- 【TVM翻译】An Automated End-to-End Optimizing Compiler
- Abstract
- 越来越多的应用需要将机器学习应用到各种各样的硬件设备上。当前框架依赖于特定供应商的运算符库(vendor-specific library),并针对小范围的服务器级GPU进行优化。将工作负载(workloads) 部署到新平台,例如手机,嵌入式设备和加速器(如FPGA,ASIC),需要大量的手动工作。我们发布了TVM,这是一种可提供计算图级优化(graph-level optimization) 和运算符级优化(operator-level optimization) 的编译器,可以为不同硬件后端的深度学习工作负载提供性能可移植性。TVM解决了深度学习面临的优化问题,例如高级运算符融合,映射到任意硬件原语,以及内存延迟隐藏。它还通过采用新颖的,基于学习的成本建模方法来快速搜索代码优化,从而自动优化低级程序来符合硬件特性。实验结果表明,TVM可以提供跨硬件后端的性能,这些后端与用于低功耗CPU,移动GPU和服务器级GPU的最先进的手动调整库相比具有竞争力。我们还展示了TVM针对新加速器后端的能力,例如基于FPGA的通用深度学习加速器。该系统是在几家大公司内部开源和生产使用的。
- 机器指令构成的完成某种特定功能的一段程序,具有不可分割性.即原语的执行必须是连续的,在执行过程中不允许被中断。内存延迟隐藏:延迟是指从提出请求到收到响应之间的延期;内存延迟是指等待对系统内存中存储数据的访问完成时引起的延期。内存隐藏延迟是靠内存读取的并发操作来完成的,需要注意的是,指令隐藏的关键目的是使用全部的计算资源,而内存读取的延迟隐藏是为了使用全部的内存带宽,内存延迟的时候,计算资源正在被别的线程束使用,所以我们不考虑内存读取延迟的时候计算资源在做了什么,这两种延迟我们看做两个不同的部门但是遵循相同的道理。我们的根本目的是把计算资源,内存读取的带宽资源全部使用满,这样就能达到理论的最大效率。">硬件原语:操作系统用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程。primitive or atomic action 是由若干个机器指令构成的完成某种特定功能的一段程序,具有不可分割性.即原语的执行必须是连续的,在执行过程中不允许被中断。内存延迟隐藏:延迟是指从提出请求到收到响应之间的延期;内存延迟是指等待对系统内存中存储数据的访问完成时引起的延期。内存隐藏延迟是靠内存读取的并发操作来完成的,需要注意的是,指令隐藏的关键目的是使用全部的计算资源,而内存读取的延迟隐藏是为了使用全部的内存带宽,内存延迟的时候,计算资源正在被别的线程束使用,所以我们不考虑内存读取延迟的时候计算资源在做了什么,这两种延迟我们看做两个不同的部门但是遵循相同的道理。我们的根本目的是把计算资源,内存读取的带宽资源全部使用满,这样就能达到理论的最大效率。
- 1. Introduction
- 2. Overview
- End-User Example.在几行代码中,用户可以从现有的深度学习框架中获取模型,并调用TVM API以获得可部署的模块:
 这个编译的runtime模块包含三个组件:最终优化的计算图 (graph),生成的运算符 (lib)和模块参数 (params)。然后,可以使用这些组件将模型部署到目标后端:
