手把手带你遨游TVM
| 创建时间: | 2019-08-08 23:44 |
|---|---|
| 更新时间: | 2020-06-02 23:22 |
| 标签: | TVM |
| 来源: | https://zhuanlan.zhihu.com/p/50529704 |
人工智能无疑是目前风口浪尖的话题,大部分提到人工智能都关注在了算法,然而若要让人工智能落脚在实际应用中,工程化是至关重要的。
让我们再细化一点这个问题,我们目前要让一个算法落地下来,或者说我们要产生一个模型,然后部署到目标设备上进行运行。我们需要分两步:Training + Inference,目前对于Training来说,比较流行的是TensorFlow,PyTorch等,市场主流框架基本上已经确定下来了。而对于Inference来说,以我之所见,其实是“群雄逐鹿”,因为模型Training一次,但是会跑到的设备可能会是多种多样的,如Intel CPU / Intel GPU / ARM CPU / ARM GPU / NV GPU / FPGA / AI芯片等,而要在这多种多样的设备中都保持一个高效的Inference性能,其实是一件很有挑战的事情,也是作为程序员很喜欢的一件事情,知难而上,挑战难题达到颅内高潮的那种感觉也不是任何一件事情能达到的。
让我们图例化这一点: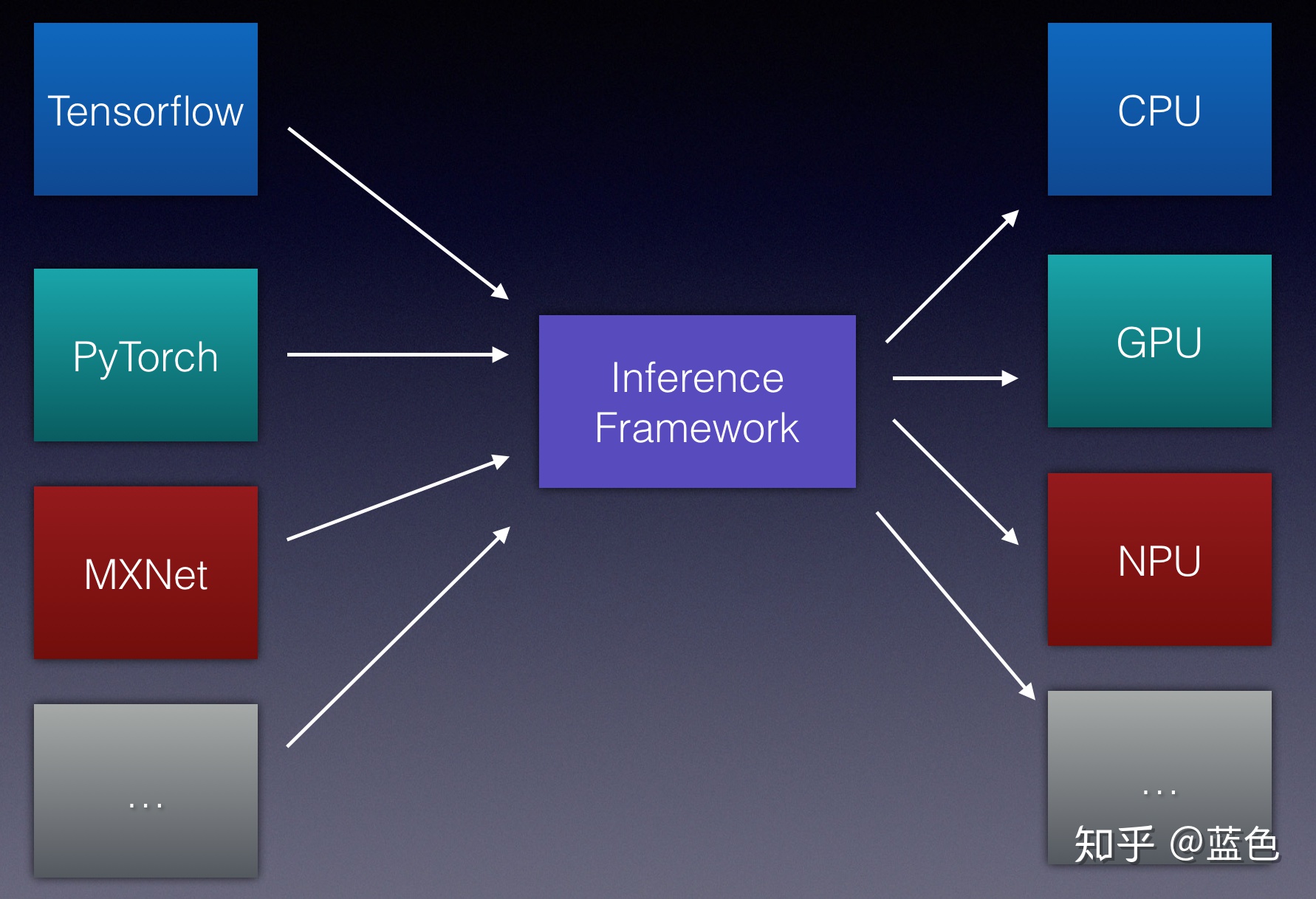
其实要达到这一个目标并不容易,各种硬件设备的特性千差万别,要如何保持一个统一的高效执行,是一个非常难做到的事情。而各大硬件厂商针对这样的情况都推出了自己的Inference 框架(相比TensorFlow等这样的框架孱弱的Inference性能,各大设备厂商的Inference框架性能都比较不错),比如Intel的OpenVINO,ARM的ARM NN,NV的TensorRT等,但是这里面有一个问题,各大设备厂商的框架并不具备通用性,比如对训练框架模型产生的算子支持不全(尤其是像TensorFlow这种算子很多的),通常在一个设备厂商的Inference框架能跑,但是不一定在另外一个设备厂商的Inference框架上能跑。