目录
A High-Level Look

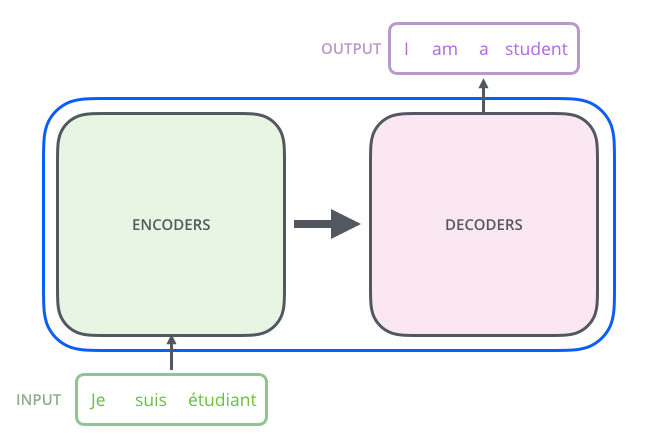
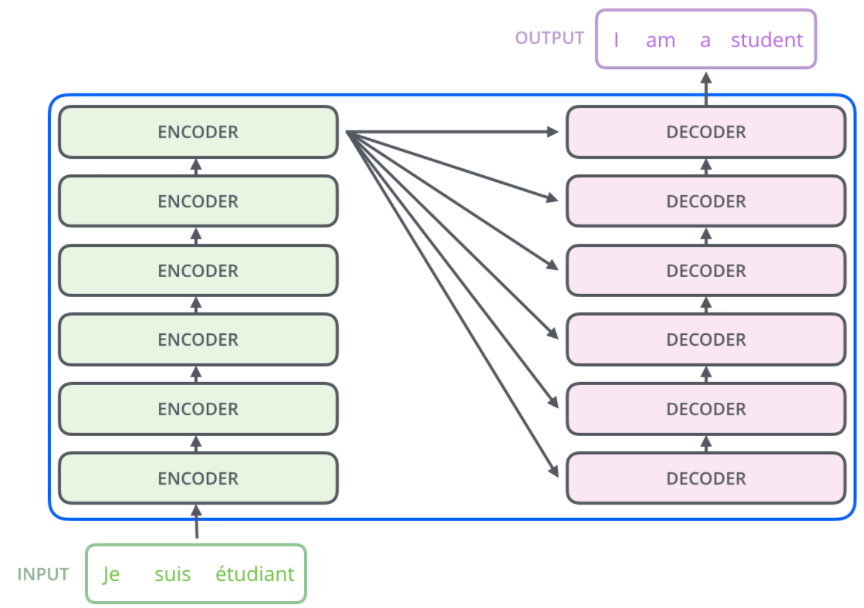
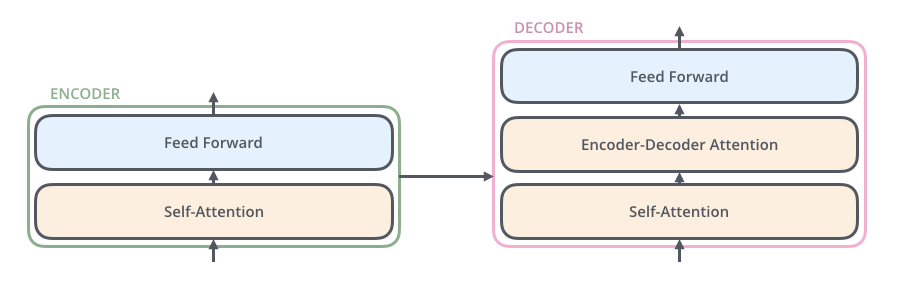
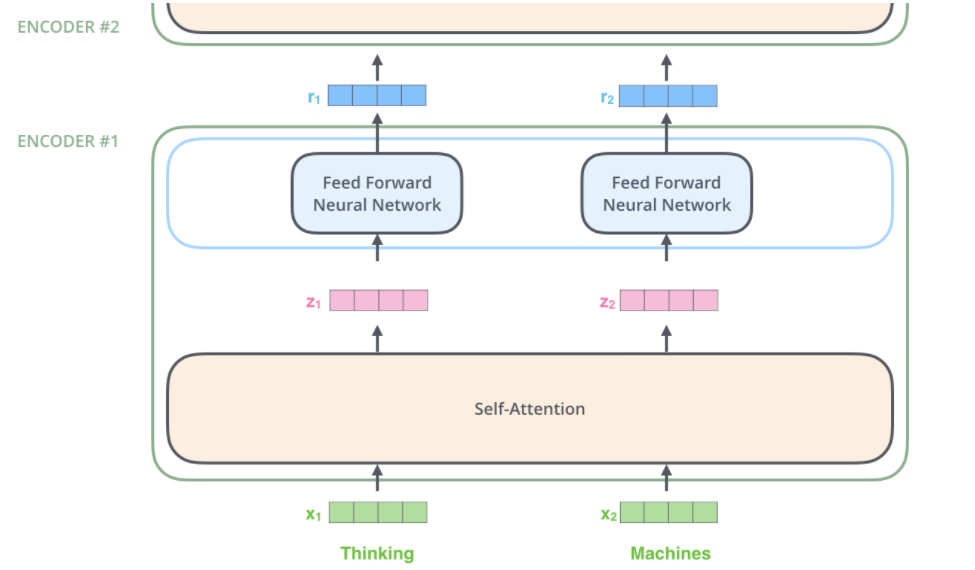

1.代码实现
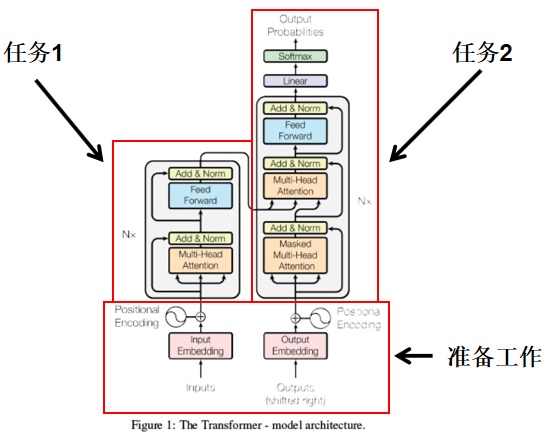
input Embedding[1,10,512]
Positional encoding:[1,10,512]->[1,10,512]
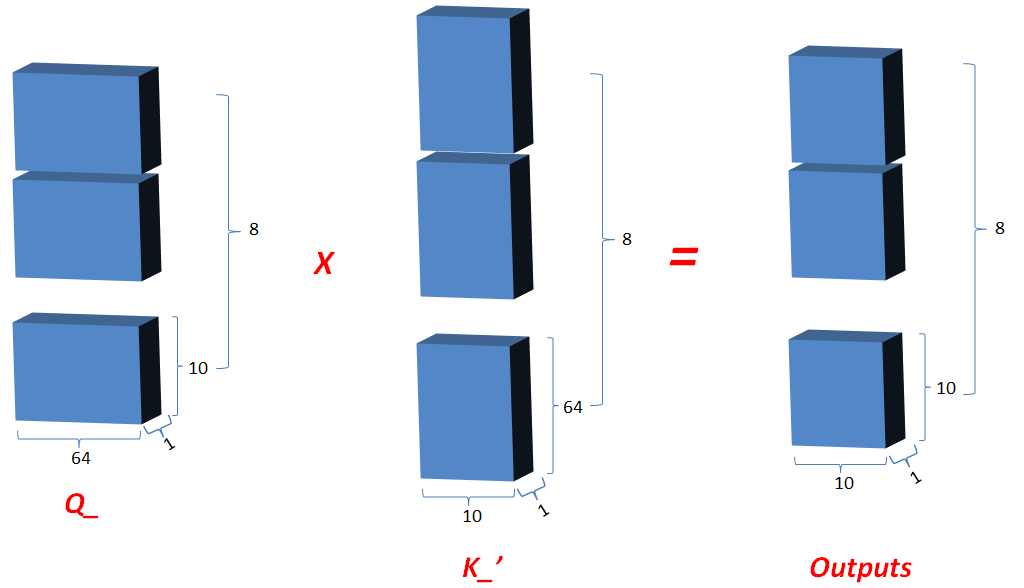
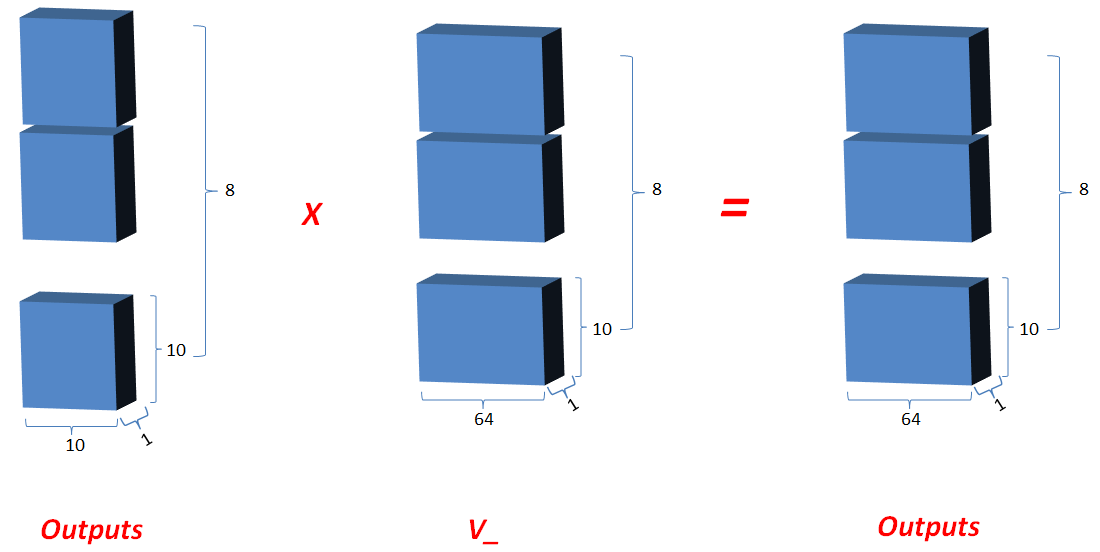
Multi-head attention:[1,10,512]->[8,10,64]->[1,10,512]
Add&norm:[1,10,512]->[1,10,512]
feedForward:[1,10,512]->[1,10,2048]->[1,10,512]
- Outputs:shifted right右移一位,是为了解码区最初初始化时第一次输入,并将其统一定义为特定值(在word2num中提前定义);[1,10,512]
2. Outputs embedding: 同编码部分;更新outputs;[1,10,512]->[1,10,512]
3. Positional embedding:[1,10,512]->[1,10,512]
Masked multi-head attention[1,10,512]->[1,10,512]
4.2 Add&norm:同编码部分,更新outputs;
4.3 Multi-head attention:同编码部分,但是Q和K,V不再相同,Q=outputs,K=V=matEnc;
4.4 Add&norm:同编码部分,更新outputs;
4.5 Feed-Forward:同编码部分,更新outputs;
4.6 Add&norm: 同编码部分,更新outputs;
4.7 最新outputs和最开始进入该循环时候的outputs的shape相同;
回到4.1,开始第 二次循环。。。;直到完成Nx次循环(自定义;每一次循环其结构相同,但对应的参数是不同的,即独立训练的);
5. Linear: 将最新的outputs,输入到单层神经网络中,输出层维度为“译文”有效单词总数;更新outputs;
6. Softmax: 对outputs进行softmax运算,确定模型译文和原译文比较计算loss,进行网络优化;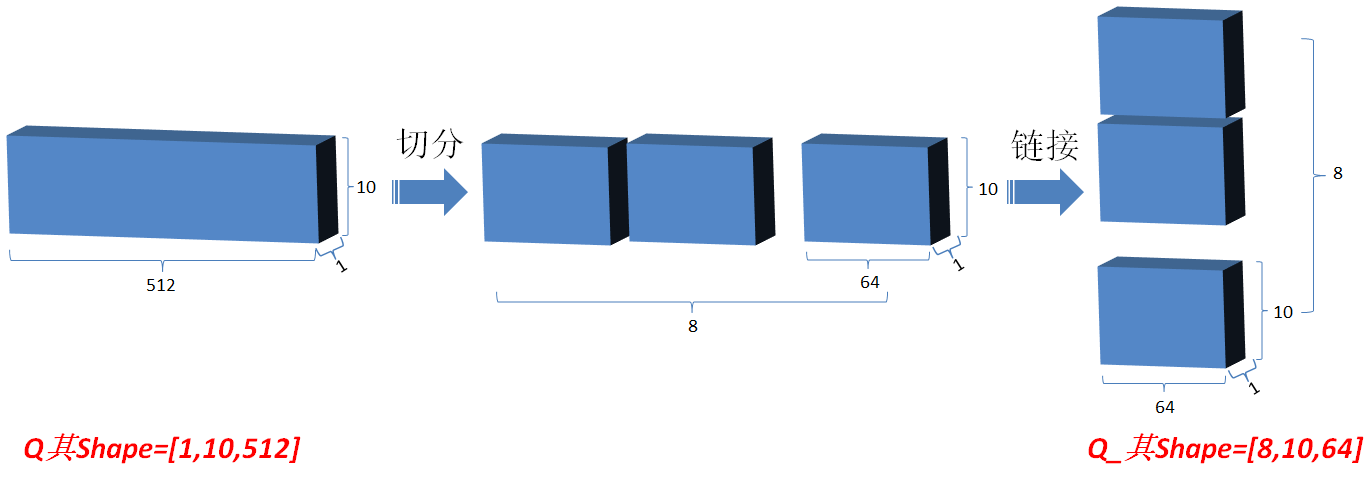
准备-Positional Encodings
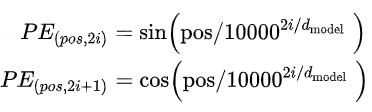
class PositionalEmbedding(nn.Module):def __init__(self, d_model, max_len=512):super().__init__()# Compute the positional encodings once in log space.pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1).float()div_term = torch.exp(torch.arange(0, d_model, 2).float() *-(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.weight = nn.Parameter(pe, requires_grad=False)def forward(self, x):return self.weight[:, :x.size(1), :] # (1, Seq, Feature)
细节-MultiHeadAttention

class ScaledDotProductAttention(nn.Module):def __init__(self, dropout=0.1):super().__init__()self.dropout = nn.Dropout(dropout)def forward(query, key, value, mask=None, dropout=None):d_k = key.size(-1) # get the size of the keyscores = torch.matmul(query, key.transpose(-2,-1))/math.sqrt(d_k)# fill attention weights with 0s where paddedif mask is not None: scores = scores.masked_fill(mask, 0)p_attn = F.softmax(scores, dim = -1)if dropout is not None:p_attn = dropout(p_attn)output = torch.matmul(p_attn, value)return output
