李沐等人开源NNVM:面向AI框架的新型端到端编译器
李沐等人开源NNVM:面向AI框架的新型端到端编译器—-
开发 AI 算法有很多的人工智能框架可以选择,而训练和开发 AI 模型也能用很多种硬件做到。框架和硬件的多样性对于维持 AI 生态系统的健康发展是至关重要的。但这种多样性也给 AI 开发者带来了不小的挑战。这篇文章将简要描述这些挑战,并介绍一种新的编译器解决这些问题。
我们先回顾这些挑战,介绍 UW 和 AWS 研究团队,然后看看这种编译器是如何工作的。
三个挑战
首先,由于前端接口以及后端实现的不同,从一个 AI 框架转换到另一个就很不容易。此外,算法开发者也可能使用不止一种框架以作为开发和输出管道的一部分。在 AWS,我们就有客户要求将他们的 Caffe 模型部署到 MXNET 上,以在 Amazon EC2 上获得性能加速。根据 Joaquin Candela 最近的博客文章(https://research.fb.com/facebook-and-microsoft-introduce-new-open-ecosystem-for-interchangeable-ai-frameworks/),用户可以先用 PyTorch 快速开发模型然后再部署到 Caffe2 上。然而,人们对将模型从一个框架转换到另一个后,对结果的调试过程的差异还是颇不满意。
其次,框架开发者需要维护许多的后端以确保硬件(从智能手机芯片到数据中心 GPU)的性能。以 MXNet 为例,它有一个从头构建的可移植 C++实现,它还搭配了目标相关的后端支持如 Nvidia GPU 的 CuDNN 和 Intel CPUs 的 MKLML。要保证这些不同的后端传送一致的数值结果是很大的挑战。
最后,芯片供应商需要使其开发的每一个新的芯片都能支持多个 AI 框架。每一个框架的工作负载都以独特的方式进行表示和执行,因而即使一个单独的计算比如卷积也可能需要用多种方式定义。支持多个框架需要巨大的工程工作。
UW 和 AWS 研究团队
多样的 AI 框架和硬件能给用户带来莫大的好处,而这对于 AI 开发者来说,传送一致的结果给终端用户很困难。幸运的是,我们并不是第一个遇到这种问题的人。计算机科学就有在不同的硬件上运行多种程序的漫长历史。而解决问题的一种关键的技术就是编译器。由于编译器技术的启发,有一个研究团队包括 Tianqi Chen,,Thierry Moreau,Haichen Shen,,Luis Ceze,,Carlos Guestrin,和来自 Paul G. Allen School of Computer Science & Engineering,University of Washington 的 Arvind Krishnamurthy 以及来自 AWS AI team 的 Ziheng Jiang 共同提出了 TVM 堆栈以简化这个问题。
今天,AWS 联合 UW 公布了新的基于 TVM 堆栈的端对端编译器,它能直接从多个深度学习前端将工作负载编译为优化的机器代码。我们先看看其架构。
架构

我们观察到一个典型的 AI 框架可以大致划分成三个部分:
- 前端向用户展示易用的界面;
- 从前端接收的工作负载通常表示成计算图,由数据变量(a,b,和 c)和算子(*和+)组成;
- 为多种硬件实现和优化算子(从基本的算术运算到神经网络层)。
新的编译器称作 NNVM 编译器,建立在 TVM 堆栈的两个组成的基础上:用于计算图的 NNVM,和用于张量计算的 TVM。
NNVM – 计算图中间表示(intermediate representation,IR)堆栈
NNVM 的目标是将来自不同的框架的工作负载表示成标准的计算图,然后将这些高级图翻译成执行图。将计算图表示成框架不可知(framework-agnostic)的形式的想法,受到了 Keras 的层定义和 numpy 的张量算子的启发。
