RetinaFace 的主要贡献

尽管在不受控制的人脸检测方面已取得了长足的进步,但是在 wilder 数据集进行准确有效的面部定位仍然是一个公开的挑战。本文提出了一种鲁棒的 single stage 人脸检测器,名为 RetinaFace,它利用 额外监督(extra-supervised)和自监督(self-supervised)结合的多任务学习(multi-task learning),对不同尺寸的人脸进行像素级定位。具体来说,我们在以下五个方面做出了贡献:(1)我们在 WILDER FACE 数据集中手工标注了 5 个人脸关键点(Landmark),并在这个额外的监督信号的帮助下,观察到在 hard face 检测的显著改善。(2)进一步添加自监督网络解码器(mesh decoder)分支,与已有的监督分支并行预测像素级的 3D 形状的人脸信息。(3)在 WIDER FACE 的 hard 级别的测试集中,RetinaFace 超出 the state of the art 平均精度(AP) 1.1%(达到 AP=91.4%)。(4)在 IJB-C 测试集中,RetinaFace 使 state of the art 方法(Arcface)在人脸识别中的结果得到提升(FAR=1e6,TAR=85.59%)。(5)采用轻量级的 backbone 网络,RetinaFace 能在单个 CPU 上实时运行 VGA 分辨率的图像。
FAR(False Accept Rate) 表示错误接受的比例
TAR(True Accept Rate) 表示正确接受的比例
VGA 分辨率 320*240,目前主要应用于手机及便携播放器上
人脸自动定位对许多应用而言都是人脸图像分析的前提步骤,例如人脸属性分析(比如表情,年龄)和人脸识别。人脸定位的狭义定义可以参考传统的人脸检测,其目的在没有任何尺度和位置先验的条件估计人脸边界框。然而,本文提出的人脸定位的广义定义包括人脸检测、人脸对齐、像素化人脸解析(pixel-wise face parsing)和三维密集对应回归(3D dense correspondence regression)。 这种密集的人脸定位为所有不同的尺度提供了精确的人脸位置信息。受到一般目标检测方法的启发,即融合了深度学习的最新进展,人脸检测最近取得了显著进展。与一般的目标检测不同,人脸检测具有较小的比例变化 (从 1:1 到 1:1.5),但更大的尺度变化 (从几个像素到数千像素)。 目前 most state-of-the-art 的方法集中于 single-stage 设计,该设计密集采样人脸在特征金字塔上的位置和尺度,与 two-stage 方法相比,表现出良好的性能和更快的速度。在此基础上,我们改进了 single-stage 人脸检测框架,并利用强监督和自监督信号的多任务损失,提出了一种 most state-of-the-art 的密集人脸定位方法。我们的想法如图 1 所示。
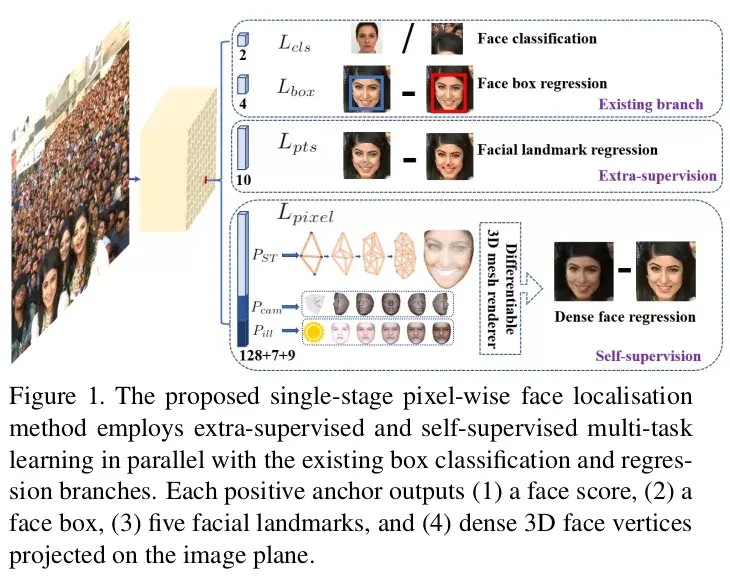
image.png