同时,对于业务开发来说也是非常痛苦的事情,我在这个硬件上要用这个,我在另外一个硬件上要用另外一个,而且两者还没有统一的使用体验,算子支持也不一样,性能还不一定是最好的…其实对于业务方来说,也是想要一个统一的Inference框架,然后我业务场景的各种硬件设备都能高效的跑,使用体验都是一致的,我只要换一个device_target参数就好了。
以我之所见,其实我们并不是第一次遇到这样的问题,我们曾经出现了很多种编程语言,有很多种硬件,历史上最开始也是一种语言对应一种硬件,从而造成编译器的维护困难与爆炸。
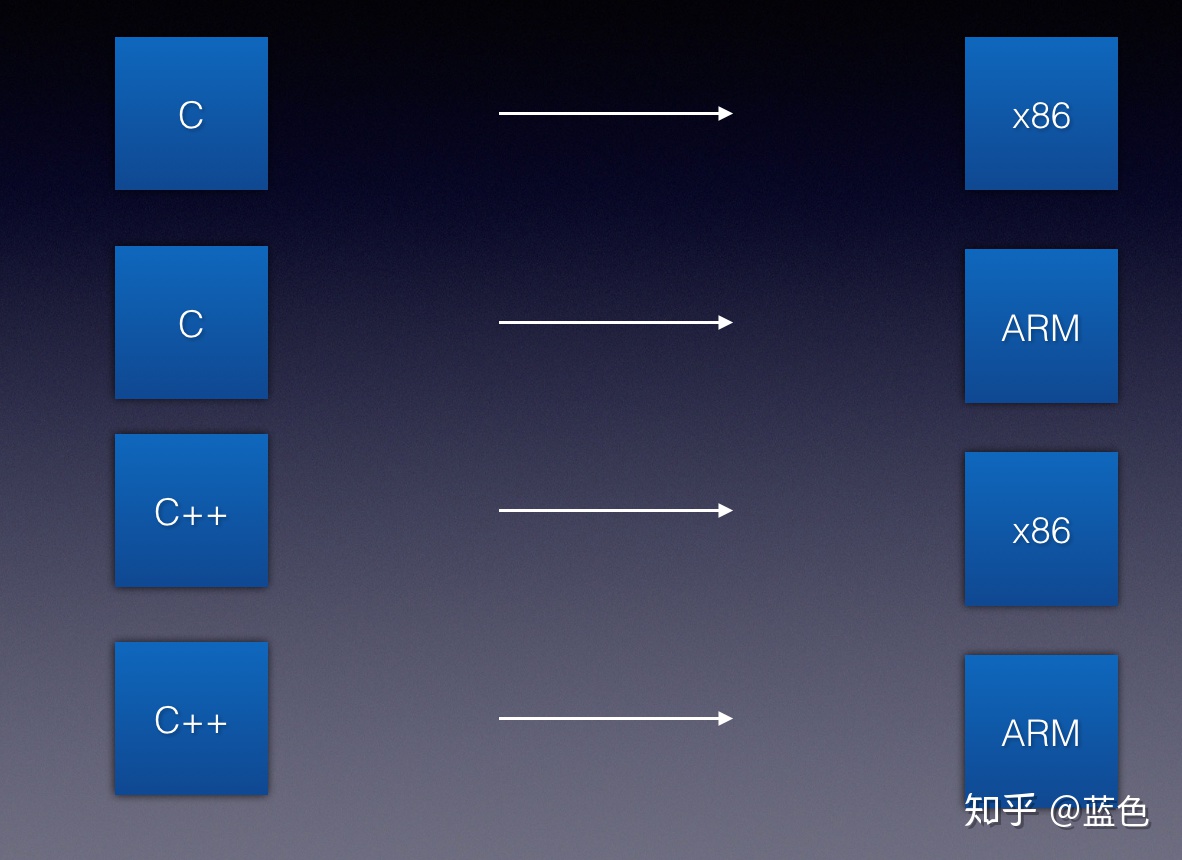
而编译器后面解决了这个问题,其具体解决办法是这样的:抽象出编译器前端,编译器中端,编译器后端等概念,引入IR (Intermediate Representation)