按照 LLVM 的惯例,NNVM 还搭配了称作 Pass 的例程,以操作这些计算图。这些例程要么往图上添加新的属性以执行它们,要么调整图以提高效率。
TVM – 张量中间表示堆栈
TVM 起源于 Halide,用于在计算图中实现算子,并对其进行优化然后用于目标后端硬件。和 NNVM 不同,它提供了一个硬件无关的、领域特定的语言以在张量指标级上简化算子实现。TVM 还提供了调度原语比如多线程、 平铺和缓存以优化计算,从而充分利用硬件资源。这些调度是硬件相关的,要么用手工编写,要么也可以自动搜索优化模式。
支持的前端框架和后端硬件如下图所示。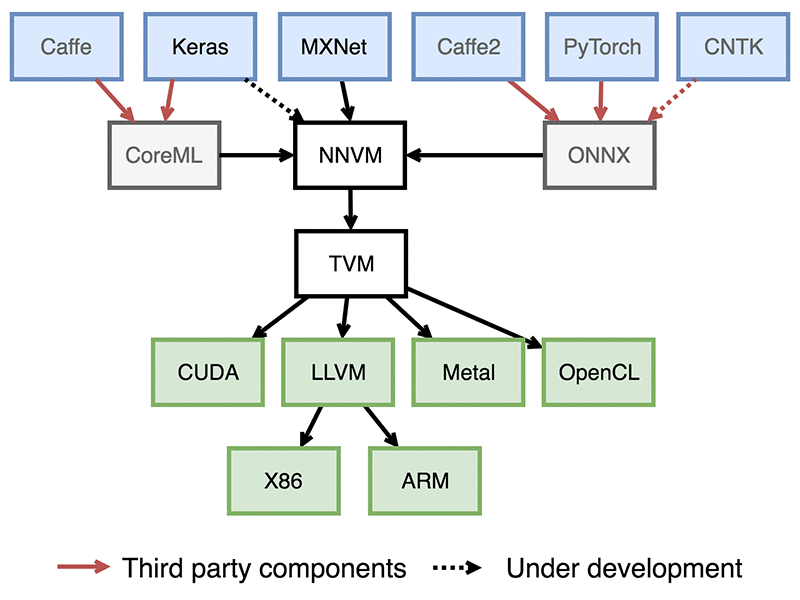
MXNet 通过转换计算图为 NNVM 图,能直接被支持。对 Keras 的支持还在开发中,以和 MXNet 相似的方式。NNVM 编译器也可以包括模型格式,比如 CoreML。因此任何能使用这些格式的框架都能使用这个编译堆栈。
TVM 目前搭配了多种代码生成器以支持多种后端硬件。例如,它能为 CPU(如 X86 和 ARM)生成 LLVM 中间表示。它能为多种 GPUs 输出 CUDA、OpenCL 和 Metal kernels。
添加新的支持是很简单的。对于一个新的前端,只需要将其同时定义了计算图和操作者规范的工作负载转换进 NNVM。如果要支持新的硬件,可以通过 TVM 再次使用算子实现,并只需要明确规定如何有效的调度它们就行了。
性能结果
我们展示了以 MXNet 为前端,以及配置两种典型硬件(树莓派电脑的 ARM CPU 以及 AWS 的 Nvidia GPU)的 NNVM 编译器的性能表现。尽管这两种芯片有根本的区别,但也只在调度部分的代码才出现了差异。
Nvidia GPUs
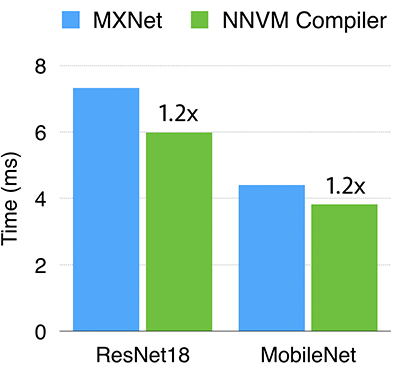
GPU 的调度大部分由 Leyuan Wang (AWS) 和 Yuwei Hu (TuSimple) 在他们实习期间编写。我们比较了 NNVM 编译器,和 MXNet 搭配 Nvidia K80 的 cuDNN 为后端的组合。在 cuDNN 不能得到有效支持的算子比如深度(depthwise)卷积由手动优化 CUDA 的核实现。如上图所示,在 ResNet18 和 MobileNet 的表现中,NNVM 编译器都比 cuDNN 为后端要稍微好一些(快 1.2 倍)。
树莓派电脑 3B
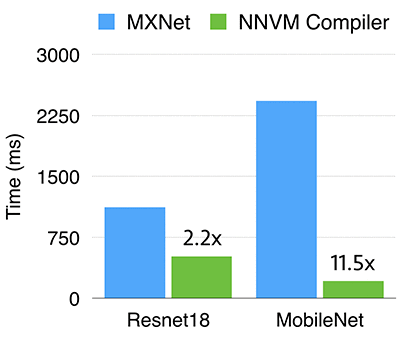
最适宜的调度由自动调整运动参数的模组(auto tuner)选出。特别是,我们通过基准问题测试在树莓派电脑上的性能,为每一个给定形状(shape)的算子找到了最好的调度。
我们对比了 NNVM 编译器和 MXNet。MXNet 使用 OpenBLAS 生成并兼容 NNPACK 库,我们手工在 NNPACK 中启用了 winograd 卷积算法以获得最佳性能。
如上图所示,NNVM 编译器在 Resnet18 中的表现要快 2.2 倍,并且在 MobileNet 上要快 11.5 倍。这主要都是由于深度卷积在 MXNet 中没有得到优化(在 dnn 库中缺少这样的算子),而 NNVM 编译器受益于能直接为其生成有效的代码的能力。
结论
本文中,我们介绍了 NNVM 编译器,能将高级的计算图编译进优化的机器代码中。该编译器主要基于 TVM 堆栈的两个主要部件:NNVM 提供计算图、计算路径优化的算子的明细,通过使用 TVM 可为特定硬件部署、优化算子。我们证明,在极小付出下,该编译器就能在两种完全不同的硬件上(ARM CPU 和英伟达 GPU)得到匹配甚至超越顶级表现。
我们希望 NNVM 编译器能极大的简化新型 AI 前端框架和后端硬件的设计,并能跨越前端和后端为用户提供一致的结果。

若有收获,就点个赞吧
0 人点赞
