一.动机
为什么要研究攻击和防御?
举例:垃圾邮件侦测的模型:制造垃圾邮件的人,希望能够攻击这个模型,骗过垃圾邮件侦测;
而垃圾邮件侦测模型,也要具备防御这种攻击的能力。
机器学习模型只能够应对噪声是不够的,需要能够应对恶意的攻击。
二.Attack
1.基本思想
1.人应该是不容易察觉的(攻击所用的输入和原输入应该相对很接近)
2.攻击达到的效果(Non-targeted Attack) or (Targeted Attack)。
如下图所示,第一种就是最后认为不是猫即可,而第二种就是最后认为尽量是鱼。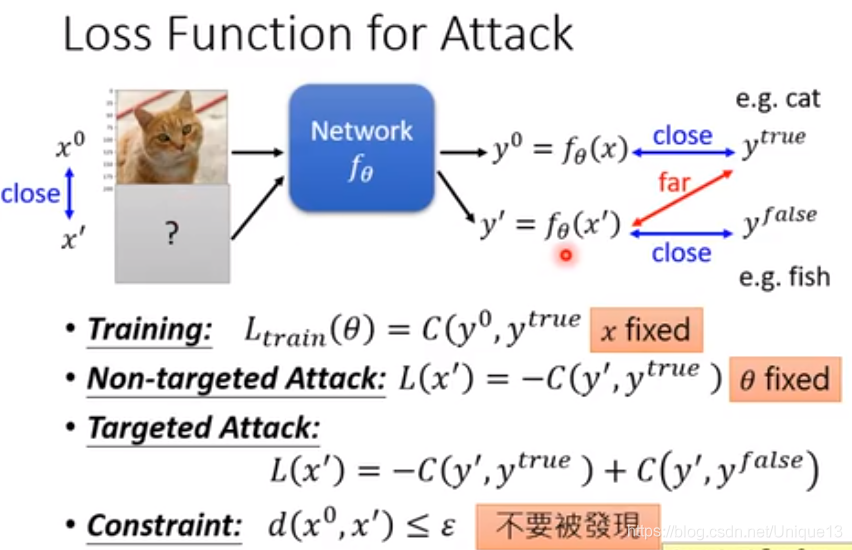
当然在训练攻击图片的时候,我们是不改变模型本身的参数的,我们是固定住了θ,而训练的是x。
2.相似度限制
实际训练中我们首先要定义的就是“我们如何判断这是与原图片相似的图片”。我们设原输入是x,攻击用的图像是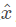 ,一般我们用的是
,一般我们用的是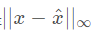 ,也就是我们看各个像素的最大差值。
,也就是我们看各个像素的最大差值。
使用无穷范数的原因如下图所示,对于我们人眼而言,我们一眼就能看出左面的图片和右下角图片有很大不同,而很难辨识出与左上角图片的差距;虽然其实它们做差的2-范数相同。总的来说,当图片不是这么简单的时候,其实道理也还是类似的,如果有几个像素有明显的变化,我们人眼还是能轻易捕捉到的(尤其是专门去检查的话),而整张图片每个像素都有很细微的变化,我们肉眼几乎是完全检查不出来的。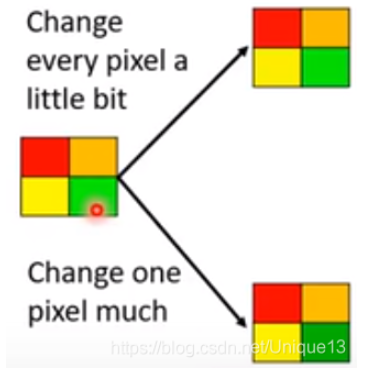 当然,这还是个见仁见智的问题,对不同的任务可能有更好的定义方式。
当然,这还是个见仁见智的问题,对不同的任务可能有更好的定义方式。
3.训练参数
这里我们可以用梯度下降的方法进行学习,但是会出现一个问题,那就是我们会出现到达的点在范围外的情况,因此我们需要进行额外的操作。
而这个操作,反正就是一种把所谓的外面的点拉回来的方式。相对来说最靠谱的就是,拉到距离之前的点最近的边界上。下面的图片就是针对2-范数和无穷范数的情况。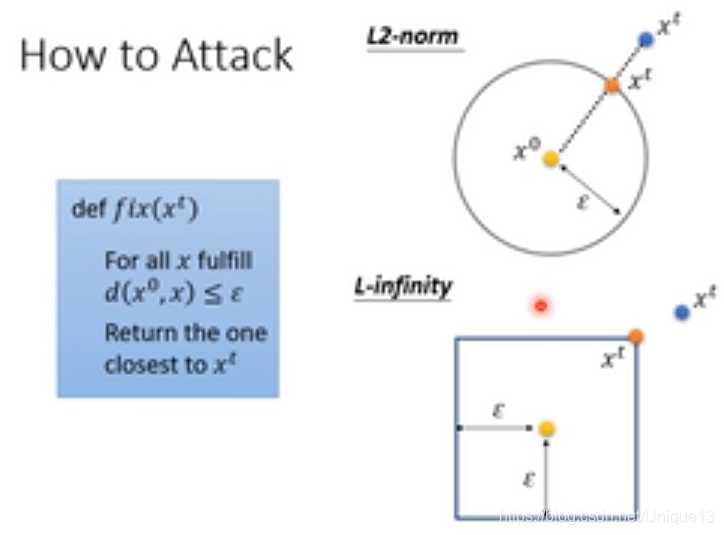
4.攻击效果与出现的原因
以下是视频中的攻击效果,可见不仅在理论上,而且在实际生活中攻击效果都可以十分的显著。