class AttentionHead(nn.Module):"""A single attention head"""def __init__(self, d_model, d_feature, dropout=0.1):super().__init__()# We will assume the queries, keys, and values all have the same feature sizeself.attn = ScaledDotProductAttention(dropout)self.query_tfm = nn.Linear(d_model, d_feature)self.key_tfm = nn.Linear(d_model, d_feature)self.value_tfm = nn.Linear(d_model, d_feature)def forward(self, queries, keys, values, mask=None):Q = self.query_tfm(queries) # (Batch, Seq, Feature)K = self.key_tfm(keys) # (Batch, Seq, Feature)V = self.value_tfm(values) # (Batch, Seq, Feature)# compute multiple attention weighted sumsx = self.attn(Q, K, V)return xclass MultiHeadAttention(nn.Module):"""The full multihead attention block"""def __init__(self, d_model, d_feature, n_heads, dropout=0.1):super().__init__()self.d_model = d_modelself.d_feature = d_featureself.n_heads = n_heads# in practice, d_model == d_feature * n_headsassert d_model == d_feature * n_heads# Note that this is very inefficient:# I am merely implementing the heads separately because it is# easier to understand this wayself.attn_heads = nn.ModuleList([AttentionHead(d_model, d_feature, dropout) for _ in range(n_heads)])self.projection = nn.Linear(d_feature * n_heads, d_model)def forward(self, queries, keys, values, mask=None):x = [attn(queries, keys, values, mask=mask) # (Batch, Seq, Feature)for i, attn in enumerate(self.attn_heads)]# reconcatenatex = torch.cat(x, dim=Dim.feature) # (Batch, Seq, D_Feature * n_heads)x = self.projection(x) # (Batch, Seq, D_Model)return x
任务一—Encoder
单个Encoder block:
class EncoderBlock(nn.Module):def __init__(self, d_model=512, d_feature=64,d_ff=2048, n_heads=8, dropout=0.1):super().