通常,人脸检测训练过程包含分类和框回归损失。chen 等人观察到对齐人脸能为人脸分类提供更好的特征,建议在联合级联框架中结合人脸检测和对齐。由此启发,MTCNN 和 STN 同时检测人脸和五个人脸 landmark。由于训练数据的限制,JDA、MTCNN 和 STN 还没有验证微小的人脸检测是否可以从额外的五个人脸 Landmark 的监督中获益。我们在本文中所要回答的问题之一是,能否利用由 5 个人脸关键点构成的额外监督信号,在 WIDER FACE 的 hard 测试集上推进目前最好的性能 (90.3%)。 在 Mask R-CNN 中,通过添加一个用于预测目标 Mask 的分支,与现有的用于边界框识别和回归的分支并行,显著提高了检测性能。这证实了密集的像素级标注也有助于改进检测。遗憾的是,对于具有挑战性的人脸数据集 WIDER FACE,无法进行密集的人脸标注 (以更多的 Landmark 或语义分割)。由于有监督的信号不易获得,问题是我们能否应用无监督的方法进一步提高人脸检测。 在 FAN 中,提出了一种 anchor-level 注意力图(attention map)来改进遮挡人脸检测。然而,所提出的注意力图相当粗糙,不包含语义信息。近年来,自监督三维形态模型在 wilder 实现了很有前景的三维人脸建模。特别是 Mesh decoder 利用节点形状和纹理上的图卷积实现了超实时速度。然而, 应用 mesh decoder 到 single-stage 检测的主要挑战是:_(1) 相机参数难以准确去地估计 , (2) 联合潜在形状和纹理表示是从单个特征向量(特征金字塔上的 1_1 Conv)而不是 RoI 池化的特征预测,这意味着特征转换的风险*。本文采与现有监督分支并行的用网格解码器(mesh decoder)通过自监督学习预测像素级的三维人脸形状。综上所述,我们的主要贡献如下:
- 在 single-stage 设计的基础上,提出了一种新的基于像素级的人脸定位方法 RetinaFace,该方法采用多任务学习策略,同时预测人脸评分、人脸框、五个人脸关键点以及每个人脸像素的三维位置和对应关系。
- 在 WILDER FACE hard 子集上,RetinaFace 的性能比目前 the state of the art 的 two-stage 方法 (ISRN) 的 AP 高出 1.1% (AP 等于 91.4%)。
- 在 IJB-C 数据集上,RetinaFace 有助于提高 ArcFace 的验证精度 (FAR=1e-6 时 TAR 等于 89:59%)。这表明更好的人脸定位可以显著提高人脸识别。
- 通过使用轻量级 backbone 网络,RetinaFace 可以在 VGA 分辨率的图片上实时运行
- 已经发布了额外的注释和代码,以方便将来的研究