至于为什么会导致这种结果,我们其实可以这样来想:首先这是一个很复杂的神经网络,最后边界的情况是十分复杂扭曲的;而且输入的维度是十分十分大的,至少都有上千维。在一个置信度较高的点的邻域内,只要我们找到哪怕一个方向上出现了置信度变低很多的情况,那就会被这种方式攻击顺着这个方向从而找到弱点。因此可以说,相当于就类似,要想完全的防住这种攻击,那么就要求邻域内任何地点都要有足够的置信度,这要求显然太高了(越高维越困难)且本来也不一定正确。
5.更多的新型攻击方式
不同方法有什么差别呢?
其实所有的方法都是针对上述优化问题,采用了不同的优化算法,或者定义了不同的相似性约束而已。
(1).FGSM
首先:初始化一个x0
然后:计算梯度,只保留符号(只关心梯度的方向,不关心梯度的大小)
最后:一次更新,就得到了攻击样本x ∗ x^*x∗。
如下图所示,假设约束条件选择的是L-infinity。如果蓝色实线是梯度,那么按照梯度的相反方向,以ϵ 大小一次更新到了x∗就完成了。(进阶版:可以多次迭代更新)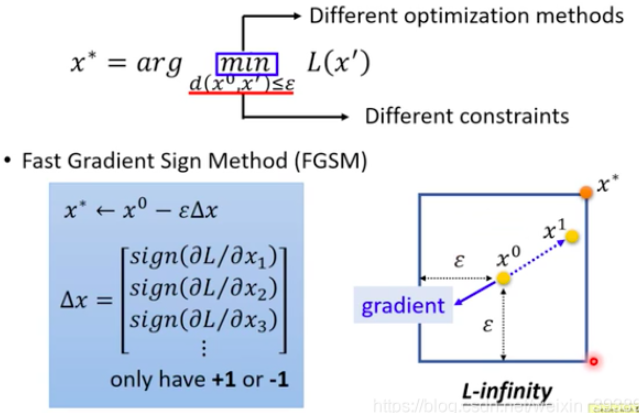
原理理解:算法设置了一个很大的学习率,然后计算之后跑出了约束条件限制的区域(跑到了x1 ),然后被拉回来就可以了。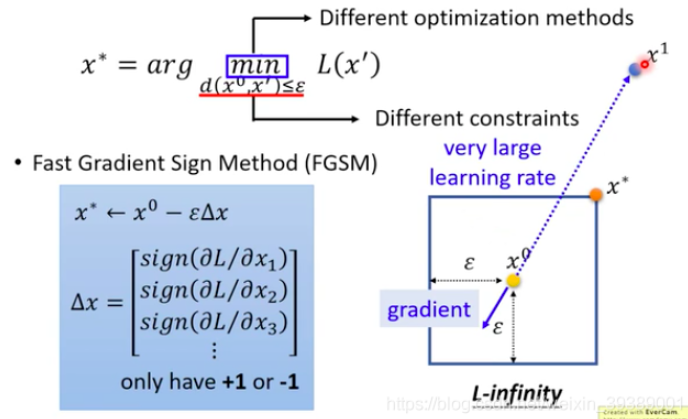
(2).One Pixel Attack
这种攻击思想基于,对于一张像素比较大的图片,我们把任意一个像素随意改变,其实人眼是无法辨别出来的,而对机器的判别效果可能会有比较大的影响。
如下图所示,其中0范数的意思是说非零元素的个数。当然,对于这种方式,Non-targeted Attack和Targeted Attack对效果好坏的定义其实也是都比较好办的。
但是所谓的训练过程会发现一个问题,那就是这里我们完全无法使用梯度下降的方法去找到我们想要的解。因为我们是对其中一个像素可以任意改变,在当前的位置梯度大(对结果更敏感)的像素不一定在改变很多之后效果比另外的像素改变带来的效果好。所以说,我们无法使用梯度来进行寻找。
当然,我们可以暴力枚举,但是这样相当于我们可能要实验上千万次,显然要用大量的时间,不太科学,因此我们需要一些启发式算法,这里我们采用的是差分进化算法,是遗传算法的一种改进算法,其实就是在遗传算法的基础上,从之前的随机变异变成了一种有特点的变异方式,这里笔者推荐一篇文章:https://www.cnblogs.com/tsingke/p/5809453.html
6.白盒攻击 v.s. 黑盒攻击
上面的攻击是已知网络参数θ ,来设计攻击样本x′ 。属于白盒攻击。
是不是保护好网络参数不要被知道,就可以防御攻击了呢?
