手撸编译系统(一)
## 内容概要
- 1什么是编译系统,什么是Driver?
- 2编译系统在翻译代码的四个阶段都干了什么,分别要给Driver什么选项?
- 3汇编代码有哪两种格式,二者有什么区别?
- 4mov指令的简单介绍
- 5对于汇编文件和目标文件代码不一致的简单解释
- 6什么是库?静态库与动态库的区别?
7为什么编译系统分成4个部分?
参考文献
- 2<
> - 3<<自己动手构造编译系统>>
- 4what is a c library?
- 5create shared libraries with gcc
- 6Linux中的动态链接库和静态链接库是干什么的?
- 7where can you find c standard library?
- 8Preprocessor output
1. 什么是编译系统?
计算机系统是由硬件和软件组成的,它们共同工作来运行应用程序。计算机硬件只能识别由0和1组成的二进制代码,也即机器语言。因此,当我们写出一个如下的”Hello Word”源程序时,// hello.c#includeintmain() {printf(“Hello, World\n”);return0;}如果想要它能被计算机硬件执行,必须要将这个源文件(文本文件)转化为可执行文件(二进制文件),而编译系统就是完成这个转换的工具。在Unix系统上,从源文件到可执行文件的转化是由Driver完成的$ clang hello.c -o hello这里clang就是Driver,它读取源文件hello.c,并将其翻译为可执行文件hello,这个翻译过程可分为4个阶段,如下图所示  执行这四个阶段的程序(预处理器、编译器、汇编器、链接器)一起构成了编译系统,Driver就是驱动着这四个程序运行的工具。## 2. 四个阶段的工作
执行这四个阶段的程序(预处理器、编译器、汇编器、链接器)一起构成了编译系统,Driver就是驱动着这四个程序运行的工具。## 2. 四个阶段的工作2.1 预处理阶段
预处理器(cpp)根据以字符#开头的命令,修改原始的C程序,比如将被#include的头文件的插入,将宏展开,根据#ifdef进行代码选择等等。 在hello.c中,第一行的#include命令告诉预处理器读取系统头文件stdio.h的内容,并把它直接插入到程序文本中,结果就得到了另一程序,通常以.i作为扩展名。我们可以使用-E选项来让clang只跑预处理阶段$ clang hello.c -E -o hello.i// hello.i…extern intprintf(const char *restrict format, …);… #include <stdio.h>int main(){printf(“Hello, World\n”);return0;}## 2.2 编译阶段 编译器(cc1)将文本文件hello.i翻译成文本文件hello.s,对于clang而言,在将hello.i翻译成hello.s之前,还会将先翻译成LLVM IR。我们可以使用-S选项让clang跑到编译阶段$ clang hello.c -S -o hello.s# 也可以把输入换成hello.imain:# @mainpushq %rbpmovq %rsp, %rbpsubq$16, %rspmovl$0, -4(%rbp)movabsq $.L.str, %rdimovb$0, %alcallqprintfxorl %ecx, %ecxmovl %eax, -8(%rbp)# 4-byte Spillmovl %ecx, %eaxaddq$16, %rsppopq %rbpretq.L.str:.asciz”Hello, World\n”hello.s包含一个汇编语言程序,汇编语言以文本格式描述了低级机器指令,为不同的高级语言的不同编译器提供了通用的输出语言。clang默认生成的汇编代码的语法是ATT格式,如果想生成intel格式的汇编代码,可以使用参数-masm=intel。$ clang hello.c -S -masm=intel -o hello.s# 也可以把输入换成hello.imain:# @mainpush rbpmov rbp, rspsub rsp,16mov dword ptr[rbp -4],0movabs rdi, offset .L.strmov al,0callprintfxor ecx, ecxmov dword ptr[rbp -8], eax# 4-byte Spillmov eax, ecxadd rsp,16pop rbpret.L.str:.asciz”Hello, World\n”我们先介绍条指令movb $0, %al, 其中movb是mov指令的一个版本,mov指令是用来在寄存器和内存间传输数据,后缀b表示操作数的大小是1个byte,当然相应的还有movw、movl,movq分别对应操作数是1个word(16-bit),一个long word(32-bit)和一个quad word(64-bit)。$0是源操作数,%al是目标操作数,$前缀表示操作数是一个立即数。%表示操作数是一个寄存器,这里的$和%都称为操作数指示符。%al是一个8-bit的寄存器,其实也是64-bit寄存器%rax的低8位。movb $0, %al指令就表示将立即数0放入寄存器al中,对应的intel指令是mov al, 0,可以看出intel和ATT在如下方面有所不同:
- •intel代码省略了指示操作数大小的后缀
- •intel代码省略了立即数的前缀$,寄存器名的前缀%
- •intel的源操作数在后,目标操作数在前