这个编译的runtime模块包含三个组件:最终优化的计算图 (graph),生成的运算符 (lib)和模块参数 (params)。然后,可以使用这些组件将模型部署到目标后端: TVM支持多种部署后端,如C ++,Java和Python等语言。 本文的其余部分描述了TVM的架构以及系统程序员如何扩展它以支持新的后端。">本节通过使用示例来介绍其组件来描述TVM。 Figure 2 总结了TVM中的执行步骤及其相应章节。系统首先从现有框架中获取模型作为输入,并将其转换为计算图表示。然后,它执行高级数据流重写以生成优化图。运算符级优化模块必须为此图中的每个融合运算符生成高效代码。操作符以声明性张量描述语言指定,执行细节未指定。TVM为给定的硬件目标的运算符识别可能的代码优化集合。可能的优化形成了一个很大的空间,因此我们使用基于ML的成本模型来查找优化的运算符。最后,系统将生成的代码打包到可部署的模块中。
TVM支持多种部署后端,如C ++,Java和Python等语言。 本文的其余部分描述了TVM的架构以及系统程序员如何扩展它以支持新的后端。">本节通过使用示例来介绍其组件来描述TVM。 Figure 2 总结了TVM中的执行步骤及其相应章节。系统首先从现有框架中获取模型作为输入,并将其转换为计算图表示。然后,它执行高级数据流重写以生成优化图。运算符级优化模块必须为此图中的每个融合运算符生成高效代码。操作符以声明性张量描述语言指定,执行细节未指定。TVM为给定的硬件目标的运算符识别可能的代码优化集合。可能的优化形成了一个很大的空间,因此我们使用基于ML的成本模型来查找优化的运算符。最后,系统将生成的代码打包到可部署的模块中。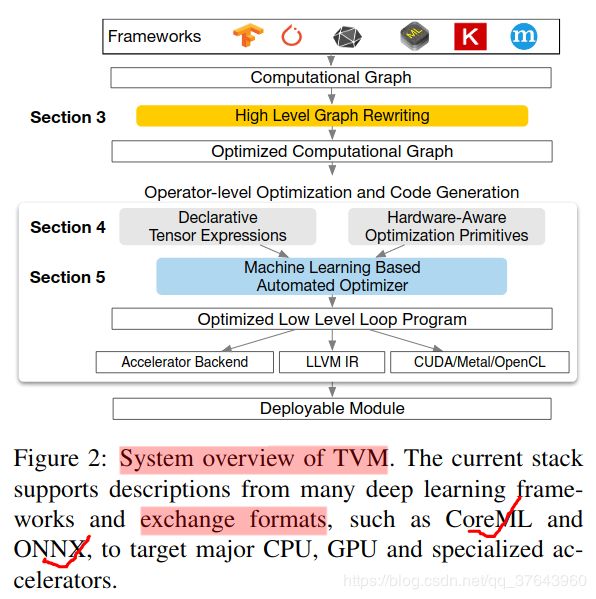 End-User Example.在几行代码中,用户可以从现有的深度学习框架中获取模型,并调用TVM API以获得可部署的模块:这个编译的runtime模块包含三个组件:最终优化的计算图 (graph),生成的运算符 (lib)和模块参数 (params)。然后,可以使用这些组件将模型部署到目标后端:TVM支持多种部署后端,如C ++,Java和Python等语言。 本文的其余部分描述了TVM的架构以及系统程序员如何扩展它以支持新的后端。
End-User Example.在几行代码中,用户可以从现有的深度学习框架中获取模型,并调用TVM API以获得可部署的模块:这个编译的runtime模块包含三个组件:最终优化的计算图 (graph),生成的运算符 (lib)和模块参数 (params)。然后,可以使用这些组件将模型部署到目标后端:TVM支持多种部署后端,如C ++,Java和Python等语言。 本文的其余部分描述了TVM的架构以及系统程序员如何扩展它以支持新的后端。 - withrelay.build_config(opt_level=3):graph, lib, params=relay.build(graph, target, params=params)
# create the runtime modelctx=remote.cpu(0)module=runtime.create(graph, lib, ctx)module.set_input(**params)# set parametermodule.set_input(‘data’, tvm.nd.array(x.astype(‘float32’)))# set input data# runmodule.run()# get outputout=module.get_output(0)# get top1 resulttop1=np.argmax(out.asnumpy())print(‘TVM prediction top-1:{}’.format(synset[top1])) - 3. Optimizing Computational Graphs
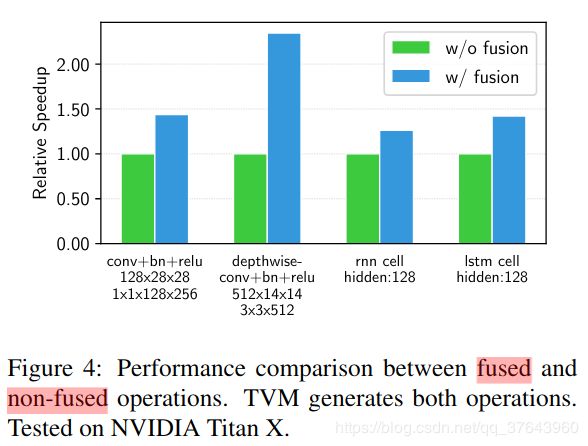
