性,目前在安全关键型应用程序中应首选哪种细分模型。
简介
背景:DNN的性能异常出色,但很容易受到对抗性示例的攻击,有安全问题应该始终考虑部署一种对(安全性至 关重要的)生产环境中的对抗样本最强大的模型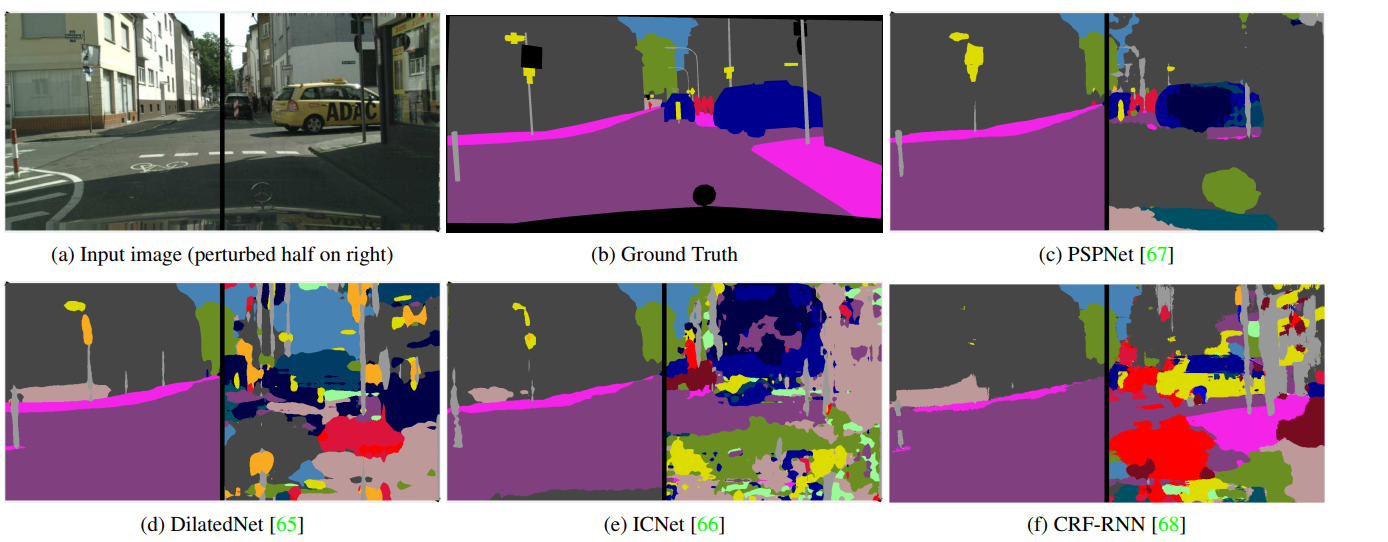
图1:左侧显示原始图像,右侧显示经过不明显的对抗性扰动修改后的输出。
其他人的工作:[29,41,55,48]
出现的问题:1.容易受到其他类型的攻击[11、9、10、34]
2.以对干净输入的性能进行惩罚为代价[12、31、48]
3.缺乏更复杂的任务(如覆盖不同域的真实数据集的上下文中)中的语义分割等对抗攻击防御的研究
论文的工作:对语义分段模型对对抗攻击的鲁棒性的首次严格评估
1.我们分析了不同DNN结构对对抗样本的鲁棒性结果表明,Deeplab v2网络[15]比在公共基准上获得更好的预测分数的方法要强大得多[67]。 其次,我们证明了对抗样本在不同规模下的处理效果较差。
2.多尺度网络对多种不同的攻击更具鲁棒性,对它们的白盒攻击会产生更多可传递的扰动。
3.我们表明结构化的预测模型与“梯度掩盖”防御策略具有相似的效果[54,55]。 这样,平均场CRF推理可提高针对非目标对抗攻击的鲁棒性,但与梯度掩蔽防御相比,它也提高了网络的预测准确性。
4.在图像分类的背景下进行的一些关于健壮性和模型大小或迭代攻击的广泛接受的观察[41,48]并没有转移到语义分割和不同的现实世界数据集中。 最后,与现有技术相反[41,44],我们的实验是在两个大规模的真实世界数据集上进行的,并且(大多数)我们的观察结果在它们之间保持一致。
对抗样本
将对抗性扰动r定义为优化问题的解,各种改进,但速度还是慢,故实践中使用:
Fast Gradient Sign Method (FGSM)
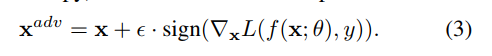
FGSM ll
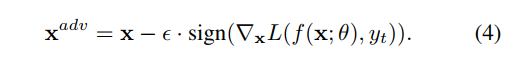
Iterative FGSM
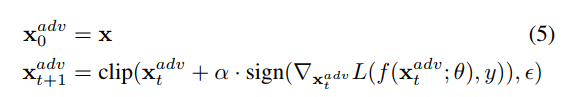
Iterative FGSM ll
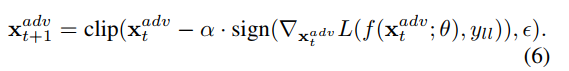
3.对抗防御与评估
5.不同结构的健壮性
5.1不同网络的鲁棒性
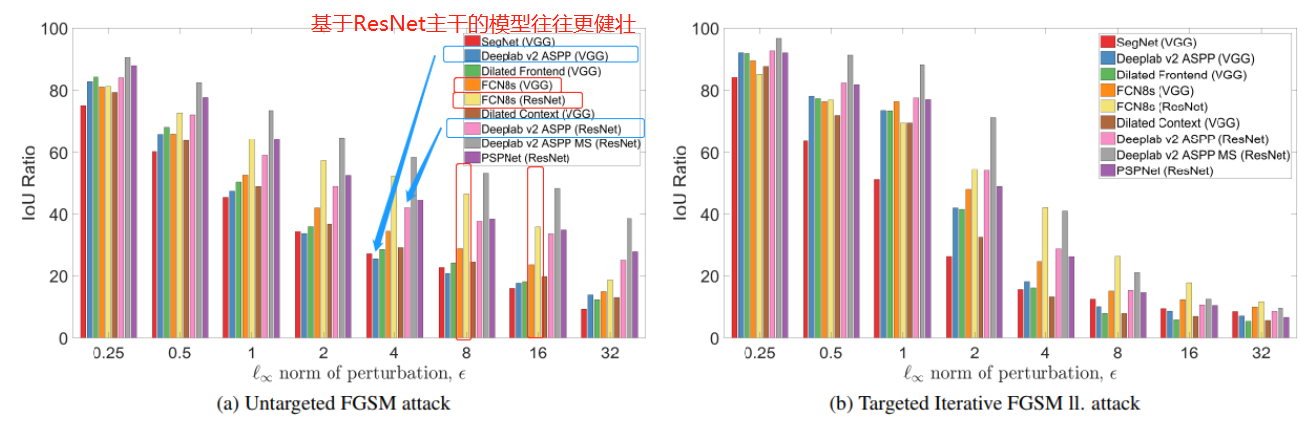