类似的,movl $0, -4(%rbp)表示,将寄存器rbp中的值减去4的结果作为指向内存的地址,将立即数0放到那片内存中去。不难看出,其对应的C语言中的指针解引用(p-4)=0(p是一个指针)。相应的intel汇编代码是mov dword ptr [rbp - 4], 0,可以看出 intel代码用不同的方式描述内存中的位置,并且显式地使用ptr指出操作数是一片内存。## 2.3 汇编阶段
汇编器(as)将hello.s翻译成机器语言指令,把这些指令打包成可重定位目标文件。我们可以使用-c选项让clang运行到汇编阶段$ clang hello.c -c -o hello.o# 也可以把输入换成hello.i或hello.s目标文件是二进制文件,无法用文本编辑器直接查看,但是我们可以使用objdump命令分析它地内容$ objdump -sd hello.ohello.o: file format elf64-x86-64
Contents of section .rodata.str1.1:000048656c6c 6f20576f 726c640a00Hello World..
Disassembly of section .text:
0000000000000000:0:55push %rbp1:4889e5 mov %rsp,%rbp4:4883ec10sub$0x10,%rsp8: c745fc00000000movl$0x0,-0x4(%rbp)f:48bf0000000000movabs$0x0,%rdi16:00000019: b000mov$0x0,%al1b: e800000000callq20 :400db0: 55 push %rbp400db1: 48 89 e5 mov %rsp,%rbp400db4: 48 83 ec 10 sub $0x10,%rsp400db8: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)400dbf: 48 bf 90 f7 48 00 00 movabs $0x48f790,%rdi400dc6: 00 00 00400dc9: b0 00 mov $0x0,%al400dcb: e8 70 0d 00 00 callq 401b40 <_IO_printf>400dd0: 31 c9 xor %ecx,%ecx400dd2: 89 45 f8 mov %eax,-0x8(%rbp)400dd5: 89 c8 mov %ecx,%eax400dd7: 48 83 c4 10 add $0x10,%rsp400ddb: 5d pop %rbp400ddc: c3 retq400ddd: 0f 1f 00 nopl (%rax)可以发现,在汇编过程中的无法确定的符号地址信息都被修正为实际的符号地址。如”Hello World\n”的字符串地址为0x48f790,printf的地址为401b40。## 3. 库的简单介绍 3.1 C语言中的库是什么?
C语言中的库是一组函数、宏、结构体等提供了某些功能的代码的集合。这些功能的接口(就是暴露给user的东西)通常会放在头文件中,你想要使用这些功能就需要#include相应的头文件(譬如stdio.h就是标准输入输出库对应的头文件)。如果库提供源码的话,这些功能的实现通常会在对应的.c文件中(当然也有可能直接放在被#include的头文件里),库的代码会和你自己的代码一起经历预处理、编译、汇编、链接的过程。如果不提供源码的话,这些功能的实现就会被打包成一个单独的文件,直接作为链接器的输入的一部分。我们通常说库时,指的都是被打包的功能的实现,下面我们也会采用这种说法。## 3.2 库的分类 库通常分为两种:静态库和动态库,在Unix上分别对应.a和.so文件(在Windows上分别对应.lib和.dll文件)。库是直接作为链接器的输入的,因此静态和动态指的是两种链接方法,二者的区别这里会先做一个简单介绍,在后面实现链接器的时候我们会进行详细的剖析。
静态库是一组连接起来的可重定位目标文件(.o文件)的集合,我们称这种格式为存档(archive),存档有一个头部用来描述每个成员目标文件的大小和位置,存档文件名由.a标识。在链接时,链接器会复制被程序引用到的.o文件,将其与程序的.o文件一起打包到可执行文件中。譬如说,你可以在/usr/lib文件下找到libc.a文件,使用$ ar -t libc.a你可以看到它由很多.o文件组成,当你使用clang hello.c -static -o hello命令时,链接器便会复制其中的printf.o等模块到的部分到可执行文件hello中去。程序运行时,可执行文件会被加载到内存中,如下图所示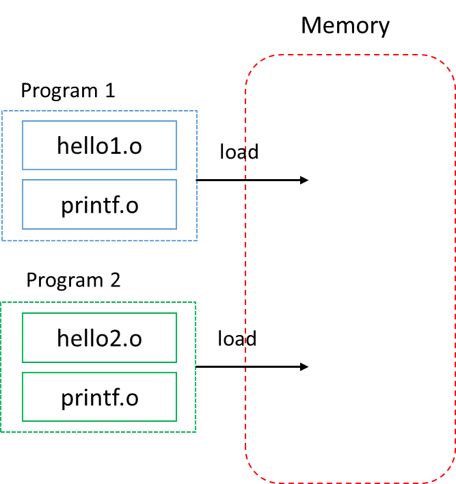
不难看出,静态库(.a文件)具有以下特点一旦可执行文件生成,就不再对库有依赖,也就是说只要developer有相应的库就好,user不需要浪费磁盘空间和内存,当多个程序都需要用到这个库时,该库在内存中会有多份拷贝 * 对程序的更新和发布带来麻烦,一旦静态库更新了,整个程序就需要重新链接生成一个新的可执行文件,用户想要更新就需要整个程序重新下载(全量更新)。为了解决上述问题,现代编译系统引入了动态库,链接器不会将动态库(.so文件)内的目标文件合并到可执行文件内,而仅仅记录动态库的路径信息。链接器可以在程序运行前才加载所需要的动态库,如果该动态库已加载到内存,则不需要重复加载。另外,链接器也可以将程序执行库函数调用的那一刻才进行动态库的加载。因此,磁盘和内存空间的浪费被避免了,并且如果动态库更新了,用户只需要更新该动态库即可(增量更新)。当然,动态库也有缺点 - •运行时链接的方式会增加程序执行的时间开销