- TVM利用计算图表示来应用高级优化:节点(node)表示对张量或程序输入的操作,边缘(edges)表示操作之间的数据依赖性。TVM实现了许多图级优化,包括:运算符融合(operator fusion),将多个小型运算符融合在一起;常量折叠(constant-folding),预先计算可静态确定的图形部分,节省执行成本;静态内存规划通道(static memory planning pass),预先分配内存以保存每个中间张量;以及数据布局转换(data layout transformations),将内部数据布局转换为后端友好形式。我们现在讨论运算符融合和数据布局转换。Operator Fusion. 运算符融合(operator fusion)将多个运算符组合到一个内核中,而不会将中间结果保存在内存中。这种优化可以大大缩短执行时间,特别是在GPU和专用加速器中。具体来说,我们认识到四类图运算符:(1)单射 injective(一对一映射,例如,add),(2)缩减reduction(例如,sum),(3)复杂可融合 complex-out-fusable(可以将元素映射融合到输出,例如,conv2d),(4)不透明 opaque(不能融合,例如,排序sort)。如下所示,我们提供通用规则来融合这些运算符。多个单射运算符可以融合到另一个单射运算符中。缩减运算符可以与输入的单射运算符融合(例如,fuse scale & sum)。像conv2d 这样的运算符是复杂可融合的,我们可以将元素运算符融合到其输出中。我们可以应用这些规则将计算图转换为融合版。Figure 4 演示了此优化对不同工作负载的影响。我们发现通过减少内存访问,融合运算符可以产生高达1.2到2倍的加速。
 Data Layout Transformation.有多种方法可以在计算图中存储给定的张量。最常见的数据布局选择是列和行。实际上,我们可能更喜欢使用更复杂的数据布局。例如,DL加速器可能利用4 4矩阵操作,要求将数据平铺成4 4块以优化访问位置。数据布局优化将计算图转换为可以在目标硬件上执行的更好的内部数据布局图。它首先根据内存层次结构所规定的约束为每个运算符指定首选数据布局。然后,如果生产者和消费者的首选数据布局不匹配,我们将在生产者和消费者之间进行适当的布局转换。虽然高级图优化可以极大地提高DL工作负载的效率,但它们仅与运算符库提供的效率一样。目前,支持运算符融合的少数DL框架要求运算符库提供融合模式的实现。随着定期引入更多的神经网络运算符,可能的融合内核数量会急剧增加。当针对越来越多的硬件后端时,这种方法不再可持续,因为所需数量的融合模式实现与必须支持的数据布局,数据类型和加速器内在函数的数量组合增长。为程序所需的各种操作和每个后端手工编写操作符内核是不可行的。为此,我们接下来提出了一种代码生成方法,该方法可以为给定模型的运算符生成各种可能的实现。">计算图是在深度学习框架中表示程序的常用方法。Figure 3 展示了一个双层卷积神经网络的示例计算图表示。这种高级表示与低级编译器中间表示(IR)(例如LLVM)之间的主要区别在于中间数据项是大型多维张量。计算图提供了运算符的全局视图,但它们避免指定必须如何实现每个运算符。与LLVM IR一样,计算图可以转换为功能等效的图以应用优化。我们还利用常见深度学习工作负载中的形状特异性来优化固定的输入形状。
Data Layout Transformation.有多种方法可以在计算图中存储给定的张量。最常见的数据布局选择是列和行。实际上,我们可能更喜欢使用更复杂的数据布局。例如,DL加速器可能利用4 4矩阵操作,要求将数据平铺成4 4块以优化访问位置。数据布局优化将计算图转换为可以在目标硬件上执行的更好的内部数据布局图。它首先根据内存层次结构所规定的约束为每个运算符指定首选数据布局。然后,如果生产者和消费者的首选数据布局不匹配,我们将在生产者和消费者之间进行适当的布局转换。虽然高级图优化可以极大地提高DL工作负载的效率,但它们仅与运算符库提供的效率一样。