不是的,黑盒攻击(对方不知道我们的网路参数)也是可能的!
(1)黑盒攻击
- 如果你知道对方训练网络时采用的数据集,就可以自己用那些数据集来训练一个Proxy Network。针对自己训练的Proxy Network设计对抗样本,通常也能攻击成功对方的黑盒网络哦~~
- 保护好训练数据呢??仍然可以的。通过不断给黑盒网络输入数据,搜集输出数据。就得到了这个网络的很多输入-输出对。仍然可以训练一个Proxy Network。
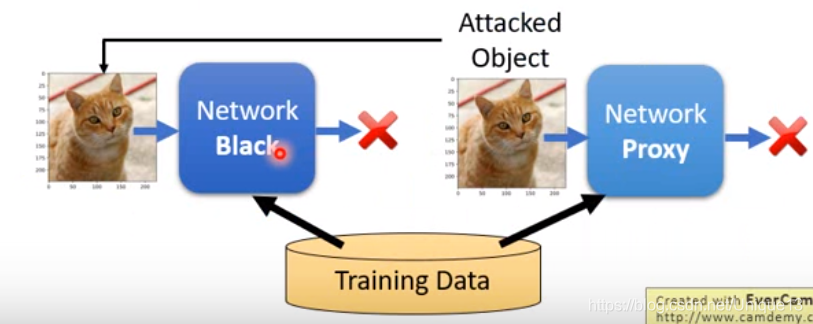
黑箱攻击有很大可能成功。原因:其实就是对于不同的问题,最后大致效果应该是类似的,既然效果类似,那弱点也很可能类似(当然这些还并没有太多严格的理论)。
看下面的例子,是采用Proxy网络来设计对抗样本,然后攻击黑盒后,黑盒的辨识的正确率。
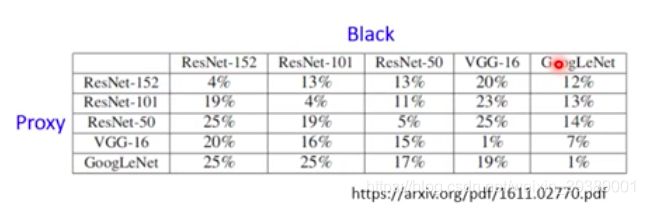
可以看出,如果两个网络一样那么攻击成功率就很高(黑盒辨识的正确率非常低)。
如果两个网络不同,攻击成功率也还可以的。
7. 一些好玩的Attack研究
universal adversarial attack
生成对抗样本时候,需要每个图片训练一下,得到最佳扰动量。每个输入的攻击图片都要单独计算。其实,还是有universal的对抗攻击方法的。比如下面这篇文献就设计了一种扰动量,对于数据集中的大部分图片,都能够产生攻击样本。而且还能做黑盒攻击。
universal adversarial attack文献地址
adversarial reprogramming
这个就很好玩,把原来的图像分类网络,加上Adversarial Program(就是一些噪声扰动),就可以让这个网络做别的事情。比如现在这个网络变成了可以数方块网络。几个方块就对应某个图像类别的输出。输入是有几个方块的图片,加上设计的扰动(Adversarial Program),再输入这个网络,类别值就对应了方块个数。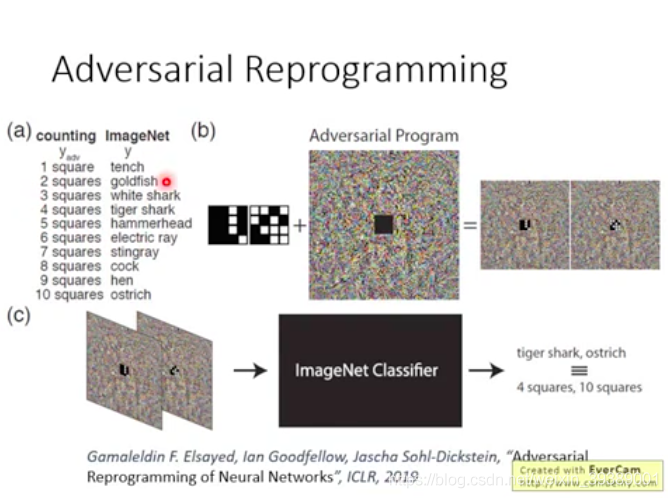
Attack in the Real World