- •动态库的版本错误可能会导致程序无法执行
4. 为什么要这么麻烦?
你可能会想,为什么不直接一步生成可执行文件,而是让分开进行预处理、编译、汇编、链接四个步骤呢?预处理只是将源文件进行修改,譬如头文件的插入,代码的选择,输出的.i文件中的代码基本都是C语言的语法(不是C语言的语法见Preprocessor output),然后编译器处理被展开后的C文件。因此,预处理器和编译器的分开是一个自然的、模块化的设计。汇编语言的每一条语句都以文本格式描述了一条低级机器语言指令,因此汇编语言不但为不同的高级语言的不同编译器提供了通用的输出语言,还能让我们间接地读懂机器实际执行的指令,所以我们需要将编译器和汇编器分开。为什么我们需要链接器呢?有了链接器,我们就可以把代码写在多个文件中,而不是一个单一文件的庞然大物。而可以把代码写在多个文件中可以带来很多好处。 - •首先,代码的复用更加方便(否则就要把需要功能的code复制到唯一的源文件中)。
- •其次,我们可以进行分离式编译,改变一个源文件后只需重新编译该源文件得到.o文件,再与其他.o文件链接即可,而不用重新编译其他源文件,节省了时间
- •再者,当我们实现了很多功能,但是程序只需要其中一部分的时候,我们可以只链接我们所需要用到的功能的代码所在的.o文件,这样需要加载到内存中的内容就变少了,节省了空间。
## 内容概要
- 1编译系统所支持的C语言子集介绍
- 2编译器的基本结构
- 3确定有限状态自动机(DFA)的定义
- 4词法分析器的结构
- 5扫描器(Scanner)和词法分析器(Lexer)的实现
-
参考文献
1<<自己手动构造编译系统>>
- 2Deterministic finite automaton
- 3how to clone all remote branches in git
- 4Google C++ Code Style
- 5clang-format
- 6Using Printf with Modern C++
- 7Error: format string is not a string literal
- 8define global variable in namespace
- 9C/C++的二进制字面值
- 10<<跟我一起写Makefile>>
- 11Ctrl + v + tab在vim中强制输入tab(不转化为空格)
- 12Really clear the terminalclear && printf ‘\e[3J’
1. 要实现的语言
在实现编译器之前,必须弄清楚编译器要处理什么样的语言,本系列文章所要撸的编译器想处理的是C语言的子集。词法记号是高级语言代码的基本单位,因此,C语言作为一门高级语言,其代码也是词法记号按照一定规则的组合。词法记号通常可以分为标识符、关键字、常量、界符(界符包含分隔符、运算符、空白符)四大类,高级语言的定义对词法记号的定义有直接影响。不同语言对标识符的定义不同,如Visual Basic不区分标识符的大小写C语言区分标识符的大小写;不同语言的关键字表也不尽相同,如在C语言内不存在C++的virtual关键字;不同语言的界符定义不同,PASCAL的赋值运算符为:=,而C语言的赋值运算符为=。我们所要支持的C语言子集如下:## 1.1 类型系统 支持int,char,void基本类型和一维指针、一维数组类型。涉及的词法记号有关键字int,char,void。## 1.2 常量 支持字符常量、字符串常量、2/8/10进制整数。涉及的词法记号有字符常量、字符串常量、数字常量(e.g.’c’、”Hello”、12)。## 1.3 运算符 支持加、减、乘、除、取模、取负、自加、自减算术运算;大于、大于等于、小于、小于等于、等于、不等于关系运算;或、与、非逻辑运算;赋值运算符,指针解引用运算符,取地址运算符,数组索引运算符。涉及的词法记号有+,-,,/,%,-,++,—,>,>=,<,<=,==,!=,&&,||,!,=,,&,[,]。注意,乘法运算符和指针解引用运算符是同一个词法记号,减法运算符和取负运算符是同一个词法记号。## 1.4 控制结构 支持do-while,while,for循环;if-else,switch-case条件分支;函数调用,return,break,continue语句。涉及的词法记号有do,while,for,if,else,switch,case,default,return,break,continue。## 1.5 声明与定义 支持extern变量声明,函数声明,变量、函数定义。涉及的词法记号有extern,(,),注意小括号也可能用来改变运算的结合顺序。## 1.6 分隔符 复合语句或函数体需要使用花括号包含起来,函数参数以逗号分隔,基本语句以分号结束,case和default关键字后使用冒号分割。涉及的词法记号有{,},,,;,:。## 1.7 其他 支持默认类型转换,单行和多行注释等。默认类型的转化属于代码生成部分的内容,注释不是有效的词法记号。不过除了以上提到的词法记号之外,还需要引入两个特殊的词法记号。err表示词法分析出错时返回的词法记号,词法分析器和语法分析器都会自动忽略这个词法记号;end表示文件结束。## 2. 编译器的结构 编译器是编译系统的核心,主要负责解析源程序的语义,生成汇编代码。一般情况下,编译流程包含词法分析、语法分析、语义分析和代码生成四个阶段。符号表管理和错误贯穿整个编译流程。如果编译器支持代码优化,那么还需要优化器模块。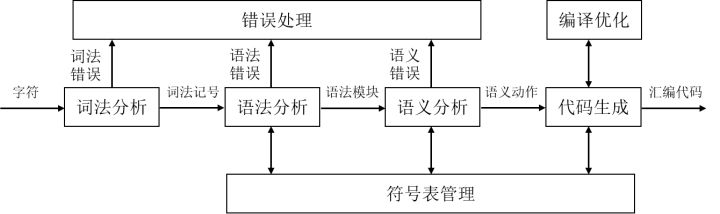 ## 3. 词法分析