目前,支持运算符融合的少数DL框架要求运算符库提供融合模式的实现。随着定期引入更多的神经网络运算符,可能的融合内核数量会急剧增加。当针对越来越多的硬件后端时,这种方法不再可持续,因为所需数量的融合模式实现与必须支持的数据布局,数据类型和加速器内在函数的数量组合增长。为程序所需的各种操作和每个后端手工编写操作符内核是不可行的。为此,我们接下来提出了一种代码生成方法,该方法可以为给定模型的运算符生成各种可能的实现。">计算图是在深度学习框架中表示程序的常用方法。Figure 3 展示了一个双层卷积神经网络的示例计算图表示。这种高级表示与低级编译器中间表示(IR)(例如LLVM)之间的主要区别在于中间数据项是大型多维张量。计算图提供了运算符的全局视图,但它们避免指定必须如何实现每个运算符。与LLVM IR一样,计算图可以转换为功能等效的图以应用优化。我们还利用常见深度学习工作负载中的形状特异性来优化固定的输入形状。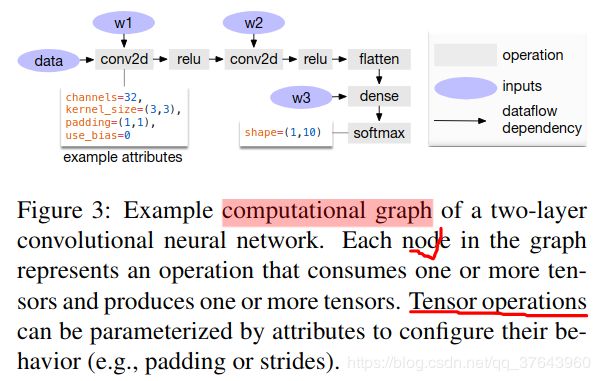 TVM利用计算图表示来应用高级优化:节点(node)表示对张量或程序输入的操作,边缘(edges)表示操作之间的数据依赖性。TVM实现了许多图级优化,包括:运算符融合(operator fusion),将多个小型运算符融合在一起;常量折叠(constant-folding),预先计算可静态确定的图形部分,节省执行成本;静态内存规划通道(static memory planning pass),预先分配内存以保存每个中间张量;以及数据布局转换(data layout transformations),将内部数据布局转换为后端友好形式。我们现在讨论运算符融合和数据布局转换。Operator Fusion. 运算符融合(operator fusion)将多个运算符组合到一个内核中,而不会将中间结果保存在内存中。这种优化可以大大缩短执行时间,特别是在GPU和专用加速器中。具体来说,我们认识到四类图运算符:(1)单射 injective(一对一映射,例如,add),(2)缩减reduction(例如,sum),(3)复杂可融合 complex-out-fusable(可以将元素映射融合到输出,例如,conv2d),(4)不透明 opaque(不能融合,例如,排序sort)。如下所示,我们提供通用规则来融合这些运算符。多个单射运算符可以融合到另一个单射运算符中。缩减运算符可以与输入的单射运算符融合(例如,fuse scale & sum)。像conv2d 这样的运算符是复杂可融合的,我们可以将元素运算符融合到其输出中。我们可以应用这些规则将计算图转换为融合版。Figure 4 演示了此优化对不同工作负载的影响。我们发现通过减少内存访问,融合运算符可以产生高达1.2到2倍的加速。Data Layout Transformation.有多种方法可以在计算图中存储给定的张量。最常见的数据布局选择是列和行。实际上,我们可能更喜欢使用更复杂的数据布局。例如,DL加速器可能利用4 4矩阵操作,要求将数据平铺成4 4块以优化访问位置。数据布局优化将计算图转换为可以在目标硬件上执行的更好的内部数据布局图。它首先根据内存层次结构所规定的约束为每个运算符指定首选数据布局。然后,如果生产者和消费者的首选数据布局不匹配,我们将在生产者和消费者之间进行适当的布局转换。虽然高级图优化可以极大地提高DL工作负载的效率,但它们仅与运算符库提供的效率一样。目前,支持运算符融合的少数DL框架要求运算符库提供融合模式的实现。随着定期引入更多的神经网络运算符,可能的融合内核数量会急剧增加。当针对越来越多的硬件后端时,这种方法不再可持续,因为所需数量的融合模式实现与必须支持的数据布局,数据类型和加速器内在函数的数量组合增长。为程序所需的各种操作和每个后端手工编写操作符内核是不可行的。为此,我们接下来提出了一种代码生成方法,该方法可以为给定模型的运算符生成各种可能的实现。
