一步一步解读神经网络编译器TVM(二)——利用TVM完成C++端的部署
前言
在上一篇文章中[一步一步解读神经网络编译器TVM(一)——一个简单的例子](https://oldpan.me/archives/the-first-step-towards-tvm-1),我们简单介绍了什么是TVM以及如何利用Relay IR去编译网络权重然后并运行起来。上述文章中的例子很简单,但是实际中我们更需要的是利用TVM去部署我们的应用么,最简单直接的就是在嵌入式系统中运行起我们的神经网络模型。例如树莓派。这才是最重要的是不是?所以嘛,在深入TVM之前还是要走一遍基本的实践流程的,也唯有实践流程才能让我们更好地理解TVM到底可以做什么。
所以嘛,在这篇文章中,主要介绍如果将自己的神经网络使用TVM编译,并且导出动态链接库文件,最后部署在树莓派端(PC端),并且运行起来。# 环境搭建
环境搭建?有什么好讲的?废话咯,你需要先把TVM的环境搭建出来才可以用啊,在上一篇文章中已经说过了,另外官方的安装教程最为详细,这里还是多建议看看官方的文档,很详细很具体重点把握的也很好。但是还是要强调两点:
- 需要安装LLVM,因为这篇文章所讲的主要运行环境是CPU(树莓派的GPU暂时不用,内存有点小),所以LLVM是必须的
- 安装交叉编译器:
Cross Compiler
交叉编译器是什么,就是我可以在PC平台上编译生成可以直接在树莓派上运行的可执行文件。而在TVM中,我们需要利用交叉编译器在PC端编译模型并且优化,然后生成适用于树莓派(arm构架)使用的动态链接库。有这个动态链接库,我们就可以直接调用树莓派端的TVM运行时环境去调用这个动态链接库,从而执行神经网络的前向操作了。那么怎么安装呢?这里我们需要安装叫做 /usr/bin/arm-linux-gnueabihf-g++ 的交叉编译器,在Ubuntu系统中,我们直接 sudo apt-get install g++-arm-linux-gnueabihf 即可,注意名称不能错,我们需要的是hf(Hard-float)版本。安装完后,执行 /usr/bin/arm-linux-gnueabihf-g++ -v 命令就可以看到输出信息:prototype@prototype-X299-UD4-Pro:~/$/usr/bin/arm-linux-gnueabihf-g++-vUsingbuilt-inspecs.COLLECT_GCC=/usr/bin/arm-linux-gnueabihf-g++COLLECT_LTO_WRAPPER=/usr/lib/gcc-cross/arm-linux-gnueabihf/5/lto-wrapperTarget: arm-linux-gnueabihfConfigured with:../src/configure-v—with-pkgversion=’Ubuntu/Linaro 5.4.0-6ubuntu1~16.04.9’—with-bugurl=file:///usr/share/doc/gcc-5/README.Bugs—enable-languages=c,ada,c++,java,go,d,fortran,objc,obj-c++—prefix=/usr—program-suffix=-5—enable-shared—enable-linker-build-id—libexecdir=/usr/lib—without-included-gettext—enable-threads=posix—libdir=/usr/lib—enable-nls—with-sysroot=/—enable-clocale=gnu—enable-libstdcxx-debug—enable-libstdcxx-time=yes—with-default-libstdcxx-abi=new—enable-gnu-unique-object—disable-libitm—disable-libquadmath—enable-plugin—with-system-zlib—disable-browser-plugin—enable-java-awt=gtk—enable-gtk-cairo—with-java-home=/usr/lib/jvm/java-1.5.0-gcj-5-armhf-cross/jre—enable-java-home—with-jvm-root-dir=/usr/lib/jvm/java-1.5.0-gcj-5-armhf-cross—with-jvm-jar-dir=/usr/lib/jvm-exports/java-1.5.0-gcj-5-armhf-cross—with-arch-directory=arm—with-ecj-jar=/usr/share/java/eclipse-ecj.jar—disable-libgcj—enable-objc-gc—enable-multiarch—enable-multilib—disable-sjlj-exceptions—with-arch=armv7-a—with-fpu=vfpv3-d16—with-float=hard—with-mode=thumb—disable-werror—enable-multilib—enable-checking=release—build=x86_64-linux-gnu—host=x86_64-linux-gnu—target=arm-linux-gnueabihf—program-prefix=arm-linux-gnueabihf—-includedir=/usr/arm-linux-gnueabihf/includeThread model: posixgcc version 5.4.0 20160609(Ubuntu/Linaro 5.4.0-6ubuntu1~16.04.9)## 树莓派环境搭建 因为我们是在PC端利用TVM编译神经网络的,所以在树莓派端我们只需要编译TVM的运行时环境即可(TVM可以分为两个部分,一部分为编译时,另一个为运行时,两者可以拆开)。