词法分析时编译器处理流程中的第一步,它顺序扫描源文件内的字符,识别出各式各样的词法记号。为了理解这个过程,我们需要介绍一下确定有限状态自动机(DFA)的概念。## 3.1 确定有限状态自动机(DFA)
DFA从起始状态开始,一个字符接一个字符地读入字符串,并根据给定地转移函数一步一步地转移至下一个状态。在读完改字符串后,如果该DFA停在一个接受状态,它就接受该字符串,反之则拒绝该字符串。不难想到,对于一个给定的DFA,存在一个唯一的状态转换图与之对应。譬如说,下面的状态转换图就可以表示识别C语言标识符的DFA
## 3. 词法分析
词法分析时编译器处理流程中的第一步,它顺序扫描源文件内的字符,识别出各式各样的词法记号。为了理解这个过程,我们需要介绍一下确定有限状态自动机(DFA)的概念。## 3.1 确定有限状态自动机(DFA)
DFA从起始状态开始,一个字符接一个字符地读入字符串,并根据给定地转移函数一步一步地转移至下一个状态。在读完改字符串后,如果该DFA停在一个接受状态,它就接受该字符串,反之则拒绝该字符串。不难想到,对于一个给定的DFA,存在一个唯一的状态转换图与之对应。譬如说,下面的状态转换图就可以表示识别C语言标识符的DFA
## 3.2 词法分析器(Lexer)的结构 词法分析器(Lexer)可以分解成两个部分,从源文件按序扫描字符的为扫描器(Scanner),与有限自动机进行匹配产生词法记号的功能称为解析器。
## 3.3 扫描器的实现 本系列文章会采用Google C++ Code Style作为代码风格,使用clang-format作为格式化工具。扫描器使用80字节长度的缓冲区,每次先尝试从缓冲区读取字符,当缓冲区为空时,从源文件内加载续保的80字节到缓冲区,这样可以减少耗时的磁盘I/O操作。#pragma once#include”error.h”#include#include namespaceakan {classScanner{
staticvoidCloseFile(std::FILEfp) {if(fp) {std::fclose(fp);}}// Fileconstcharfilename=nullptr;std::uniqueptr
// Characters readstaticconstexprintbuflen=80;// Length of scan buffercharline[buf_len];
// Read statusintlinelen=0;// Length of current lineintreadpos=-1;// Read positioncharlastch=0;// Last character, used to judge the line break positionintlinenum=1;// Row Numberintcolnum=0;// Column Number// Debug helperstaticstd::string ShowChar(charch) {chars[16];switch(ch) {case-1:std::sprintf(s,”%s <%d>”,”EOF”, ch);break;case’\n’:std::sprintf(s,”%s <%d>”,”\n”, ch);break;case’\t’:std::sprintf(s,”%s <%d>”,”\t”, ch);break;case’ ‘:std::sprintf(s,”%s <%d>”,”blank”, ch);break;default:std::sprintf(s,”%c <%d>”, ch, ch);}returnstd::string(s);}public:Scanner(constcharname):filename(name), file(std::fopen(name,”r”),&CloseFile) {if(!file) {PrintCommonError(FATAL,”Fail to open the file %s! Please check filename and path.\n”,name);Error::IncrErrorNum();}}
Scanner(constScanner&)=delete;Scanner&operator=(constScanner&)=delete;~Scanner()=default;
// Scan characters from bufferintScan() {if(!file)return-1;if(read_pos==linelen-1) {linelen=fread(line,1, buf_len, file.get());// reload buffer dataif(line_len==0) {// no data// indicate end of filelinelen=1;line[0]=-1;last_ch=-1;return-1;}readpos=-1;// restore reading position}++readpos;charch=line[read_pos];// get the new charif(lastch==’\n’) {// start new line++linenum;colnum=0;}else{++colnum;}lastch=ch;returnch;}