TVM利用计算图表示来应用高级优化:节点(node)表示对张量或程序输入的操作,边缘(edges)表示操作之间的数据依赖性。TVM实现了许多图级优化,包括:运算符融合(operator fusion),将多个小型运算符融合在一起;常量折叠(constant-folding),预先计算可静态确定的图形部分,节省执行成本;静态内存规划通道(static memory planning pass),预先分配内存以保存每个中间张量;以及数据布局转换(data layout transformations),将内部数据布局转换为后端友好形式。我们现在讨论运算符融合和数据布局转换。Operator Fusion. 运算符融合(operator fusion)将多个运算符组合到一个内核中,而不会将中间结果保存在内存中。这种优化可以大大缩短执行时间,特别是在GPU和专用加速器中。具体来说,我们认识到四类图运算符:(1)单射 injective(一对一映射,例如,add),(2)缩减reduction(例如,sum),(3)复杂可融合 complex-out-fusable(可以将元素映射融合到输出,例如,conv2d),(4)不透明 opaque(不能融合,例如,排序sort)。如下所示,我们提供通用规则来融合这些运算符。多个单射运算符可以融合到另一个单射运算符中。缩减运算符可以与输入的单射运算符融合(例如,fuse scale & sum)。像conv2d 这样的运算符是复杂可融合的,我们可以将元素运算符融合到其输出中。我们可以应用这些规则将计算图转换为融合版。Figure 4 演示了此优化对不同工作负载的影响。我们发现通过减少内存访问,融合运算符可以产生高达1.2到2倍的加速。Data Layout Transformation.有多种方法可以在计算图中存储给定的张量。最常见的数据布局选择是列和行。实际上,我们可能更喜欢使用更复杂的数据布局。例如,DL加速器可能利用4 4矩阵操作,要求将数据平铺成4 4块以优化访问位置。数据布局优化将计算图转换为可以在目标硬件上执行的更好的内部数据布局图。它首先根据内存层次结构所规定的约束为每个运算符指定首选数据布局。然后,如果生产者和消费者的首选数据布局不匹配,我们将在生产者和消费者之间进行适当的布局转换。虽然高级图优化可以极大地提高DL工作负载的效率,但它们仅与运算符库提供的效率一样。目前,支持运算符融合的少数DL框架要求运算符库提供融合模式的实现。随着定期引入更多的神经网络运算符,可能的融合内核数量会急剧增加。当针对越来越多的硬件后端时,这种方法不再可持续,因为所需数量的融合模式实现与必须支持的数据布局,数据类型和加速器内在函数的数量组合增长。为程序所需的各种操作和每个后端手工编写操作符内核是不可行的。为此,我们接下来提出了一种代码生成方法,该方法可以为给定模型的运算符生成各种可能的实现。 - 4. Generating Tensor Operations
- TVM通过在每个硬件后端生成许多有效的实现并选择优化后的实现,为每个运算符生成有效的代码。此过程建立在Halide将描述descriptions与计算规则(或调度优化)分离的概念之上,并将其扩展为支持新的优化(嵌套并行,张量化和延迟隐藏)以及各种硬件后端。我们现在重点介绍TVM特有的功能。
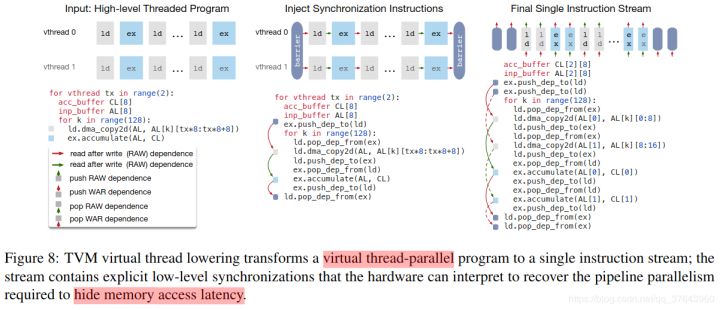
- 编程需要显式低级同步的DAE加速器很困难。为了减少编程负担,我们引入了一个虚拟线程调度原语,它允许程序员指定高级数据并行程序,因为它们是支持多线程的硬件后端。然后,TVM自动将程序降级为具有低级显式同步的单个指令流,如Figure 8 所示。该算法以高级多线程程序计划开始,然后插入必要的低级同步操作来保证每个线程内的正确执行。接下来,它将所有虚拟线程的操作交织成单个指令流。最后,硬件恢复由指令流中的低级同步指示的可用流水线并行性。