这里附上官方的命令,注意树莓派端也需要安装llvm,树莓派端的llvm可以在llvm官方找到已经编译好的压缩包,解压后添加环境变量即可:git clone—recursive https://github.com/dmlc/tvmcd tvmmkdir buildcpcmake/config.cmake build# 这里修改config.cmake使其支持llvmcd buildcmake..make runtime在树莓派上编译TVM的运行时并不需要花很久的时间。# 完成部署 环境搭建好之后,就让我们开始吧~ 首先我们依然需要一个自己的测试模型,在这里我使用之前训练好的,识别剪刀石头布手势的模型权重,然后利用Pytorch导出ONNX模型出来。具体的导出步骤可以看我之前的这两篇文章,下述两篇文章中使用的模型与本篇文章使用的是同一个模型。
首先我们依然需要一个自己的测试模型,在这里我使用之前训练好的,识别剪刀石头布手势的模型权重,然后利用Pytorch导出ONNX模型出来。具体的导出步骤可以看我之前的这两篇文章,下述两篇文章中使用的模型与本篇文章使用的是同一个模型。 - 利用Pytorch的C++前端(libtorch)读取预训练权重并进行预测
- Pytorch的C++端(libtorch)在Windows中的使用
 (上图是之前的识别剪刀石头布的一个权重模型)OK,那我们拥有了一个模型叫做 mobilenetv2-128_S.onnx ,这个模型也就是通过Pytorch导出的ONNX模型,利用Netron瞧一眼:
(上图是之前的识别剪刀石头布的一个权重模型)OK,那我们拥有了一个模型叫做 mobilenetv2-128_S.onnx ,这个模型也就是通过Pytorch导出的ONNX模型,利用Netron瞧一眼: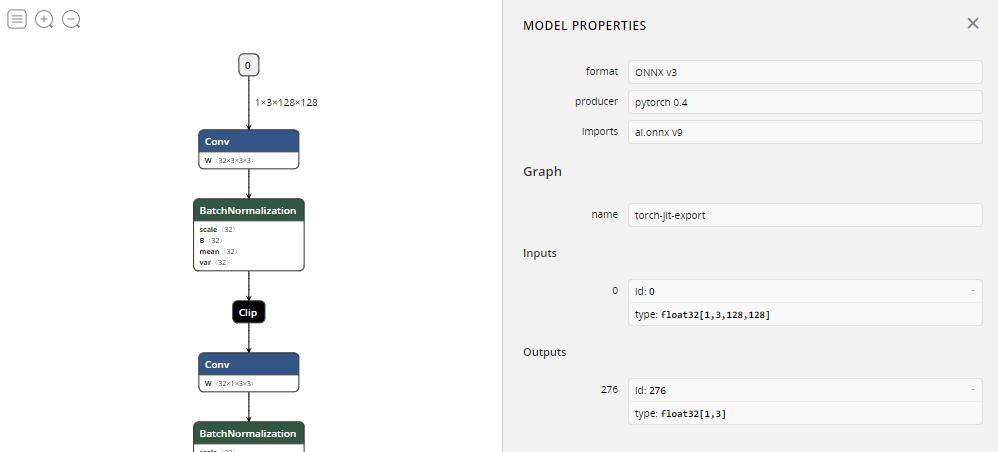 整个模型的输入和输出上图写的都很清楚了。## 测试模型
拿到模型后,我们首先测试模型是否可以正确工作,同上一篇介绍TVM的文章类似,我们利用TVM的PYTHON前端去读取我们的.onnx模型,然后将其编译并运行,最后利用测试图像测试其是否可以正确工作,其中核心代码如下:onnx_model=onnx.load(‘../test/new-mobilenetv2-128_S.onnx’)
整个模型的输入和输出上图写的都很清楚了。## 测试模型
拿到模型后,我们首先测试模型是否可以正确工作,同上一篇介绍TVM的文章类似,我们利用TVM的PYTHON前端去读取我们的.onnx模型,然后将其编译并运行,最后利用测试图像测试其是否可以正确工作,其中核心代码如下:onnx_model=onnx.load(‘../test/new-mobilenetv2-128_S.onnx’)
img=Image.open(‘../datasets/hand-image/paper.jpg’).resize((128,128))
img=np.array(img).transpose((2,0,1)).astype(‘float32’)img=img/255.0# 注意在Pytorch中的tensor范围是0-1x=img[np.newaxis,:]
target=’llvm’
input_name=’0’# 这里需要注意,因为我生成的.onnx模型的输入代号是0,所以这里改为0shape_dict={input_name:x.shape}sym,params=relay.frontend.from_onnx(onnx_model,shape_dict)
withrelay.build_config(opt_level=3):intrp=relay.build_module.create_executor(‘graph’,sym,tvm.cpu(0),target)
dtype=’float32’func=intrp.evaluate(sym)
# 输出推断的结果tvm_output=intrp.evaluate(sym)(tvm.nd.array(x.astype(dtype)),**params).asnumpy()max_index=tvm_output.argmax()print(max_index)我这个模型输出的结果为三个手势的输出值大小(顺序分别为布、剪刀、石头),上述的代码打印出来的值为0,意味着可以正确识别 paper.jpg 输入的图像。说明这个转化过程是没有问题的。## 导出动态链接库 上面这个步骤只是将.onnx模型利用TVM读取并且预测出来,如果我们需要部署的话我们就需要导出整个模型的动态链接库,至于为什么是动态链接库,其实TVM是有多种的导出模式的(也可以导出静态库),但是这里不细说了: 总之我们的目标就是导出so动态链接库,这个链接库中包括了我们神经网络所需要的一切推断功能。那么怎么导出呢?其实官方已经有很详细的导出说明。我这里不进行赘述了,仅仅展示核心的代码加以注释即可。请看以下的代码:#开始同样是读取.onnx模型
总之我们的目标就是导出so动态链接库,这个链接库中包括了我们神经网络所需要的一切推断功能。那么怎么导出呢?其实官方已经有很详细的导出说明。我这里不进行赘述了,仅仅展示核心的代码加以注释即可。请看以下的代码:#开始同样是读取.onnx模型