// GetterconstcharGetFile()const{returnfilename; }intGetLine()const{returnlinenum; }intGetCol()const{returncolnum; }private:staticvoidTestImpl(constcharfile_name) {Scanner scanner(file_name);charch;do{ch=scanner.Scan();std::printf(“%8s\tline: %3d\tcol: %3d\n”, ShowChar(ch).c_str(),scanner.GetLine(), scanner.GetCol());}while(ch!=-1);std::printf(“Finish the scan for %s\n”, file_name);}public:staticvoidMainTest(intargc=0,charargv[]=nullptr) {TestImpl(“file/arithmetic.c”);}};}// namespace akan## 3.4 词法分析器的实现#pragma once#include”error.h”#include”scanner.h”#include”token.h”#include#include #include namespaceakan {classLexer{ private:std::sharedptrscanner ;charch=’ ‘;std::shared_ptrtoken ;
voidSkipWhiteSpace() {while(ch==’ ‘||ch==’\n’||ch==’\t’) {ch=scanner->Scan();}}
boolScan(charneed) {ch=scanner->Scan();if(ch==need)returntrue;elsereturnfalse;}
boolIsHexChar(charch) {returnstd::isdigit(ch)||(ch>=’A’&&ch<=’F’)||(ch>=’a’&&ch<=’f’);}
voidScan() {ch=scanner->Scan();return;}
voidTokenizeIdentifierOrKeywords() {std::string name;do{name.pushback(ch);// Eat one more character herech=scanner->Scan();}while(std::isalpha(ch)||ch==’‘);if(Keyword::IsKeyword(name)) {token=std::makeshared(name);}else{token =std::makeshared(name);}return;} ==’\‘) {Scan();switch(ch) {case’n’:str.push_back(‘\n’);break;case’\‘:str.push_back(‘\‘);break;case’t’:str.push_back(‘\t’);break;case’”‘:str.push_back(‘“‘);break;case’0’:str.push_back(‘\0’);break;case’\n’:break;case-1:// Eat one more character hereError::PrintLexicalError(STR_NO_R_QUOTE);token=std::makeshared
voidTokenizeString() {std::string str;while(!Scan(‘“‘)) {if(ch(ERR);return;default:str.push_back(ch );}}elseif(ch==’\n’||ch==-1) {// Eat one more character hereError::PrintLexicalError(STRNO_R_QUOTE);token=std::makeshared(ERR);return;}else{str.push_back(ch );}}token=std::make_shared(str);// Eat one more character hereScan();} !=0) {do{val=val10+ch-‘0’;// Eat one more character hereScan();}while(std::isdigit(ch));}else{Scan();// Hexadecimalif(ch==’x’) {Scan();if(IsHexChar(ch)) {do{val=val16+ch;if(std::isdigit(ch))val-=’0’;elseif(ch>=’A’&&ch<=’F’)val+=10-‘A’;elseif(ch>=’a’&&ch<=’f’)val+=10-‘a’;// Eat one more character hereScan();}while(IsHexChar(ch));}else{// Eat one more character hereError::PrintLexicalError(HEX_NUM_NO_ENTITY);token=std::makeshared