 延迟隐藏的硬件评估。我们现在证明延迟隐藏在基于FPGA的加速器设计上的有效性,我们将在6.4小节中深入介绍。我们在加速器上运行ResNet的每一层,并使用TVM生成两个时间表:一个具有延迟隐藏,一个没有。具有延迟隐藏的调度将程序与虚拟线程并行化以暴露管道并行性,从而隐藏存储器访问延迟。结果如Figure 10 所示为屋顶线图[47]; 屋顶线性能图可以深入了解给定系统在不同基准测试中使用计算和内存资源的情况。总体而言,延迟隐藏改善了所有ResNet层的性能。峰值计算利用率从没有延迟隐藏的70%增加到延迟隐藏的88%。
延迟隐藏的硬件评估。我们现在证明延迟隐藏在基于FPGA的加速器设计上的有效性,我们将在6.4小节中深入介绍。我们在加速器上运行ResNet的每一层,并使用TVM生成两个时间表:一个具有延迟隐藏,一个没有。具有延迟隐藏的调度将程序与虚拟线程并行化以暴露管道并行性,从而隐藏存储器访问延迟。结果如Figure 10 所示为屋顶线图[47]; 屋顶线性能图可以深入了解给定系统在不同基准测试中使用计算和内存资源的情况。总体而言,延迟隐藏改善了所有ResNet层的性能。峰值计算利用率从没有延迟隐藏的70%增加到延迟隐藏的88%。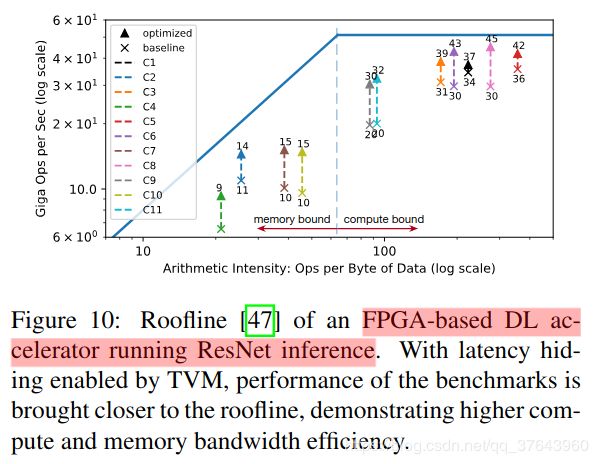 ">延迟隐藏是指通过计算重叠内存操作以最大化内存和计算资源利用率的过程。它需要不同的策略,具体取决于目标硬件后端。在CPU上,内存延迟隐藏是通过同步多线程[14]或硬件预取[10,20]隐式实现的。GPU依赖于许多线程的快速上下文切换[44]。相比之下,特殊化的DL加速器(如TPU [21])通常更倾向于使用解耦访问执行(DAE)架构进行更精简的控制[35],并将细粒度同步问题卸载到软件中。Figure 9 显示了一个减少运行时延迟的DAE硬件管道。与单片硬件设计相比,管道可以隐藏大多数存储器访问,并几乎完全利用计算资源。为了实现更高的利用率,必须使用细粒度的同步操作来扩充指令流。没有它们,就无法强制执行依赖关系,从而导致错误的执行。因此,DAE硬件流水线需要在流水线级之间进行细粒度的依赖入队/出队操作,以保证正确执行,如Figure 9 的指令流所示。
">延迟隐藏是指通过计算重叠内存操作以最大化内存和计算资源利用率的过程。它需要不同的策略,具体取决于目标硬件后端。在CPU上,内存延迟隐藏是通过同步多线程[14]或硬件预取[10,20]隐式实现的。GPU依赖于许多线程的快速上下文切换[44]。相比之下,特殊化的DL加速器(如TPU [21])通常更倾向于使用解耦访问执行(DAE)架构进行更精简的控制[35],并将细粒度同步问题卸载到软件中。Figure 9 显示了一个减少运行时延迟的DAE硬件管道。与单片硬件设计相比,管道可以隐藏大多数存储器访问,并几乎完全利用计算资源。为了实现更高的利用率,必须使用细粒度的同步操作来扩充指令流。没有它们,就无法强制执行依赖关系,从而导致错误的执行。因此,DAE硬件流水线需要在流水线级之间进行细粒度的依赖入队/出队操作,以保证正确执行,如Figure 9 的指令流所示。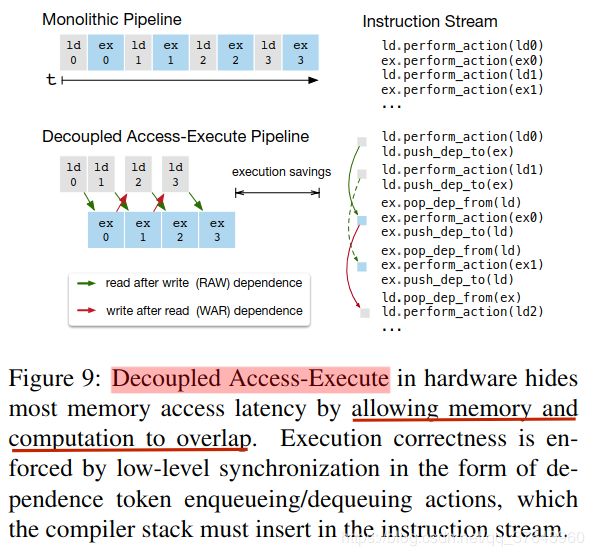 编程需要显式低级同步的DAE加速器很困难。为了减少编程负担,我们引入了一个虚拟线程调度原语,它允许程序员指定高级数据并行程序,因为它们是支持多线程的硬件后端。然后,TVM自动将程序降级为具有低级显式同步的单个指令流,如Figure 8 所示。该算法以高级多线程程序计划开始,然后插入必要的低级同步操作来保证每个线程内的正确执行。接下来,它将所有虚拟线程的操作交织成单个指令流。