物理世界中的攻击
1)研究时候加入的噪声比较小,物理世界中用照相机拍摄时候,这些噪声会不会太小而没办法起到作用?Ian Goodfellow这篇文章中研究用照相机去识别真实图片和对抗攻击的图片,依然可以成功。
2)对于人脸识别的门禁系统,想要入侵这个系统而把人脸上都加入噪声。。显然不合理。因此下面的研究是把扰动集中在了某个区域,比如戴上这一个特殊的眼镜,就可以使人脸识别系统判断错误。更牛x的是他们还真的设计出了这种眼镜!并且:多个角度都可以;确保扰动能够被对方的相机捕捉到;设计的扰动噪声的色彩是打印机能够打印出来的。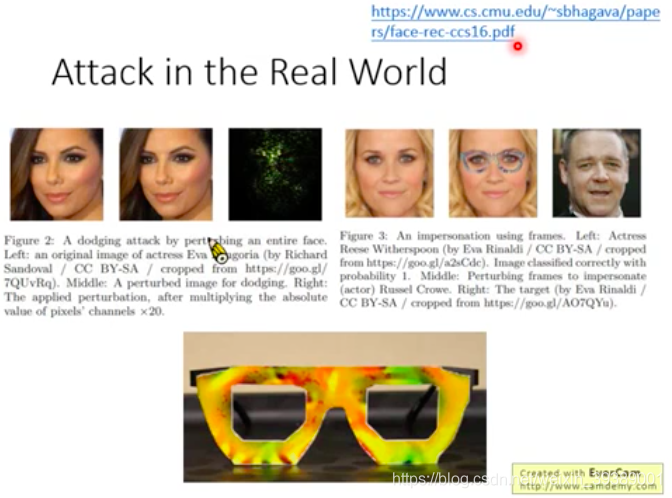
3)对于自动驾驶系统的攻击,把交通指示牌进行改变,使得自动驾驶系统会把它识别成错误的交通标志。这时需要保证改动不要太奇怪,比如就是贴几个小的patch就可以改变机器识别的结果。
四.Denfese
总得来说,有两大种防御方式,1.被动防御,主要是去处理被攻击的图片使得攻击效果失效;
2.主动防御,精华就在于要自己找到漏洞并补起来。
1.被动防御
形式:有很多,例如将输入的图片平滑化,加入一点点随机杂讯,做一点点平移旋转等等。
总之宗旨是,既然攻击是只有那几个特殊方向有效,那么我就随机再换个方向,那攻击就极大可能的被抵消了。
弱点:一旦我们这些内部的操作被泄露,我们的这些操作就相当于是一个更大的神经网络的一部分,从而再可以重新设计更新的攻击方式。
2.主动防御
方法:主要就是,我们去做一个T轮的循环,每次对每个输入都找出对应的弱点,之后针对这个弱点进行修补(修改对应的标签)即可。
当然无论如何修补,总是有一个新的方向可能会出漏洞,但是这样最起码对最初的训练数据的神经网络的攻击会失效。但是问题还是,如果我们知道了用这种方式进行防御,针对这种防御机制进行攻击,攻击还是会很有效果的;另外还有一个大问题,那就是如果攻击时用的方法和自我检测时不相同的话,我们依旧是防守不住的。
因此可见,对模型的防御确实一直是一个难点。
三.除了图像攻击 也有语音和文字的攻击
参考

若有收获,就点个赞吧
0 人点赞