onnx_model=onnx.load(‘../../test/new-mobilenetv2-128_S.onnx’)img=Image.open(‘../../datasets/hand-image/paper.jpg’).resize((128,128))
# 以下的图片读取仅仅是为了测试img=np.array(img).transpose((2,0,1)).astype(‘float32’)img=img/255.0# remember pytorch tensor is 0-1x=img[np.newaxis,:]
# 这里首先在PC的CPU上进行测试 所以使用LLVM进行导出target=tvm.target.create(‘llvm’)
input_name=’0’# change ‘1’ to ‘0’shape_dict={input_name:x.shape}sym,params=relay.frontend.from_onnx(onnx_model,shape_dict)
# 这里利用TVM构建出优化后模型的信息withrelay.build_config(opt_level=2):graph,lib,params=relay.build_module.build(sym,target,params=params)
dtype=’float32’
fromtvm.contribimportgraph_runtime
# 下面的函数导出我们需要的动态链接库 地址可以自己定义print(“Output model files”)libpath=”../tvm_output_lib/mobilenet.so”lib.export_library(libpath)
# 下面的函数导出我们神经网络的结构,使用json文件保存graph_json_path=”../tvm_output_lib/mobilenet.json”withopen(graph_json_path,’w’)asfo:fo.write(graph)
# 下面的函数中我们导出神经网络模型的权重参数param_path=”../tvm_output_lib/mobilenet.params”withopen(param_path,’wb’)asfo:fo.write(relay.save_param_dict(params))# ——————-至此导出模型阶段已经结束————
# 接下来我们加载导出的模型去测试导出的模型是否可以正常工作loaded_json=open(graph_json_path).read()loaded_lib=tvm.module.load(libpath)loaded_params=bytearray(open(param_path,”rb”).read())
# 这里执行的平台为CPUctx=tvm.cpu()
module=graph_runtime.create(loaded_json,loaded_lib,ctx)module.load_params(loaded_params)module.set_input(“0”,x)module.run()out_deploy=module.get_output(0).asnumpy()
print(out_deploy)上述的代码输出 [[13.680096 -7.218611 -6.7872353]] ,因为输入的图像是 paper.jpg ,所以输出的三个数字第一个数字最大,没有毛病。执行完代码之后我们就可以得到需要的三个文件 - mobilenet.so
- mobilenet.json
- mobilenet.params
得到三个文件之后,接下来我们利用TVM的C++端读取并运行起来。## 在PC端利用TVM部署C++模型
如何利用TVM的C++端去部署,官方也有比较详细的文档,这里我们利用TVM和OpenCV读取一张图片,并且使用之前导出的动态链接库去运行神经网络对这张图片进行推断。我们需要的头文件为:#include
#include #include #include #include #include #include 其实这里我们只需要TVM的运行时,另外dlpack是存放张量的一个结构。其中OpenCV用于读取图片,而 fstream 则用于读取json和参数信息:tvm::runtime::Module mod_dylib=tvm::runtime::Module::LoadFromFile(“../files/mobilenet.so”);
std::ifstreamjson_in(“../files/mobilenet.json”,std::ios::in);std::stringjson_data((std::istreambuf_iterator(json_in)),std::istreambuf_iterator ());json_in.close();