最后,硬件恢复由指令流中的低级同步指示的可用流水线并行性。延迟隐藏的硬件评估。我们现在证明延迟隐藏在基于FPGA的加速器设计上的有效性,我们将在6.4小节中深入介绍。我们在加速器上运行ResNet的每一层,并使用TVM生成两个时间表:一个具有延迟隐藏,一个没有。具有延迟隐藏的调度将程序与虚拟线程并行化以暴露管道并行性,从而隐藏存储器访问延迟。结果如Figure 10 所示为屋顶线图[47]; 屋顶线性能图可以深入了解给定系统在不同基准测试中使用计算和内存资源的情况。总体而言,延迟隐藏改善了所有ResNet层的性能。峰值计算利用率从没有延迟隐藏的70%增加到延迟隐藏的88%。
编程需要显式低级同步的DAE加速器很困难。为了减少编程负担,我们引入了一个虚拟线程调度原语,它允许程序员指定高级数据并行程序,因为它们是支持多线程的硬件后端。然后,TVM自动将程序降级为具有低级显式同步的单个指令流,如Figure 8 所示。该算法以高级多线程程序计划开始,然后插入必要的低级同步操作来保证每个线程内的正确执行。接下来,它将所有虚拟线程的操作交织成单个指令流。最后,硬件恢复由指令流中的低级同步指示的可用流水线并行性。延迟隐藏的硬件评估。我们现在证明延迟隐藏在基于FPGA的加速器设计上的有效性,我们将在6.4小节中深入介绍。我们在加速器上运行ResNet的每一层,并使用TVM生成两个时间表:一个具有延迟隐藏,一个没有。具有延迟隐藏的调度将程序与虚拟线程并行化以暴露管道并行性,从而隐藏存储器访问延迟。结果如Figure 10 所示为屋顶线图[47]; 屋顶线性能图可以深入了解给定系统在不同基准测试中使用计算和内存资源的情况。总体而言,延迟隐藏改善了所有ResNet层的性能。峰值计算利用率从没有延迟隐藏的70%增加到延迟隐藏的88%。 - 5. Automating Optimization
- 分布式设备池可以扩展硬件试用的运行,并实现多个优化作业之间的细粒度资源共享。TVM实现了一个基于RPC的定制分布式设备池,可以使客户端在特定类型的设备上运行程序。我们可以使用此接口在主机编译器上编译程序,请求远程设备,远程运行该函数,以及在主机上的相同脚本中访问结果。TVM的RPC支持动态上传,并运行使用其运行时约定的交叉编译模块和函数。 因此,相同的基础架构可以执行单个工作负载优化和端到端图推断。我们的方法可以跨多个设备自动执行编译,运行和配置文件步骤。这种基础设施对于嵌入式设备尤其重要,因为嵌入式设备传统上需要繁琐的手动操作来进行交叉编译,代码部署和测量。
- 6. Evaluation
- 7. Related Work
- 深度学习框架为用户提供了方便的接口,用以表示DL工作负载并在不同的硬件后端轻松部署它们。虽然现有框架目前依赖特定供应商的张量运算符库来执行其工作负载,但它们可以利用TVM的堆栈为大量硬件设备生成优化代码。高级计算图DSL(Domain Specified Language) 是表示和执行高级优化的典型方式。Tensorflow的XLA和最近推出的DLVM属于这一类。这些工作中计算图表示是相似的,本文也使用了高级计算图DSL。虽然计算图级表示非常适合高级优化,但它们的级别太高,无法在各种硬件后端优化张量运算符。以前的工作依赖于特定的降低规则来直接生成低级LLVM或使用供应商制作的库。这些方法需要为每个硬件后端和运算符变体组合进行大量的工程工作。Halide介绍了分离计算和调度的想法。我们采用Halide的思想,并在我们的编译器中重用其现有的有用调度原语。我们的张量运算符调度也与用于GPU和基于多面体的循环变换的DSL上的其他工作有关。TACO引入了一种在CPU上生成稀疏张量运算符的通用方法。Weld是用于数据处理任务的DSL。我们专注于解决GPU和专用加速器的DL工作负载的新调度挑战。在这些工作中,优化管道可能会采用我们的新原语。