- • 编译器前端:接收C / C++ / Fortran等不同语言,进行代码生成,吐出IR
- • 编译器中端:接收IR,进行不同编译器后端可以共享的优化,如常量替换,死代码消除,循环优化等,吐出优化后的IR
- • 编译器后端:接收优化后的IR,进行不同硬件的平台相关优化与硬件指令生成,吐出目标文件
类似这样的架构:
其实对于Inference框架也是类似的道理,我们也想要得到类似的架构:
我们把各种模型抽象看成各种编程语言,于是我们引入一个新的编译器,负责把这些编程语言识别,吐出IR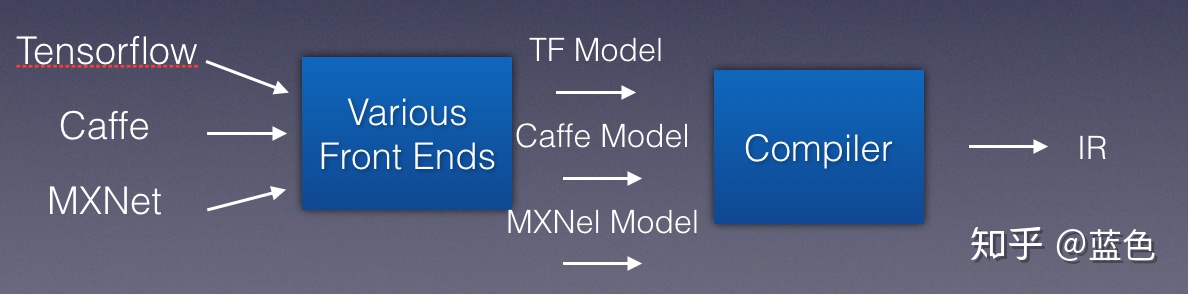
接下来我们就可以对这种中间的IR进行优化,而深度学习中是计算图,所以我们可以称为Graph IR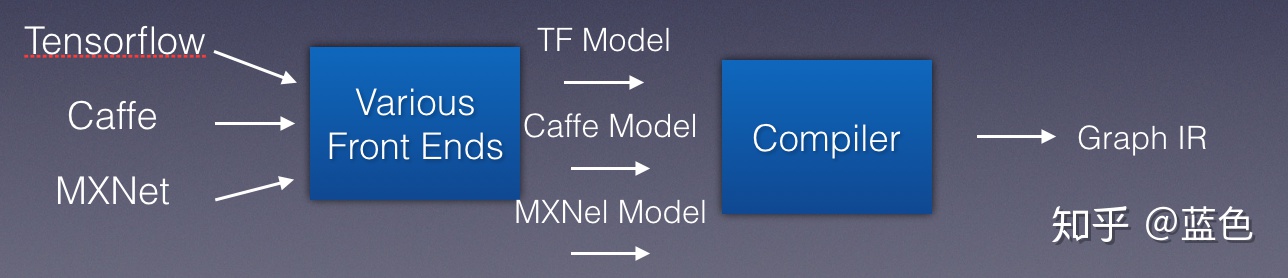
于是,我们得到这样的架构: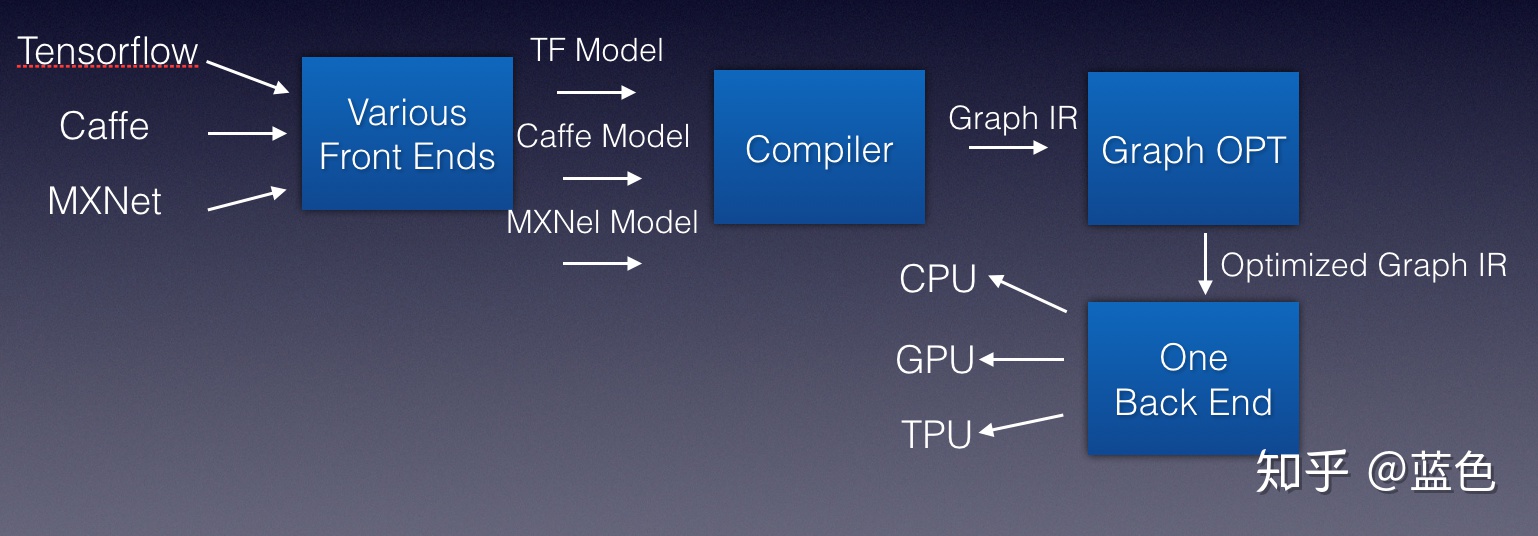