图像金字塔 vs . 特征金字塔: 滑动窗口范例,其中分类器应用于密集的图像网格,可以追溯到过去的几十年。Viola-Jones 是里程碑式工作,它探索了级联结构,实时有效地从图像金字塔中剔除假人脸区域,使得这种尺度不变的人脸检测框架被广泛采用。尽管图像金字塔上的滑动窗口是主要的检测范式,随着特征金字塔的出现,多尺度特征图上的滑动 anchor 迅速主导了人脸检测。**Two-stage vs single-stage: 目前的人脸检测方法继承了一般目标检测方法的一些成果,可分为两类:Two-stage 方法 (如 Faster R-CNN) 和 single-stageTwo-stage(如 SSD 和 RetinaNet)。Two-stage 方法采用了一种具有高定位精度的 “proposal 与细化” 机制。相比之下,single-stage 方法密集采样人脸位置和尺度,导致训练过程中 positive 和 negative 样本极不平衡。 为了解决这种不平衡,广泛采用了采样(Training region-based object detectors with online hard example mining)和重加权 (re-weighting) 方法。 与 two-stage 方法相比,single-stage 方法效率更高,召回率更高,但存在假阳性率更高和定位准确性降低的风险。Context Modelling:** 提升模型的上下文模块推理能力以捕获微小人脸,SSH 和 PyramidBox 在特征金字塔上用 context modules 扩大欧几里德网格的感受野。为了提高 CNNs 的非刚性变换建模能力,可变形卷积网络 (deformable convolution network, DCN) 采用了一种新的可变形层对几何变换进行建模。WILDER FACE 2018[冠军方案]表明,对于提高人脸检测的性能而言,刚性 (expansion) 和非刚性 (deformation) 上下文建模是互补和正交的(orthogonal)。
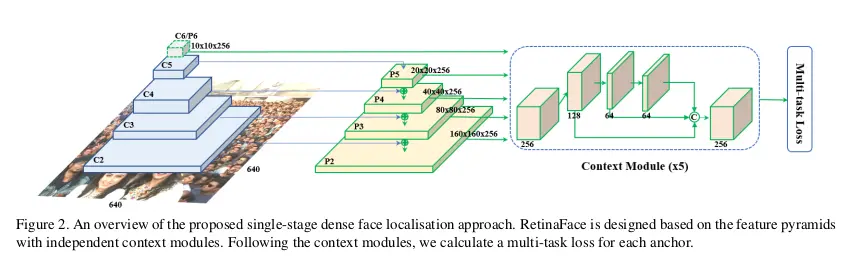
image
多任务学习: 在目前广泛使用的方案是结合人脸检测和人脸对齐,对齐后的人脸形状为人脸分类提供了更好的特征。在 Mask R-CNN 中,通过添加一个并行分支来预测目标 Mask,显著提高了检测性能。Densepose 采用 Mask-RCNN 的结构,在每个选定区域内获得密集的 part 标签和坐标。然而,[20,1]中的 dense 回归分支是通过监督学习训练的。此外,dense 分支是一个小的 FCN 应用于每个 RoI 预测像素到像素的密集映射。
3.1. Multi-task Loss
对于任何训练的 anchor i,我最小化下面的多任务的 loss:
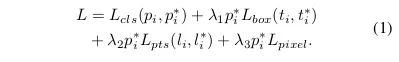
image
(1)人脸分类 loss Lcls(pi,pi),这里的 pi 是 anchor i 为人脸的预测概率,对于 pi * 是 1 是 positive anchor,0 代表为 negative anchor。分类 loss Lcls 是 softmax loss 在二分类的情况(人脸 / 非人脸)。(2)人脸框回归 loss,Lbox(ti,ti),这里的 ti={tx,ty,tw,th},ti ={tx ,ty ,tw ,th } 分别代表 positive anchor 相关的预测框和真实框(ground-truth box)的坐标。