MSE(最小二乘损失函数)
回归
分类
分割
像素级的交叉熵损失(pixel-wise cross entropy loss)。 该损失单独地检查每个像素点,将类预测(深度方向的像素矢量)与one-hot编码的目标矢量进行比较。
交叉熵(Cross Entropy)

其中, 表示类别数,
表示类别数, 是一个
是一个one-hot向量,元素只有 和
和 两种取值,如果该类别和样本的类别相同就取
两种取值,如果该类别和样本的类别相同就取 ,否则取
,否则取 ,至于
,至于 表示预测样本属于
表示预测样本属于 的概率。
的概率。
交叉熵Loss可以用在大多数语义分割场景中,但它有一个明显的缺点,那就是对于只用分割前景和背景的时候,当前景像素的数量远远小于背景像素的数量时,即 的数量远大于
的数量远大于 的数量,损失函数中
的数量,损失函数中 的成分就会占据主导,使得模型严重偏向背景,导致效果不好。
的成分就会占据主导,使得模型严重偏向背景,导致效果不好。
- BCE loss
当类别数 等于
等于 的时候,这个损失就是二元交叉熵
的时候,这个损失就是二元交叉熵 ,在Pytorch中提供了一个单独的实现。
,在Pytorch中提供了一个单独的实现。
#二值交叉熵,这里输入要经过sigmoid处理import torchimport torch.nn as nnimport torch.nn.functional as Fnn.BCELoss(F.sigmoid(input), target)#多分类交叉熵, 用这个 loss 前面不需要加 Softmax 层nn.CrossEntropyLoss(input, target)
BCEWithLogitsLoss就是把Sigmoid-BCELoss合成一步
- Weighted cross entropy(WCE)
- Balanced cross entropy(BCE)
- Focal loss
focal loss是在目标检测领域提出来的。其目的是关注难例(也就是给难分类的样本较大的权重)。对于正样本,使预测概率大的样本(简单样本)得到的loss变小,而预测概率小的样本(难例)loss变得大,从而加强对难例的关注度。但引入了额外参数,增加了调参难度。
Overlap measures
**
- Dice Loss / F1 score
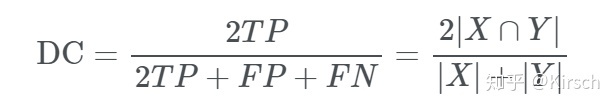

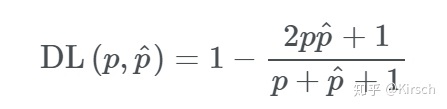
- IoU(Jaccard Index)
intersect over union,中文:交并比。指目标预测框和真实框的交集和并集的比例。
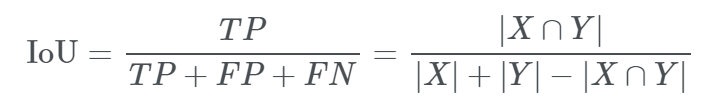


准确率(accuracy)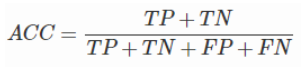

三大问题
类似于Dice loss,Dice>IoU.
图像分割评价标准

若有收获,就点个赞吧
0 人点赞