__init__()self.attn_head = MultiHeadAttention(d_model, d_feature, n_heads, dropout)self.layer_norm1 = LayerNorm(d_model)self.dropout = nn.Dropout(dropout)self.position_wise_feed_forward = nn.Sequential(nn.Linear(d_model, d_ff),nn.ReLU(),nn.Linear(d_ff, d_model),)self.layer_norm2 = LayerNorm(d_model)def forward(self, x, mask=None):att = self.attn_head(x, x, x, mask=mask)# Apply normalization and residual connectionx = x + self.dropout(self.layer_norm1(att))# Apply position-wise feedforward networkpos = self.position_wise_feed_forward(x)# Apply normalization and residual connectionx = x + self.dropout(self.layer_norm2(pos))return x
完整Encoder:6个Encoder block:
class TransformerEncoder(nn.Module):def __init__(self, n_blocks=6, d_model=512,n_heads=8, d_ff=2048, dropout=0.1):super().__init__()self.encoders = nn.ModuleList([EncoderBlock(d_model=d_model, d_feature=d_model // n_heads,d_ff=d_ff, dropout=dropout)for _ in range(n_blocks)])def forward(self, x: torch.FloatTensor, mask=None):for encoder in self.encoders:x = encoder(x)return x
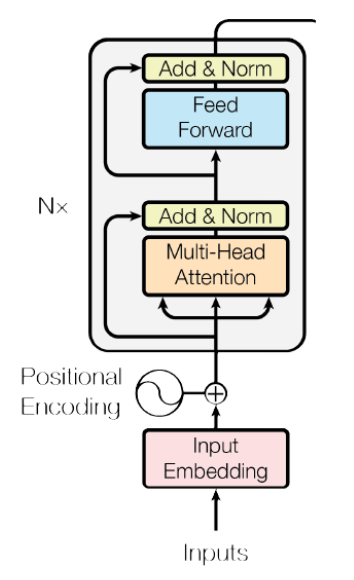
任务二—Decoder
单个DecoderBlock:
class DecoderBlock(nn.Module):def __init__(self, d_model=512, d_feature=64,d_ff=2048, n_heads=8, dropout=0.1):super().__init__()self.masked_attn_head = MultiHeadAttention(d_model, d_feature, n_heads, dropout)self.attn_head = MultiHeadAttention(d_model, d_feature, n_heads, dropout)self.position_wise_feed_forward = nn.Sequential(nn.Linear(d_model, d_ff),nn.ReLU(),nn.Linear(d_ff, d_model),)self.layer_norm1 = LayerNorm(d_model)self.layer_norm2 = LayerNorm(d_model)self.layer_norm3 = LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, enc_out,src_mask=None, tgt_mask=None):# Apply attention to inputsatt = self.masked_attn_head(x, x, x, mask=src_mask)x = x + self.dropout(self.layer_norm1(att))# Apply attention to the encoder outputs and outputs of the previous layeratt = self.attn_head(queries=att, keys=x, values=x, mask=tgt_mask)x = x + self.dropout(self.layer_norm2(att))# Apply position-wise feedforward networkpos = self.position_wise_feed_forward(x)x = x + self.dropout(self.layer_norm2(pos))return x
完整Decoder的实现:6个DecoderBlock:
class TransformerDecoder(nn.Module):def __init__(self, n_blocks=6, d_model=512, d_feature=64,d_ff=2048, n_heads=8, dropout=0.1):super().__init__()self.position_embedding = PositionalEmbedding(d_model)self.decoders = nn.ModuleList([DecoderBlock(d_model=d_model, d_feature=d_model // n_heads,d_ff=d_ff, dropout=dropout)for _ in range(n_blocks)])def forward(self, x: torch.FloatTensor,enc_out: torch.FloatTensor,src_mask=None, tgt_mask=None):for decoder in self.decoders:x = decoder(x, enc_out, src_mask=src_mask, tgt_mask=tgt_mask)return x
可视化
plt.figure(figsize=(15, 5))pe = PositionalEmbedding(20)y = pe.forward(Variable(torch.zeros(1, 100, 20)))plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())plt.legend(["dim %d"%p for p in [4,5,6,7]])None
训练
2.Detail
2.1background and motivation
在Transformer该论文提出之前,几乎所有主流的翻译模型或者NLP模型都是建立在复杂的循环神经网络(Recurrent Neural Network, RNN),包括其变体长短记忆RNN(LSTM)和门控循环单元(GRU),或卷积神经网络(Convolution Neural Network)seq2seq框架的基础上的。
递归神经网络(RNN),特别是长-短期记忆(LSTM)和门控递归神经网络(GRU),已经作为序列建模(如机器翻译,智能对话等)的最新方法被不断地探索。
nlp领域中rnn及cnn存在的以下问题:
•无法直接提取任意词语间的关联信息。rnn由于存在梯度消失问题,难以解决文本中长距离的依赖,而cnn则需要调节窗口大小来获取局部范围内的上下文信息。
•计算量较大,并行化程度较低。rnn本质上是一种串行结构,无法并行化,模型效率不高
Motivation:
•通过attention,抓长距离依赖关系比rnn强
•靠attention机制,不使用rnn和cnn,并行度高
2.2Positional Encodings
因为模型不包括recurrence/convolution,因此是无法捕捉到序列顺序信息的,例如将K、V按行进行打乱,那么Attention之后的结果是一样的。但是序列信息非常重要,代表着全局的结构,因此必须将序列的token相对或者绝对position信息利用起来。
这里每个token的position embedding 向量维度也是  然后将原本的input embedding和position embedding加起来组成最终的embedding作为encoder/decoder的输入。其中position embedding计算公式如下
然后将原本的input embedding和position embedding加起来组成最终的embedding作为encoder/decoder的输入。其中position embedding计算公式如下
其中  表示位置index,
表示位置index,  表示dimension index。
表示dimension index。
Position Embedding本身是一个绝对位置的信息,但在语言中,相对位置也很重要,Google选择前述的位置向量公式的一个重要原因是:由于我们有
这表明位置p+k的向量可以表示成位置p的向量的线性变换,这提供了表达相对位置信息的可能性。
在其他NLP论文中,大家也都看过position embedding,通常是一个训练的向量,但是position embedding只是extra features,有该信息会更好,但是没有性能也不会产生极大下降,因为RNN、CNN本身就能够捕捉到位置信息,但是在Transformer模型中,Position Embedding是位置信息的唯一来源,因此是该模型的核心成分,并非是辅助性质的特征。
也可以采用训练的position embedding,但是试验结果表明相差不大,因此论文选择了sin position embedding,因为
- 这样可以直接计算embedding而不需要训练,减少了训练参数
- 这样允许模型将position embedding扩展到超过了training set中最长position的position,例如测试集中出现了更大的position,sin position embedding依然可以给出结果,但不存在训练到的embedding。
2.3. Why Self-Attention
(1)卷积或循环神经网络难道不能处理长距离序列吗?