我们按照 [16]对回归框目标(中心坐标,宽和高)进行归一化,使用 Lbox(ti,ti )=R(ti-ti ),这里 R 是 Robust loss function(smooth-L1)(参考文献 16 中定义)(3)人脸的 landmark 回归 loss Lpts(li,li ),这里 li={l x1,l y1,…l x5,l y5},li \={l x1 ,l y1 ,…l x5 ,l y5 _} 代表预测的五个人脸关键点和基准点(ground-truth)。五个人脸关键点的回归也采用了基于 anchor 中心的目标归一化。(4)Dense 回归 loss Lpixel (参考方程 3)。loss 调节参数 λ1-λ3 设置为 0.25,0.1 和 0.01,这意味着在监督信号中,我们增加了边界框和关键点定位的重要性。3.2. Dense Regression Branch**Mesh Decoder:我们直接使用[70,40]中的网格解码器 (mesh convolution and mesh up-sampling) ,这是一种基于快速局部谱滤波的图卷积方法。为了实现进一步的加速,我们还使用了类似于[70]中方法的联合形状和纹理解码器,而不是只解码形状的。下面我们将简要解释图卷积的概念,并概述为什么它们可以用于快速解码。如图 3(a)所示,二维卷积运算是欧几里德网格感受野内的 “核加权邻域加和”。同样,图卷积也采用了图 3(b) 所示的相同概念。然而,邻域距离是通过计算连接两个顶点的最小边数来计算的*。我们遵循[70]来定义一个着色的脸部网格(mesh)G=(ν, ε), 其中ν∈R ^(n_6) 是一组包含联合形状和纹理信息的人脸顶点集合, ε∈{0,1}^(n n) 是一个稀疏邻接矩阵,它编码了顶点之间的连接状态。图拉普拉斯行列式定义为 L = D - ε ∈R ^(n n),D ∈ R ^(n n) 其中是一个对角矩阵 。

image.png
遵循[10,40,70 ], 图卷积的内核 g0 可以表示为 K 项的递归切比雪夫(Chebyshev)多项式
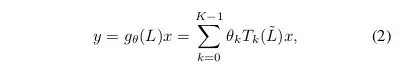
image.png
这里θ ∈ R^K 是一个切比雪夫系数向量,Tk∈ R^(n * n) 是在缩放的拉普拉斯中(L~)中评估 K 项的切比雪夫多项式。

image.png

image.png
其中 W 和 H 分别表示 anchor crop I*i,j 的宽度和高度。
4.1. Dataset
WIDER FACE 数据集包括 32203 幅图像和 393703 个人脸边界框,在尺度、姿态、表情、遮挡和光照方面具有高度差异性。通过随机抽取 61 个场景类别,将 WIDER FACE 数据集分为训练 (40%)、验证(10%) 和测试 (50%) 子集。基于 EdgeBox 的检测率,通过逐步合并困难样本来定义三个难度等级(Easy、Medium 和 Hard)。额外的标注: 见图 4 和表 1, 我们定义五个级别的脸图像质量 (根据在人脸上的难度去标注 Landmark) 并在 WIDER FACE 的训练和验证子集上标注五个人脸 Landmark(即眼中心, 鼻子和嘴角)。我们总共在训练集上标注了84.6k 个人脸,在验证集上标注了18.5k 个人脸。

