TVM笔记(0) - 知乎
被TVM吸引,因为两个关键词:metaprogramming,autotuning。我本身并不是这个领域出身的,快速的学习了一下,感觉补全了码农生涯的一大空白,收获不小。TVM的介绍是 “端到端的深度学习编译器栈”,但是外行人总会想到一些外行的用途,匆匆看了几个tutorial后,我首先想到的是,有了这个神器,大量纯手工打造的优化是不是可以被替代了。
因为在实践中发现,在一些基于图像的深度学习推理pipeline中,推理部分的耗时可能只占1/2甚至1/3,大量耗时花在了前后处理上,比如颜色空间转换,resize。而这部分处理,就是靠的大量手工优化,因此即使纯粹面向深度学习,用TVM来覆盖非神经网络的部分也是很有意义的。
我理解,TVM的metaprogramming能力从Halide借鉴而来,主要针对图像处理,或者更通用一点,多维数据处理。多维数据的一个典型模式,多个for loop处理各个数据,比如二维矩阵相加 C = A + B:
for (i in range0)for (j in range1)C[i][j] = A[i][j] + B[i][j]
每个for loop代表一个维度,或者说一个轴(axis)。在计算之间没有依赖的情况下,可以有很多有意思的等价转换(transform):
// reorderfor (j in range0)for (i in range1)C[i][j] = A[i][j] + B[i][j]// splitfor (i in range0)for (jo in range1/32)for (ji in 0...32){j = jo * 32 + jiC[i][j] = A[i][j] + B[i][j]}// fusefor (ij in range0*range1){i = ij / range1j = ij % range1C[i][j] = A[i][j] + B[i][j]}
这些转换有什么用呢?配合局部性/并行等一些策略可以提升性能。比如常见的SIMD加速优化,通常需要选定合理的范围进行 向量化(vectorize),这样编译器可以生成相应的目标硬件的SIMD指令,以上述为例子,可以对j轴先split,后进行vectorize,用TVM是这样描述的,先品一下:
jo_axis,ji_axis = s[C].split(j_axis, factor=8)s[C].vectorize(ji_axis)
这里 factor=8,指定了split的步长,即转换为 8个元素相加的计算组。
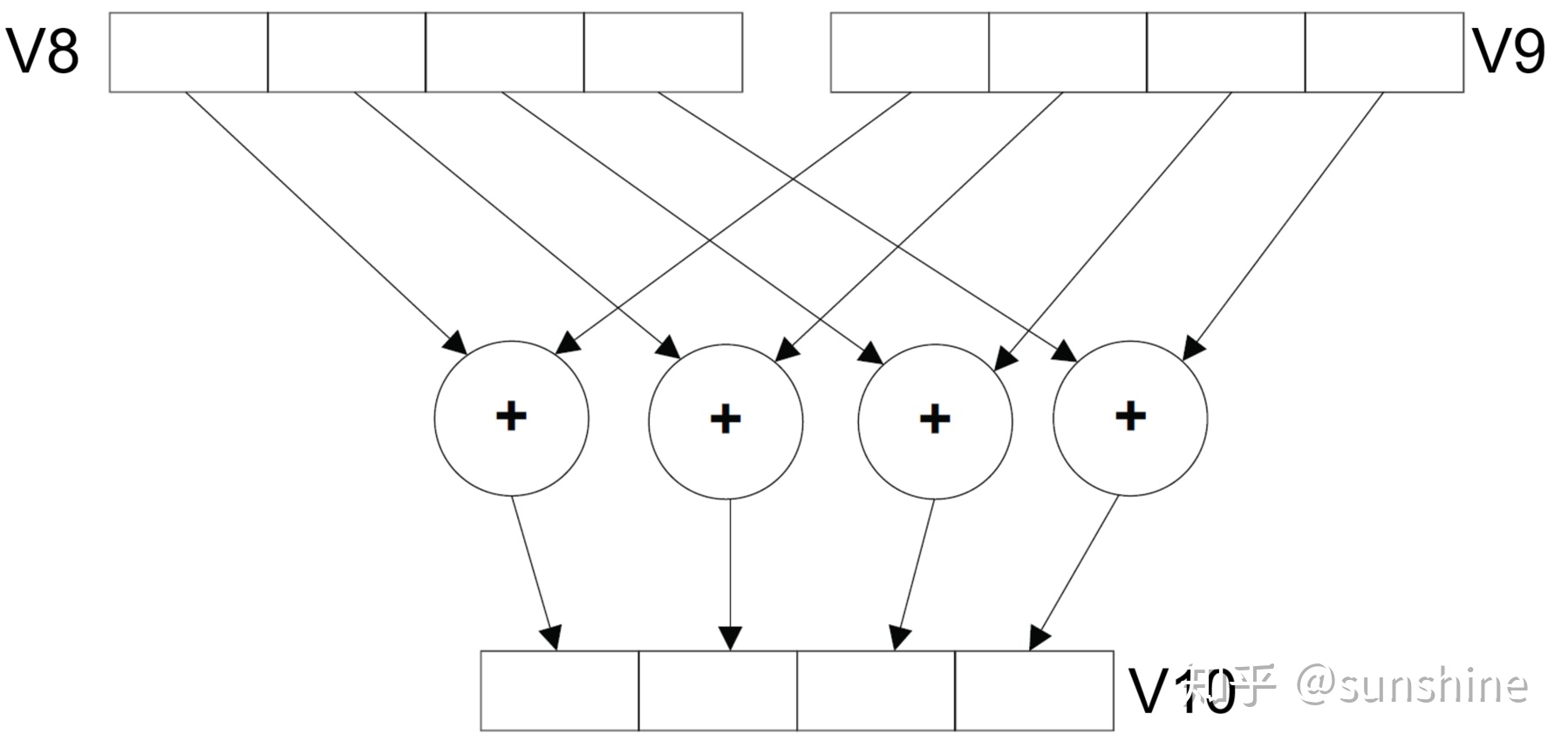 这个factor=8,是有讲究的,为了发挥最大性能,需要根据目标硬件的SIMD长度来选择,比如128bit(ARM NEON 128),256bit(Intel AVX 256),甚至512bit(Intel AVX 512),这就引申出了一个 “调参”的问题。TVM的autotuning就派上用场了。
这个factor=8,是有讲究的,为了发挥最大性能,需要根据目标硬件的SIMD长度来选择,比如128bit(ARM NEON 128),256bit(Intel AVX 256),甚至512bit(Intel AVX 512),这就引申出了一个 “调参”的问题。TVM的autotuning就派上用场了。
autotuning的基本思路是这样的:从一个可以选择的参数范围(config space)选一个参数,运行,记录更新最佳性能数据。用TVM的语言,这样描述:
cfg.define_split("j_axis", y, num_outputs=2)jo_axis, ji_axis = cfg["j_axis"].apply(s, C, j_axis)
其中,define_split用来定义 搜索空间。TVM会根据define_split定义的搜索空间,以某种策略(random,grid,xgboost灯)选一个参数,这时apply就会被调用,应用 参数,运行,直到完成整个搜索空间的探索。
完整的tutorial可以参考:https://docs.tvm.ai/tutorials/autotvm/tune_simple_template.html…
下一步,准备结合一个实际的例子,再把上面整个流程实战一下。

若有收获,就点个赞吧
0 人点赞