当使用神经网络来处理一个变长的向量序列时,我们通常可以使用卷积网络或循环网络进行编码来得到一个相同长度的输出向量序列,如图所示: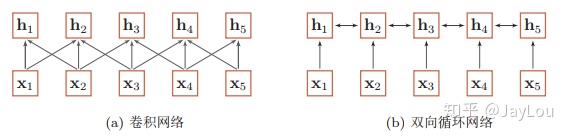 基于卷积网络和循环网络的变长序列编码
基于卷积网络和循环网络的变长序列编码
从上图可以看出,无论卷积还是循环神经网络其实都是对变长序列的一种“局部编码”:卷积神经网络显然是基于N-gram的局部编码;而对于循环神经网络,由于梯度消失等问题也只能建立短距离依赖。
(2)要解决这种短距离依赖的“局部编码”问题,从而对输入序列建立长距离依赖关系,有哪些办法呢?
如果要建立输入序列之间的长距离依赖关系,可以使用以下两种方法:一 种方法是增加网络的层数,通过一个深层网络来获取远距离的信息交互,另一种方法是使用全连接网络。 ——> 《神经网络与深度学习》
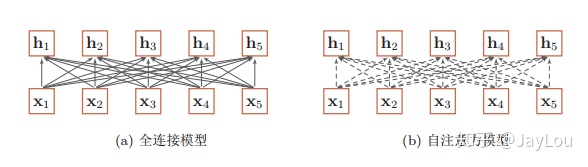 全连接模型和自注意力模型:实线表示为可学习的权重,虚线表示动态生成的权重。
全连接模型和自注意力模型:实线表示为可学习的权重,虚线表示动态生成的权重。
由上图可以看出,全连接网络虽然是一种非常直接的建模远距离依赖的模型, 但是无法处理变长的输入序列。不同的输入长度,其连接权重的大小也是不同的。
这时我们就可以利用注意力机制来“动态”地生成不同连接的权重,这就是自注意力模型(self-attention model)。由于自注意力模型的权重是动态生成的,因此可以处理变长的信息序列。
总体来说,为什么自注意力模型(self-Attention model)如此强大:利用注意力机制来“动态”地生成不同连接的权重,从而处理变长的信息序列。
**
这里将Self-Attention layers和recurrent/convolutional layers来进行比较,来说明Self-Attention的好处。假设将一个输入序列  分别用
分别用
- Self-Attention Layer
- Recurrent Layer
- Convolutional Layer
来映射到一个相同长度的序列  ,其中
,其中  .
.
我们分析下面三个指标:
- 每一层的计算复杂度
- 能够被并行的计算,用需要的最少的顺序操作的数量来衡量
- 网络中long-range dependencies的path length,在处理序列信息的任务中很重要的在于学习long-range dependencies。影响学习长距离依赖的关键点在于前向/后向信息需要传播的步长,输入和输出序列中路径越短,那么就越容易学习long-range dependencies。因此我们比较三种网络中任何输入和输出之间的最长path length

2.3.1 并行计算
Self-Attention layer用一个常量级别的顺序操作,将所有的positions连接起来
Recurrent Layer需要  个顺序操作
个顺序操作
2.3.2 计算复杂度分析
如果序列长度  表示维度
表示维度  ,Self-Attention Layer比recurrent layers快,这对绝大部分现有模型和任务都是成立的。
,Self-Attention Layer比recurrent layers快,这对绝大部分现有模型和任务都是成立的。
为了提高在序列长度很长的任务上的性能,我们对Self-Attention进行限制,只考虑输入序列中窗口为  的位置上的信息,这称为Self-Attention(restricted), 这回增加maximum path length到
的位置上的信息,这称为Self-Attention(restricted), 这回增加maximum path length到  .
.
2.3.3 length path
如果卷积层kernel width  ,并不会将所有位置的输入和输出都连接起来。这样需要
,并不会将所有位置的输入和输出都连接起来。这样需要  个卷积层或者
个卷积层或者  个dilated convolution,增加了输入输出之间的最大path length。
个dilated convolution,增加了输入输出之间的最大path length。
卷积层比循环层计算复杂度更高,是k倍。但是Separable Convolutions将见效复杂度。
同时self-attention的模型可解释性更好(interpretable).