image.png
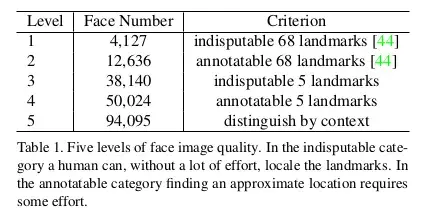
image.png
4.2. Implementation details
特征金字塔: RetinaFace 采用从 P2 到 P6 的特征金字塔层,其中 P2 到 P5 通过使用自顶向下和横向连接(如[28,29])计算相应的 ResNet 残差阶段 (C2 到 C5) 的输出。P6 是在 C5 处通过一个步长 2 的 3x3 卷积计算得到到。C1-C5 是在 ImageNet-11k 数据集上预先训练好的 ResNet-152[21]分类网络,P6 是用 “Xavier” 方法[17]随机初始化的。上下文模块: 受 SSH [36] 和 PyramidBox [49]启发, 我们 还在五个特征金字塔层应用单独的上下文模块来提高 感受野并增加刚性上下文建模的能力。从 2018 年 WIDER Face 冠军方案中受到的启发, 我们也在横向连接和使用可变形卷积网络(DCN)的上下文模块中替换所有 3x3 的卷积,进一步加强非刚性的上下文建模能力。 Loss Head:**对于negative acnhors,只应用分类损失。对于positive anchors,计算了多任务损失。我们使用 一 个跨越不同特征图,**

image.gif
,n∈{2,…6} 的共享 loss head (1x1 conv); 对于网格解码器 (mesh decoder),我们采用了预训练模型,这是一个很小的计算开销,允许有效的推理。 Anchor 设置:*_如表 2 所示,我们在特性金字塔层 (从 P2 到 P6) 上使用特定于尺度的 anchor,类似[56]。在这里,P2 被设计成通过平铺小 anchor 来捕捉微小的人脸,这样做的代价是花费更多的计算时间和更多的误报风险。我们将 scale step 设置为 2^(1/3),aspect ratio 设置为 1:1。输入图像大小为 640_640 , anchors 可以 覆盖 从 16x16 到 406x406 的特征金字塔层。总共有 102300 个 anchors,其中 75% 来自 P2。
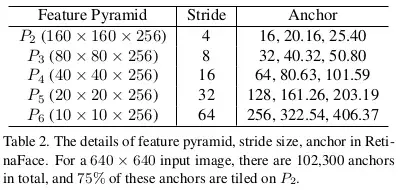
image.png
在训练过程中,当 IoU 大于 0.5 时,anchors 匹配到 ground-truth box,当 IoU 小于 0.3 时匹配到 background。不匹配的 anchor 在训练中被忽略。由于大多数 anchor(> 99%) 在匹配步骤后为负,我们采用标准 OHEM 来缓解正、负训练样本之间的显著不平衡。更具体地说,我们根据损失值对负锚进行排序,并选择损失最大的 anchors,这样负样本和正样本之间的比例至少为 3:1。