这就是我们想要解决的问题了。所以,就来到我们今天的重点了,我们能不能做一个基于编译优化思想的推理框架呢?答案就是:TVM (https://tvm.ai/).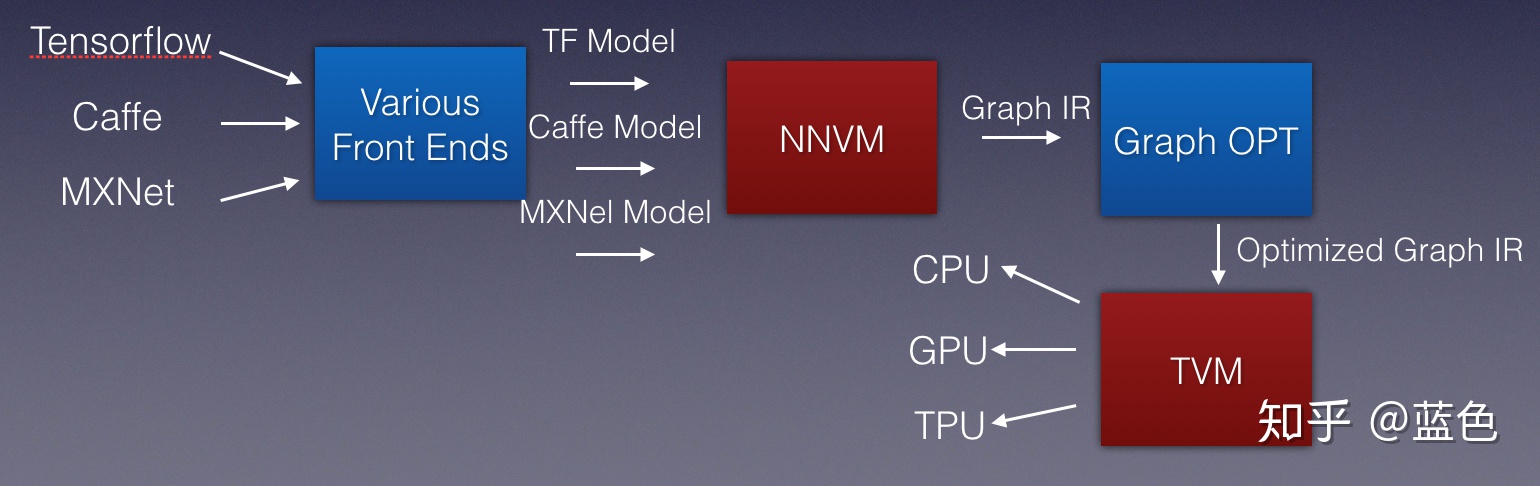
让我们给出一副更详尽,更漂亮的一张图: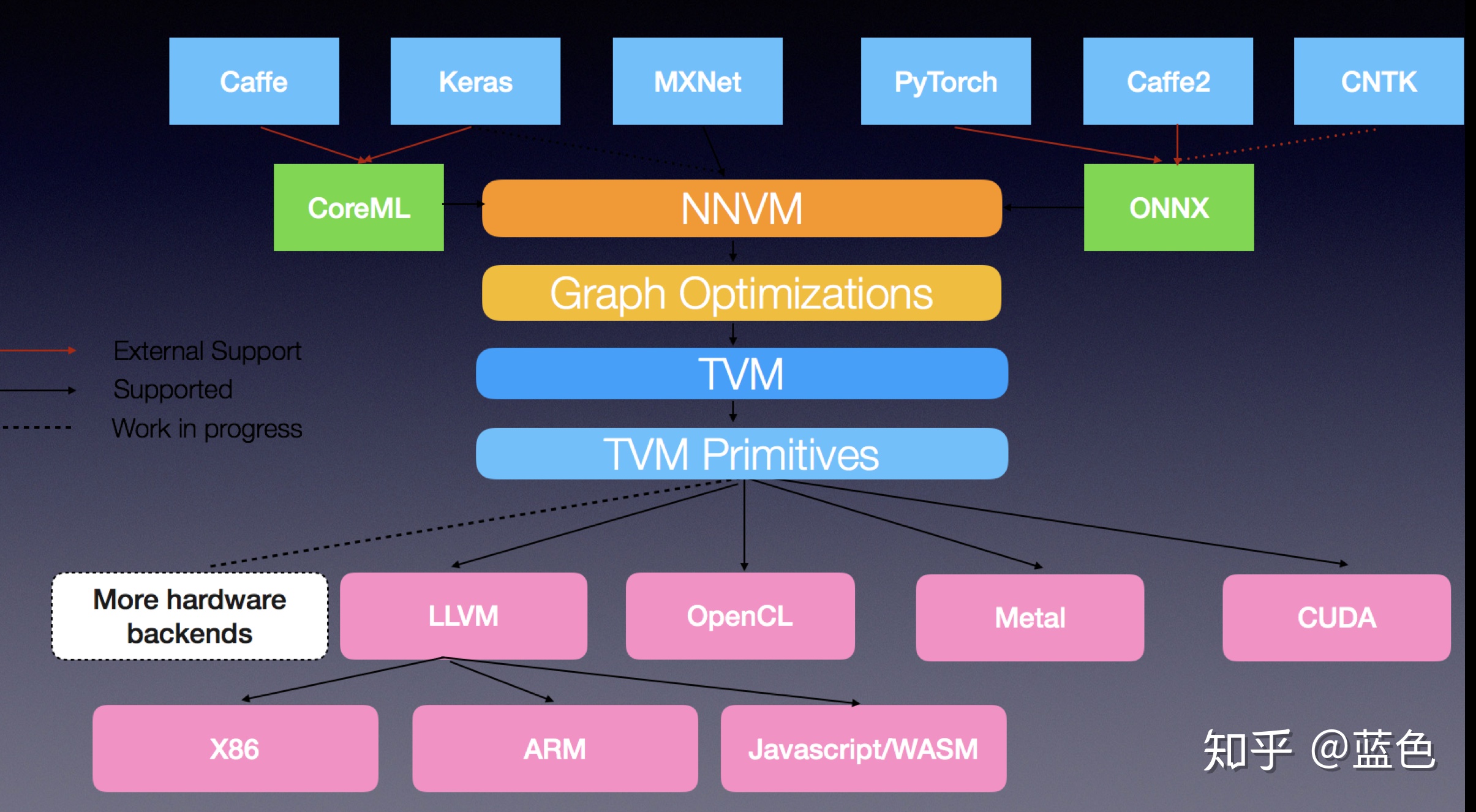
这就是TVM官方给的架构图。在我们图中的CPU目标是通过什么来做到的呢?LLVM。当然,也包括了AMD GPU,也是LLVM来做到的,但是这张图里面没有列举出来。在这张图里面,对于NV GPU的支持是产生CUDA,但是从我的角度来看,其实也是可以产生NVVM的,然后走LLVM的路线。
TVM基本上就是基于编译优化思想的深度学习推理框架的完美体现,自从加入了AutoTVM(https://arxiv.org/pdf/1805.08166.pdf…)机制以后,可以用一个词来形容,就是如虎添翼,击败NCNN等框架是没有任何问题的,可参考这篇文章的对比:Automatic Kernel Optimization for Deep Learning on All Hardware Platforms,并且这里的性能还没有应用上我这个PR:
[ARM][Performance] Improve ARM CPU depthwise convolution performance by FrozenGene · Pull Request #2345 · dmlc/tvm
我的这个PR可以将深度卷积的性能提高近2倍。
而AutoTVM的存在最厉害的是具有非常强的适应性,很多Inference框架在一些标准模型上表现的很好,但是一遇到业务模型就性能急剧下降,比如来个257 * 513这种输入,但是AutoTVM不会存在这个问题。若有后续,我会来讲AutoTVM到底完成了什么样的事情。
然而TVM的代码并不容易阅读,比如今天在TVM论坛看到的:
即使学习了两个月,他都觉得一顿混沌。所以,我想以我的角度来带大家手把手遨游一下。

若有收获,就点个赞吧
0 人点赞