3.2.1 缩放版的点积attention
两个最常用的attention函数是加法attention[2]和点积(乘法)attention。 除了缩放因子  之外,点积attention与我们的算法相同。 加法attention使用具有单个隐藏层的前馈网络计算兼容性函数。 虽然两者在理论上的复杂性相似,但在实践中点积attention的速度更快、更节省空间,因为它可以使用高度优化的矩阵乘法代码来实现。
之外,点积attention与我们的算法相同。 加法attention使用具有单个隐藏层的前馈网络计算兼容性函数。 虽然两者在理论上的复杂性相似,但在实践中点积attention的速度更快、更节省空间,因为它可以使用高度优化的矩阵乘法代码来实现。
当dk的值比较小的时候,这两个机制的性能相差相近,当dk比较大时,加法attention比不带缩放的点积attention性能好[3]。 我们怀疑,对于很大的dk值,点积大幅度增长,将softmax函数推向具有极小梯度的区域4。 为了抵消这种影响,我们缩小点积  倍。
倍。
2.3.4动手推导Self-attention
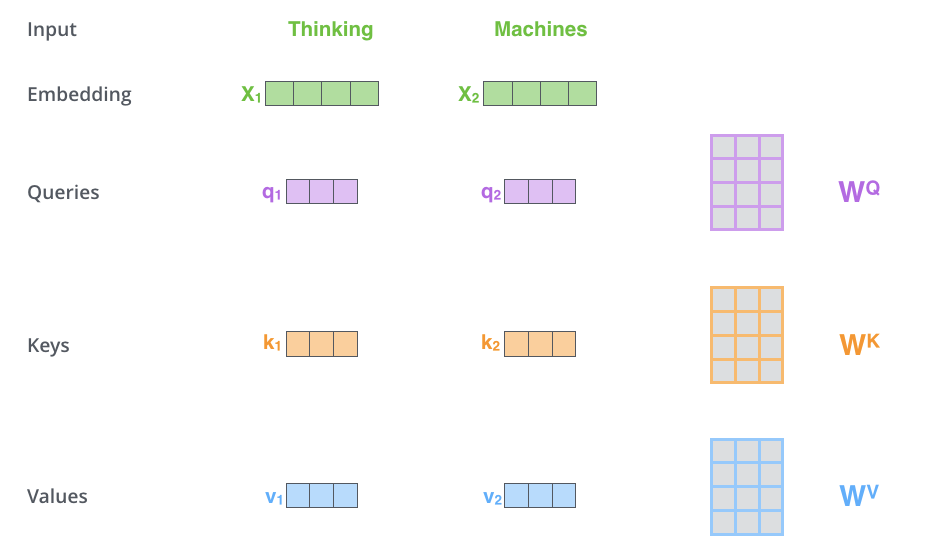
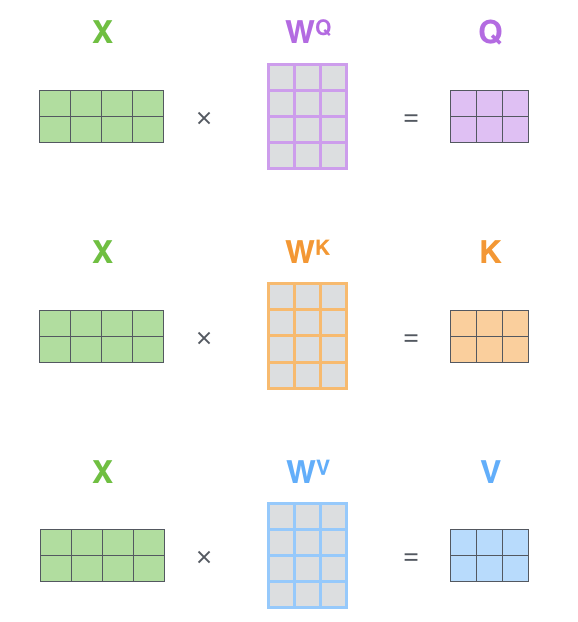
import torch#Step 1: 准备输入x = [[1, 0, 1, 0], # Input 1[0, 2, 0, 2], # Input 2]x = torch.tensor(x, dtype=torch.float32)#Step 2: 初始化权重w_query = [[1, 0, 1],[1, 0, 0],[0, 0, 1],[0, 1, 1]]w_key = [[0, 0, 1],[1, 1, 0],[0, 1, 0],[1, 1, 0]]w_value = [[0, 2, 0],[0, 3, 0],[1, 0, 3],[1, 1, 0]]w_query = torch.tensor(w_query, dtype=torch.float32)w_key = torch.tensor(w_key, dtype=torch.float32)w_value = torch.tensor(w_value, dtype=torch.float32)#Step 3:导出 query,key and value的表示querys = x @ w_querykeys = x @ w_keyvalues = x @ w_valueprint(querys)print(keys)print(values)

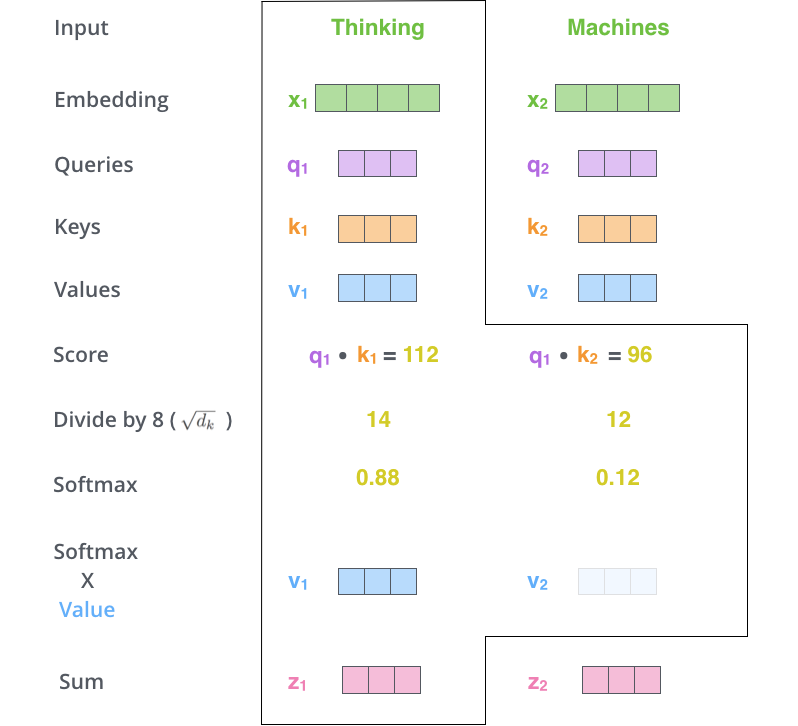
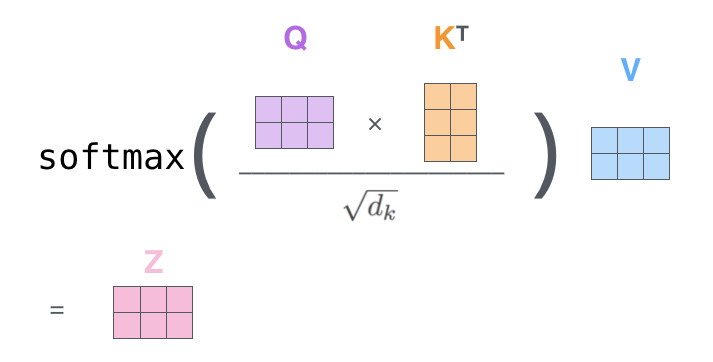
#Step 4: 计算输入的注意力得分(attention scores)attn_scores = querys @ keys.Tprint(attn_scores)# tensor([[ 2., 4.], # attention scores from Query 1# [ 4., 16.], # attention scores from Query 2#Step 5: 计算softmaxfrom torch.nn.functional import softmaxattn_scores_softmax = softmax(attn_scores, dim=-1)print(attn_scores_softmax)# tensor([[1.1920e-01, 8.8080e-01],# [6.1442e-06, 9.9999e-01]])# For readability, approximate the above as followsattn_scores_softmax = [[0.0, 0.5, 0.5],[0.0, 1.0, 0.0],[0.0, 0.9, 0.1]]attn_scores_softmax = torch.tensor(attn_scores_softmax)#Step 