数据增强: 由于 WIDER FACE 训练集中大约 有 20% 的小人脸 , 我们 遵循 [68, 49 ) 并从原始图像随机 crop 方形 patches 并调整这些 patches 到 640_640 产生更大的训练人脸。更具体地说,在原始图像的短边[0.3,1]之间随机裁剪正方形 patches。对于 crop 边界上的人脸,如果人脸框的中心在 crop patches 内,则保持人脸框的重叠部分。除了随机裁剪,我们还通过 0.5 概率的随机水平翻转和光度颜色蒸馏来增加训练数据[68]。训练细节:我们早四个 NVIDIA Tesla P40 (24GB) GPUs 上使用 SGD 优化器 (momentum 为 0.9, 权重衰减为 0.0005, batch size 为 8_4 ) 训练 RetinaFace 。学习速率从 10e-3, 在 5 个 epoch 后上升到 10e-2,然后在第 55 和第 68 个 epochs 时除以 10。训练过程在第 80 个 epochs 结束。测试细节: 对于 WIDER FACE 的测试,我们遵循[36,68]的标准做法,采用 flip 以及多尺度 (图像的短边在[500, 800, 1100, 1400, 1700]) 策略。使用 IoU 阈值为 0.4,将 Box voting[15]应用于预测的人脸 boxes 的并集。4.3. Ablation Study省略4.4. Face box AccuracyRetinaFace 与其他 24 个 stage-of-the-art 的人脸检测算法对比。RetinaFace 在所有的验证集和测试集都达到的最好的 AP,在验证集上的 AP 是 96.9%(easy),96.1%(Medium)和 91.8%(hard)。在测试集的 AP 是 96.3%,95.6%,91.4%. 相比与当前最好的方法 (Improved selective refinement network for face detection) 在困难的数据集(包含大量的小人脸)的 AP 对比(91.4% vs 90.3%)
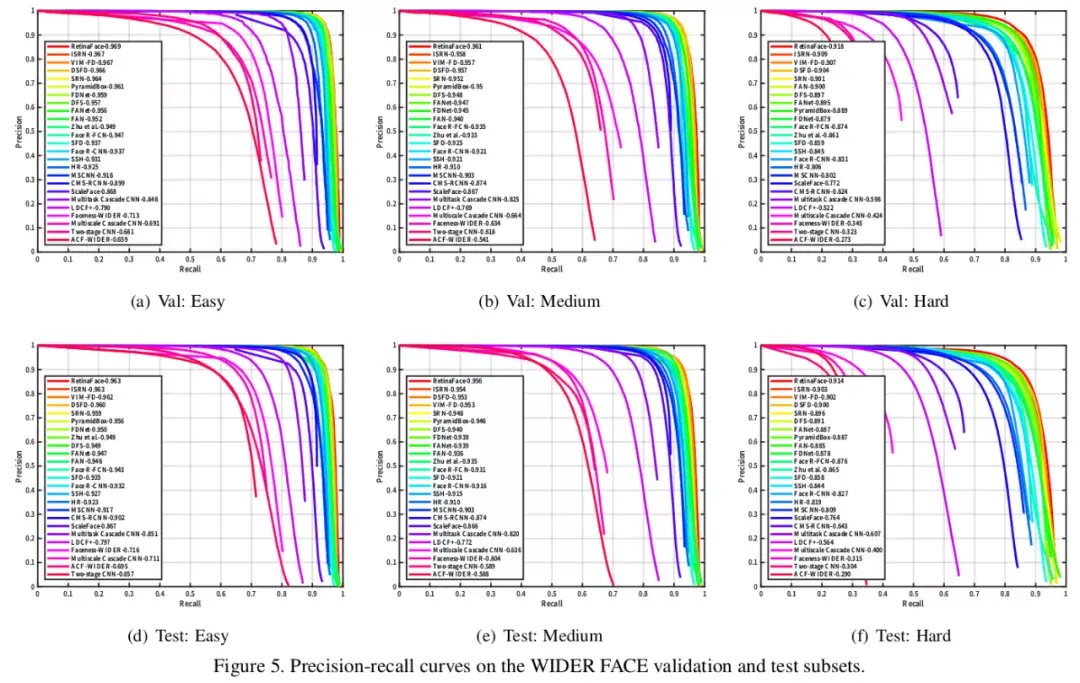
image.png
在图 6 中,我们展示了在一张密集人脸自拍的定性结果。RetinaFace 在报告的 1,151 张面孔中成功找到约 900 张脸(阈值为 0.5)。除了精确的边界框外,在姿势,遮挡和分辨率的变化下利用 RetinaFace 的预测五个人脸关键点也是非常强大。即使在遮挡严重的条件下出现密集面部定位失败的情况下,但在一些清晰而大的面部上的密集回归结果还是不错的,甚至对表情变化大也能检测出来。

image.png
4.5. Five Facial Landmark Accuracy
RetinaFace 与 MTCNN 在五个人脸关键点定位上的定量比较。
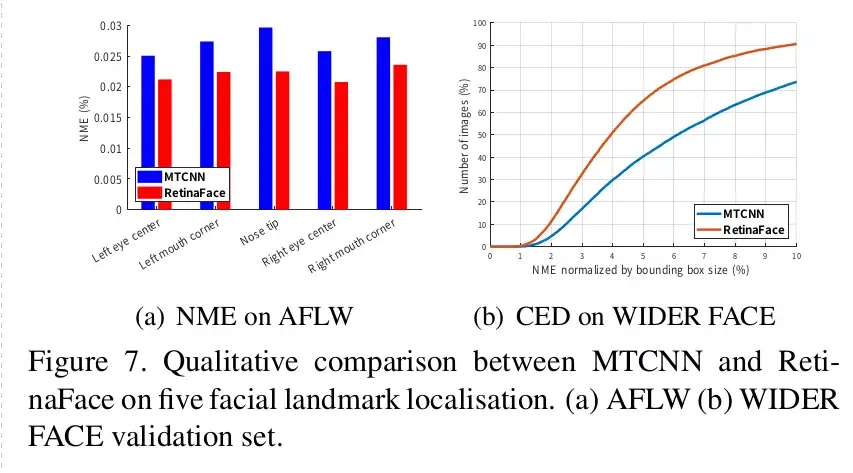
image.png