voidTokenizeNumber() {intval=0;// Decimalif(ch(ERR);return;}}// Binaryelseif(ch ==’b’) {Scan();if(ch>=’0’&&ch<=’1’) {do{val=val2+ch-‘0’;// Eat one more character hereScan();}while(ch>=’0’&&ch<=’1’);}else{// Eat oone more character hereError::PrintLexicalError(BI_NUM_NO_ENTITY);token=std::makeshared(ERR);return;}}// Octalelseif(ch >=’0’&&ch_<=’7’) {do{val=val8+ch-‘0’;// Eat one more character hereScan();}while(ch>=’0’&&ch<=’7’);}}token=std::makeshared(val);} =’\‘) {Scan();if(ch==’n’)c=’\n’;elseif(ch==’\‘)c=’\‘;elseif(ch==’t’)c=’\t’;elseif(ch==’0’)c=’\0’;elseif(ch==’\’’)c=’\’’;// End of file or line breakelseif(ch==-1||ch==’\n’) {// Eat one more character hereError::PrintLexicalError(CHAR_NO_R_QUOTE);token=std::makeshared
voidTokenizeCharacter() {Scan();charc;// Escape characterif(ch(ERR);return;}// Non-escape characterelsec=ch ;}elseif(ch==-1||ch==’\n’) {// Eat one more character hereError::PrintLexicalError(CHARNO_R_QUOTE);token=std::makeshared(ERR);return;}// No entityelseif(ch ==’\’’) {// Eat one more character hereError::PrintLexicalError(NOTSUPPORT_NULL_CHAR);token=std::makeshared(ERR);return;}// Non-escape characterelse{c=ch ;}if(Scan(‘\’’)) {token=std::make_shared(c);// Eat one more character hereScan();return;}else{// Eat one more character hereError::PrintLexicalError(CHAR_NO_R_QUOTE);token =std::makeshared(ERR);return;}} ) {// Ignore macrocase’#’:while(ch!=’\n’&&ch!=-1)// Eat one more character hereScan();break;case’+’:token=std::make_shared
voidTokenizeDelimiter() {switch(ch(Scan(‘+’)?INC : ADD);// Eat one more character hereScan();break;case’-‘:token =std::makeshared(Scan(‘-‘)?DEC : SUB);// Eat one more character hereScan();break;case’*’:token =std::makeshared(MUL);// Eat one more character hereScan();break;case’/‘:Scan();// Single-line commentif(ch ==’/‘) {while(ch!=’\n’&&ch!=-1) {// Eat one more character hereScan();}// make pointer null if match a commenttoken=nullptr;return;}// Multi-line commentelseif(ch==’‘) {while(!Scan(-1)) {if(ch_==’‘) {if(Scan(‘/‘))break;}}if(ch==-1) {// Eat one more character hereError::PrintLexicalError(COMMENT_NO_END);token=std::makeshared(ERR);return;}else{// Eat one more character hereScan();// make pointer null if match a commenttoken =nullptr;return;}}// Division operatorelse{token=std::make_shared(DIV);// Eat one more character hereScan();return;}case’%’:token =std::makeshared(MOD);// Eat one more character hereScan();break;case’>’:token =std::makeshared(Scan(‘=’)?GE : GT);// Eat one more character hereScan();break;case’<’:token =std::makeshared(Scan(‘=’)?LE : LT);// Eat one more character hereScan();break;case’=’:token =std::makeshared(Scan(‘=’)?EQU : ASSIGN);// Eat one more character hereScan();break;case’&’:token =std::makeshared(Scan(‘&’)?AND : LEA);// Eat one more character hereScan();break;case’|’:if(Scan(‘|’)) {token =std::makeshared(OR);// Eat one more character hereScan();return;}else{token =std::makeshared(ERR);// Eat one more character hereError::PrintLexicalError(OR_NO_PAIR);return;}case’,’:token =std::makeshared(COMMA);// Eat one more character hereScan();break;case’:’:token =std::makeshared(COLON);// Eat one more character hereScan();break;case’;’:token =std::makeshared(SEMICON);// Eat one more character hereScan();break;case’(‘:token =std::makeshared(LPAREN);// Eat one more character hereScan();break;case’)’:token =std::makeshared(RPAREN);// Eat one more character hereScan();break;case’[‘:token =std::makeshared(LBRACK);// Eat one more character hereScan();break;case’]’:token =std::makeshared(RBRACK);// Eat one more character hereScan();break;case’{‘:token =std::makeshared(LBRACE);// Eat one more character hereScan();break;case’}’:token =std::makeshared(RBRACE);// Eat one more character hereScan();break;case-1:token =std::makeshared(END);break;default:token =std::makeshared(ERR);// Eat one more character hereError::PrintLexicalError(TOKEN_NO_EXIST);}} (scanner) {Error::SetScanner(scanner);}Lexer(constLexer&)=delete;Lexer&operator=(constLexer&)=delete;~Lexer()=default;// All Tokenize function should eat one more character except that an error// occurs or scanner reaches the end of the file.std::sharedptrpublic:Lexer(std::shared_ptrscanner):scanner Tokenize() {// Use a loop here is to skip the comment and print out all lexical error.do{SkipWhiteSpace();if(std::isalpha(ch )||ch==’‘)TokenizeIdentifierOrKeywords();elseif(ch==’”‘)TokenizeString();elseif(std::isdigit(ch))TokenizeNumber();elseif(ch==’\’’)TokenizeCharacter();elseTokenizeDelimiter();if(token&&token->GetTag()!=ERR)returntoken;}while(ch_!=-1);returnstd::make_shared(END);} private:// Debug helperstaticvoidTestImpl(constcharfile_name) {Lexer lexer(std::make_shared(file_name));std::shared_ptr argv[]=nullptr) {TestImpl(“file/arithmetic.c”);printf(“\n”);TestImpl(“file/intended_error.c”);}};}// namespace akan## 完整代码链接 Build-Your-Own-Compile-Systemtoken;do{token=lexer.Tokenize();std::printf(“%10s\t”, Token::GetTagName(token->GetTag()).c_str());std::fflush(stdout);std::printf(“%20s\n”, token->ToString().c_str());std::fflush(stdout);}while(token->GetTag()!=END);std::printf(“Finish the lex for %s\n”, file_name);} public:staticvoidMainTest(intargc=0,char

若有收获,就点个赞吧
0 人点赞