// parameters in binarystd::ifstreamparams_in(“../files/mobilenet.params”,std::ios::binary);std::stringparams_data((std::istreambuf_iterator(params_in)),std::istreambuf_iterator ());params_in.close();
TVMByteArray params_arr;params_arr.data=params_data.c_str();params_arr.size=params_data.length();在读取完信息之后,我们要利用之前读取的信息,构建TVM中的运行图(Graph_runtime):intdtype_code=kDLFloat;intdtype_bits=32;intdtype_lanes=1;intdevice_type=kDLCPU;intdevice_id=0;
tvm::runtime::Module mod=(tvm::runtime::Registry::Get(“tvm.graph_runtime.create”))(json_data,mod_dylib,device_type,device_id);然后利用TVM中函数建立一个输入的张量类型并且为它分配空间:DLTensorx;intin_ndim=4;int64_tin_shape[4]={1,3,128,128};TVMArrayAlloc(in_shape,in_ndim,dtype_code,dtype_bits,dtype_lanes,device_type,device_id,&x);其中 DLTensor 是个灵活的结构,可以包容各种类型的张量,而在创建了这个张量后,我们需要将OpenCV中读取的图像信息传入到这个张量结构中:// 这里依然读取了papar.png这张图image=cv::imread(“/home/prototype/CLionProjects/tvm-cpp/data/paper.png”);
cv::cvtColor(image,frame,cv::COLOR_BGR2RGB);cv::resize(frame,input,cv::Size(128,128));
floatdata[1281283];// 在这个函数中 将OpenCV中的图像数据转化为CHW的形式Mat_to_CHW(data,input);需要注意的是,因为OpenCV中的图像数据的保存顺序是(128,128,3),所以这里我们需要将其调整过来,其中 Mat_to_CHW 函数的具体内容是:voidMat_to_CHW(floatdata,cv::Mat&frame){assert(data&&!frame.empty());unsignedintvolChl=128128;
for(intc=0;c<3;++c){for(unsignedj=0;j
}当然别忘了除以255.0因为在Pytorch中所有的权重信息的范围都是0-1。在将OpenCV中的图像数据转化后,我们将转化后的图像数据拷贝到之前的张量类型中:// x为之前的张量类型 data为之前开辟的浮点型空间memcpy(x->data,&data,3128128sizeof(float));然后我们设置运行图的输入(x)和输出(y):// get the function from the module(set input data)tvm::runtime::PackedFunc set_input=mod.GetFunction(“set_input”);set_input(“0”,x);
// get the function from the module(load patameters)tvm::runtime::PackedFunc load_params=mod.GetFunction(“load_params”);load_params(params_arr);
DLTensory;intout_ndim=2;int64_tout_shape[2]={1,3,};TVMArrayAlloc(out_shape,out_ndim,dtype_code,dtype_bits,dtype_lanes,device_type,device_id,&y);
// get the function from the module(run it)tvm::runtime::PackedFunc run=mod.GetFunction(“run”);
// get the function from the module(get output data)tvm::runtime::PackedFunc get_output=mod.GetFunction(“get_output”);此刻我们就可以运行了:run();get_output(0,y);
// 将输出的信息打印出来autoresult=static_cast<float>(y->data);for(inti=0;i<3;i++)cout<

若有收获,就点个赞吧
0 人点赞