6: 将attention scores乘以valueweighted_values = values[:,None] * attn_scores_softmax.T[:,:,None]# tensor([[[0.0000, 0.0000, 0.0000],# [0.0000, 0.0000, 0.0000],# [0.0000, 0.0000, 0.0000]],## [[1.0000, 4.0000, 0.0000],# [2.0000, 8.0000, 0.0000],# [1.8000, 7.2000, 0.0000]],## [[1.0000, 3.0000, 1.5000],# [0.0000, 0.0000, 0.0000],# [0.2000, 0.6000, 0.3000]]])#Step 7: 对加权后的value求和以得到输出outputs = weighted_values.sum(dim=0)# tensor([[2.0000, 7.0000, 1.5000], # Output 1# [2.0000, 8.0000, 0.0000], # Output 2# [2.0000, 7.8000, 0.3000]]) # Output 3
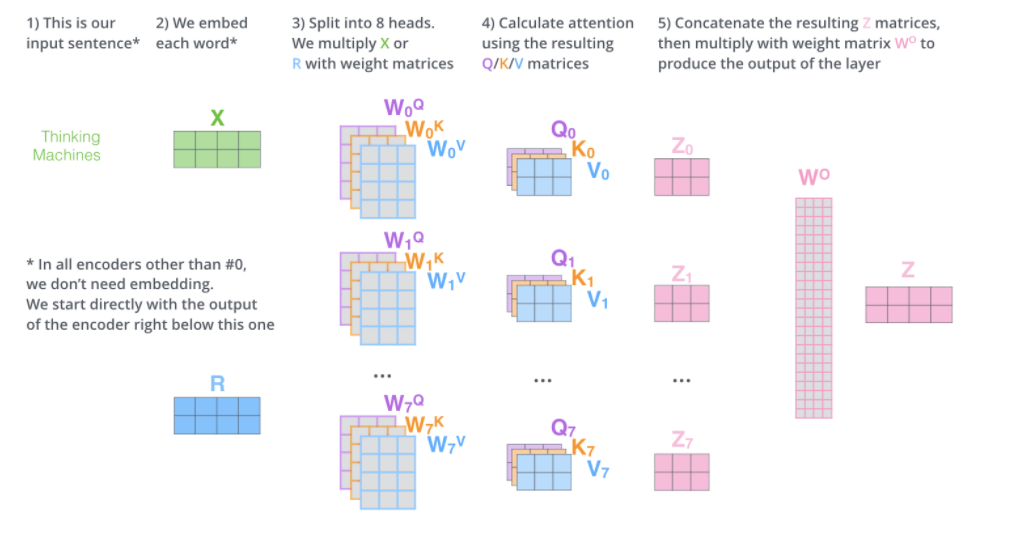
2.3.4self attention的多head策略
2.5Mask
链接:https://zhuanlan.zhihu.com/p/63191028
mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。其中,padding mask 在所有的 scaled dot-product attention 里面都需要用到,而 sequence mask 只有在 decoder 的 self-attention 里面用到。
Padding Mask
什么是 padding mask 呢?因为每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充 0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!而我们的 padding mask 实际上是一个张量,每个值都是一个Boolean,值为 false 的地方就是我们要进行处理的地方。
Sequence mask
文章前面也提到,sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
对于 decoder 的 self-attention,里面使用到的 scaled dot-product attention,同时需要padding mask 和 sequence mask 作为 attn_mask,具体实现就是两个mask相加作为attn_mask。
其他情况,attn_mask 一律等于 padding mask。
2.4Layer normalization
Normalization有很多种,但是它们都有一个共同的目的,那就是把输入转化成均值为0方差为1的数据。我们在把数据送入激活函数之前进行normalization(归一化),因为我们不希望输入数据落在激活函数的饱和区。
说到 normalization,那就肯定得提到 Batch Normalization。BN的主要思想就是:在每一层的每一批数据上进行归一化。我们可能会对输入数据进行归一化,但是经过该网络层的作用后,我们的数据已经不再是归一化的了。随着这种情况的发展,数据的偏差越来越大,我的反向传播需要考虑到这些大的偏差,这就迫使我们只能使用较小的学习率来防止梯度消失或者梯度爆炸。BN的具体做法就是对每一小批数据,在批这个方向上做归一化。如下图所示: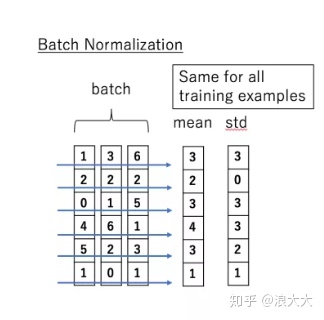
可以看到,右半边求均值是沿着数据 batch_size的方向进行的,其计算公式如下:
那么什么是 Layer normalization 呢?它也是归一化数据的一种方式,不过 LN 是在每一个样本上计算均值和方差,而不是BN那种在批方向计算均值和方差!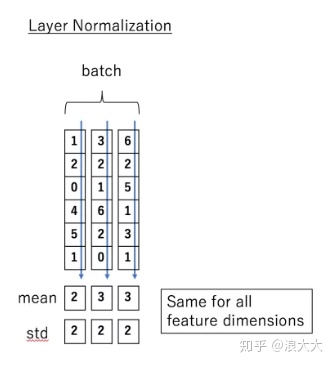
下面看一下 LN 的公式:
链接:https://zhuanlan.zhihu.com/p/63191028
2.5 Feed Forward
文章中使用Point-wise Feed-Forward Networks(FFN)来做Encoder和Decoder层的前馈网络,这是一个类似于卷积核大小为1*1,max-pooling的卷积算子,这样可以实现对每个点的参数都是独立和不同的。计算公式如下所示: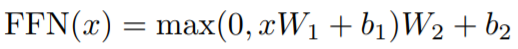
链接:https://zhuanlan.zhihu.com/p/40006082
3、other
3.1. 总结
优点:(1)虽然Transformer最终也没有逃脱传统学习的套路,Transformer也只是一个全连接(或者是一维卷积)加Attention的结合体。但是其设计已经足够有创新,因为其抛弃了在NLP中最根本的RNN或者CNN并且取得了非常不错的效果,算法的设计非常精彩,值得每个深度学习的相关人员仔细研究和品位。(2)Transformer的设计最大的带来性能提升的关键是将任意两个单词的距离是1,这对解决NLP中棘手的长期依赖问题是非常有效的。(3)Transformer不仅仅可以应用在NLP的机器翻译领域,甚至可以不局限于NLP领域,是非常有科研潜力的一个方向。(4)算法的并行性非常好,符合目前的硬件(主要指GPU)环境。
缺点:(1)粗暴的抛弃RNN和CNN虽然非常炫技,但是它也使模型丧失了捕捉局部特征的能力,RNN + CNN + Transformer的结合可能会带来更好的效果。(2)Transformer失去的位置信息其实在NLP中非常重要,而论文中在特征向量中加入Position Embedding也只是一个权宜之计,并没有改变Transformer结构上的固有缺陷。
链接:https://zhuanlan.zhihu.com/p/48508221
3.2Transformer在GPT和Bert等词向量预训练模型中具体是怎么应用的?有什么变化?
- GPT中训练的是单向语言模型,其实就是直接应用Transformer Decoder;
- Bert中训练的是双向语言模型,应用了Transformer Encoder部分,不过在Encoder基础上还做了Masked操作;
BERT Transformer 使用双向self-attention,而GPT Transformer 使用受限制的self-attention,其中每个token只能处理其左侧的上下文。双向 Transformer 通常被称为“Transformer encoder”,而左侧上下文被称为“Transformer decoder”,decoder是不能获要预测的信息的。
Reference
Attention Is All You Need 原始论文中英文对照翻译https://zhuanlan.zhihu.com/p/36699992
代码实现:全:http://nlp.seas.harvard.edu/2018/04/03/attention.html
部分:https://mlexplained.com/2017/12/29/attention-is-all-you-need-explained/
译文:https://zhuanlan.zhihu.com/p/126671976
代码理解:选取翻译情景,以模型训练为例解释整个过程https://zhuanlan.zhihu.com/p/44731789
动手推导Self-attention-原文http://jalammar.github.io/illustrated-transformer/
译文https://zhuanlan.zhihu.com/p/137578323
https://zhuanlan.zhihu.com/p/47282410

若有收获,就点个赞吧
0 人点赞