1.基于ResNet的模型不仅在clean inputs上具有更高的精度,而且对对抗输入也具有更强的鲁棒性。 对于单步FGSM攻击尤其如此。
2.在欺骗网络方面,迭代FGSM ll攻击比单步FGSM更有力。更有效的迭代FGSMⅡ攻击中,最健壮的网络和最不健壮的网络之间的裕度较小,因为它们都无法发挥良好的作用
5.2模型容量和剩余连接
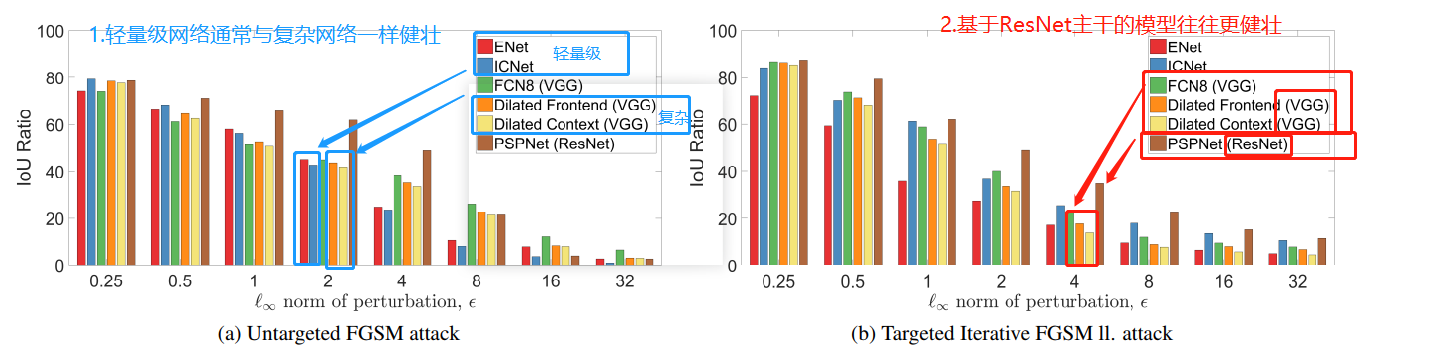
1.基于ResNet主干的模型往往更健壮
2.轻量级网络通常与复杂网络一样健壮
3.奇怪的是,FGSM攻击比迭代FGSM ll更有效,后者从更大的搜索空间计算对抗性示例。
5.3一次攻击方法在Cityscapes上出乎意料的有效性
现象:1.单步FGSM和FGSM ll攻击在Cityscapes上比在Pascal VOC上有效得多
2.对于Cityscapes上的高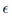 值,单步方法(仅在图像空间的一维子空间中搜索)似乎也优于迭代方法
值,单步方法(仅在图像空间的一维子空间中搜索)似乎也优于迭代方法
3.当使用与[41]相同的超参数时,迭代攻击对Cityscapes的效果与对Pascal VOC的效果差不多
原因:它可能是一个数据集属性,导致网络学习更容易受到单步攻击的加权。
从主观上讲,Cityscapes的可变性比VOC小,并且它也标记了“东西”类[27]。
之前从未考虑过训练集对对抗攻击的影响,并且大多数先前的工作都使用了MNIST [59,29,48]或ImageNet [41,60,44]。
然而,[6]和[37]表明,通过将“有毒”示例插入其训练集中,可以分别增加SVM和神经网络的测试误差。 补充说明了FGSM ll攻击的结果,该结果显示出与FGSM相同的趋势。
5.4不可察觉的扰动
现象:1.非常小的扰动也会较大幅降低IOU
2.作为预处理步骤的有损JPEG有助于减小小幅的FGSM
原因:因为JPEG并未完全保留这些小的高频扰动,并且结果也最终取整为整数
5.5讨论
1.基于ResNet主干的模型往往更健壮
6.多尺度处理和Transferability对抗样本
Sec5表明:Multiscale ASPP的Deeplab v2是各种攻击下鲁棒性最强的模型
6.1Multiscale处理