4.6. Dense Facial Landmark Accuracy我们评估了 AFLW2000-3D 数据集上密集人脸关键点定位的准确性[75],该数据集考虑(1)具有 2D 投影坐标的 68 个关键点和(2)具有 3D 坐标的所有关键点。
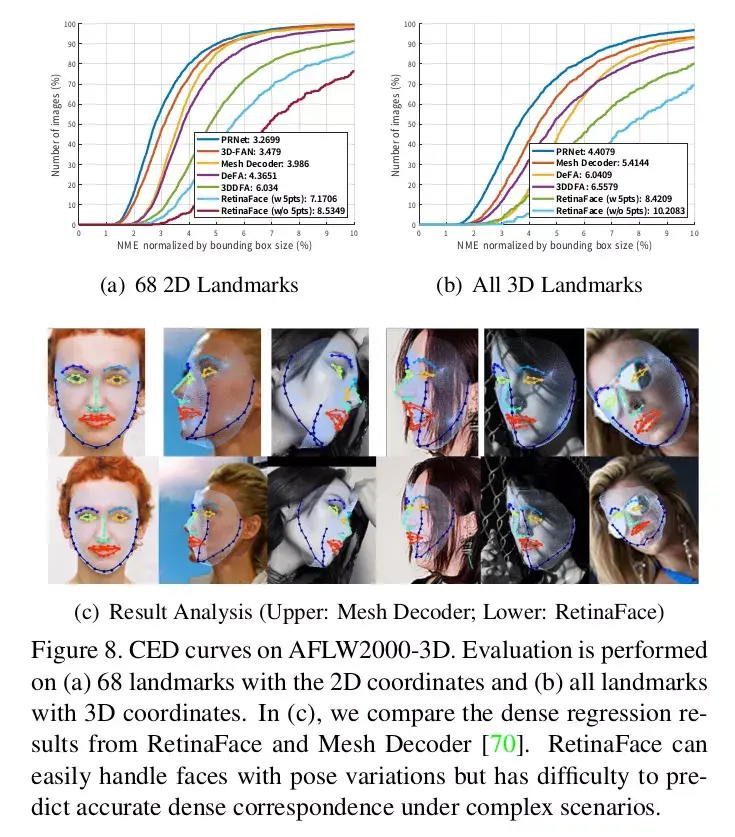
image.png
4.7. Face Recognition Accuracy表 4,我们对比了广泛使用的 MTCNN 和推荐的 RetinaFace 上人脸检测和对齐对深度人脸识别(即 ArcFace)的影响。这表明了(1)人脸检测和对准会严重影响人脸识别性能,并且(2)对于人脸识别应用,RetinaFace 比 MTCNN 具有更强的基准。

image.png
在图 9 中,我们在每个图例的末尾显示了 IJB-C 数据集上的 ROC 曲线以及 FAR = 1e-6 的 TAR。我们采用两种技巧(即翻转测试和人脸检测得分来权衡模板中的样本),以逐步提高人脸识别的准确性。

image.png
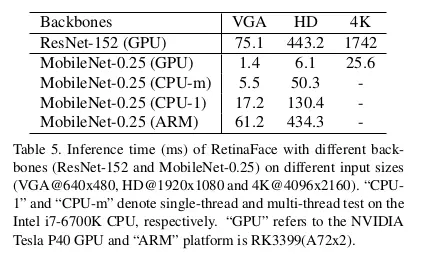
4.8. Inference Efficiency
RetinaFace 进行人脸定位,除了使用 ResNet-152(262MB,AP 91.8% 在 WIDER FACE hard set)的重模型外,还有 MobileNet-0.25(1MB,AP78.25 在 WIDER FACE hard set)的轻模型。
image
我们研究了具有挑战性的问题,即同时进行密集定位和图像中任意比例尺的人脸对齐,并据我们所知,我们是第一个 single-stage 解决方案(RetinaFace)。在当前最具挑战性的人脸检测基准测试中,我们的解决方案优于 state of the art 的方法。此外,将 RetinaFace 与 state-of-the-art 的实践相结合进行人脸识别后,显然可以提高准确性。数据和模型已公开提供,以促进对该主题的进一步研究。
END
参考文献:
https://blog.csdn.net/weixin_40671425/article/details/97804981
论文地址:https://arxiv.org/pdf/1905.00641.pdf
源码地址:(MXNet 实现)https://github.com/deepinsight/insightface/tree/master/RetinaFace
Pytorch 实现:https://github.com/biubug6/Pytorch_Retinaface
caffe 实现:https://github.com/wzj5133329/retinaface_caffe
人脸识别中的评价指标:https://blog.csdn.net/liuweiyuxiang/article/details/81259492
切比雪夫https://zhuanlan.zhihu.com/p/49197590
](https://www.jianshu.com/p/51cc1d8e5e84)

若有收获,就点个赞吧
0 人点赞