Deeplab v2网络以三种不同的resolutions(50%,75%和100%)处理图像,每个比例尺分支之间共享权重。 每个尺度的结果被上采样到一个共同的resolution,然后进行最大池化,从而选择来自每个尺度分支的每个像素的最可靠预测[15]。 该网络以这种多尺度方式进行训练,尽管有可能仅在测试时将这种多尺度集合作为后处理步骤进行[14、19、42、67]。
我们假设,如果以单一规模进行对抗攻击,则以另一种规模进行对抗不再具有恶性。 这是因为CNN的规模不变,并且还有其他一系列转换[24,35]。 而且,尽管有可能从多个不同比例的输入生成对抗性攻击,但这些示例在单个比例上可能不那么有效,从而使得在多个比例下处理图像的网络更加健壮。
6.2不同规模的对抗样本的transferability
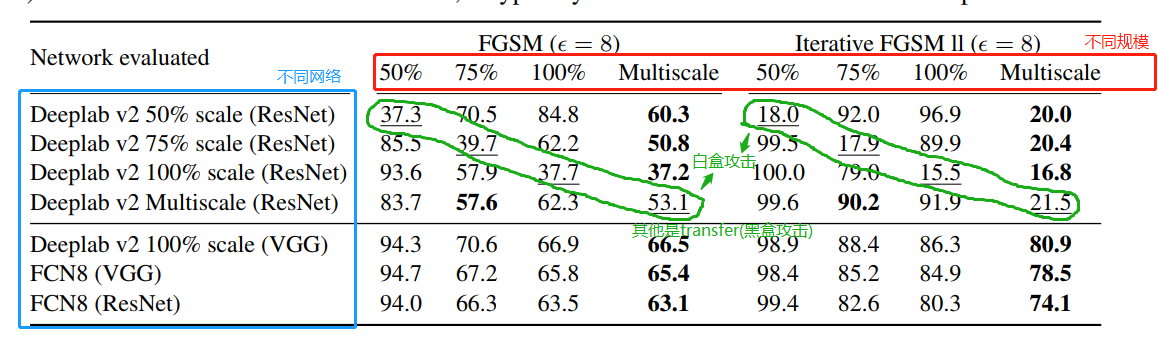
说明:列出了FGSM和迭代FGSM II攻击的结果。 对角线显示“白盒”攻击,其中从受攻击的网络生成对抗样本。
非对角线显示了从其他网络产生的扰动的可传递性。
结论:
1.与迭代FGSMⅡ相反,FGSM攻击很好地转移到其他网络
2.由Deeplab v2的多尺度和100%resolution产生的扰动transfer得最好(实现与白盒攻击类似的IoU比率)。
由于CNN的规模不变(网络激活发生了很大变化),因此在一种规模下进行的对抗性攻击在另一种规模下进行评估时效果不佳
3.总体看对抗样本在不同规模上的转移不佳。
6.3多尺度网络和对抗样本
结论:Deeplab v2的多尺度版本对白盒攻击(表1,图2)以及单尺度网络产生的扰动的鲁棒性最强。
此外,由它产生的攻击也将最好的攻击转移到其他网络
6.4对抗性样本的转变
6.5与其他防御的关系
其他人相关的防御工作:
通过随机操作减缓对抗攻击的影响(Mitigating Adversarial Effects Through Randomization):
具体防御方法:“随机调整大小”防御:即对输入图像随机调整大小,再进行分类
利用原理:利用(但不归因于其有效性)CNN并非规模不变且对抗性示例仅以原始规模生成的事实
我们假设可以通过在多个层面上进行对抗性攻击来打败这种防御
8.结论
1.短期来看,我们的观察结果表明,基于ResNet并执行Multiscale处理的Deeplab v2之类的网络因其固有的鲁棒性而应在安全性至关重要的应用中优先使用。
2.由于干净输入上最准确的网络不一定是最鲁棒的网络,因此我们建议像本文所述评估各种对抗性攻击的鲁棒性,以便在实践中部署模型之前找到准确性和鲁棒性的最佳组合。
参考

若有收获,就点个赞吧
0 人点赞