诸如ATLAS [46]和FFTW [15]等高性能库使用自动调整来获得最佳性能。Tensor理解[42]将黑盒自动调整与多面体优化结合使用,以优化CUDA内核。OpenTuner [5]和现有的超参数调整算法[26]应用了域无关的搜索。预定义的成本模型用于在Halide [29]中自动调度图像处理流水线。TVM的ML模型使用有效的域感知成本建模来考虑程序结构。基于分布式的调度优化器可扩展到更大的搜索空间,并且可在大量支持的后端上找到最先进的内核。更重要的是,我们提供了一个端到端的堆栈,可以直接从DL框架中进行描述,并且与计算图级堆栈一起进行联合优化。尽管用于深度学习的加速器越来越受欢迎[11,21],但仍然不清楚如何构建编译栈以有效地针对这些设备。我们评估中使用的VDLA设计提供了一种通用的方法来总结类似TPU的加速器的属性,并为如何编译加速器代码提供了一个具体的案例研究。我们的方法可能有利于将深度学习编译到FPGA的现有系统[34,40]。本文提供了通过张量化和编译器驱动的延迟隐藏有效地定位加速器的通用解决方案。
- 8. Conclusion
【TVM翻译】An Automated End-to-End Optimizing Compiler
Abstract
越来越多的应用需要将机器学习应用到各种各样的硬件设备上。当前框架依赖于特定供应商的运算符库(vendor-specific library),并针对小范围的服务器级GPU进行优化。将工作负载(workloads) 部署到新平台,例如手机,嵌入式设备和加速器(如FPGA,ASIC),需要大量的手动工作。我们发布了TVM,这是一种可提供计算图级优化(graph-level optimization) 和运算符级优化(operator-level optimization) 的编译器,可以为不同硬件后端的深度学习工作负载提供性能可移植性。TVM解决了深度学习面临的优化问题,例如高级运算符融合,映射到任意硬件原语,以及内存延迟隐藏。它还通过采用新颖的,基于学习的成本建模方法来快速搜索代码优化,从而自动优化低级程序来符合硬件特性。实验结果表明,TVM可以提供跨硬件后端的性能,这些后端与用于低功耗CPU,移动GPU和服务器级GPU的最先进的手动调整库相比具有竞争力。我们还展示了TVM针对新加速器后端的能力,例如基于FPGA的通用深度学习加速器。该系统是在几家大公司内部开源和生产使用的。
硬件原语:操作系统用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程。primitive or atomic action 是由若干个机器指令构成的完成某种特定功能的一段程序,具有不可分割性.即原语的执行必须是连续的,在执行过程中不允许被中断。内存延迟隐藏:延迟是指从提出请求到收到响应之间的延期;内存延迟是指等待对系统内存中存储数据的访问完成时引起的延期。内存隐藏延迟是靠内存读取的并发操作来完成的,需要注意的是,指令隐藏的关键目的是使用全部的计算资源,而内存读取的延迟隐藏是为了使用全部的内存带宽,内存延迟的时候,计算资源正在被别的线程束使用,所以我们不考虑内存读取延迟的时候计算资源在做了什么,这两种延迟我们看做两个不同的部门但是遵循相同的道理。我们的根本目的是把计算资源,内存读取的带宽资源全部使用满,这样就能达到理论的最大效率。
1. Introduction
深度学习模型现在可以识别图像,处理自然语言,并且在具有挑战性的战略游戏中击败人类。越来越多的需求是将智能应用程序部署到各种设备,从云服务器到自动驾驶汽车和嵌入式设备。由于硬件特性的多样性,将深度学习(DL)工作负载映射到这些设备而变得复杂,包括嵌入式CPU,GPU,FPGA和ASIC(例如,TPU)。这些硬件目标在内存组织,计算功能单元等方面存在差异,如Figure 1 所示。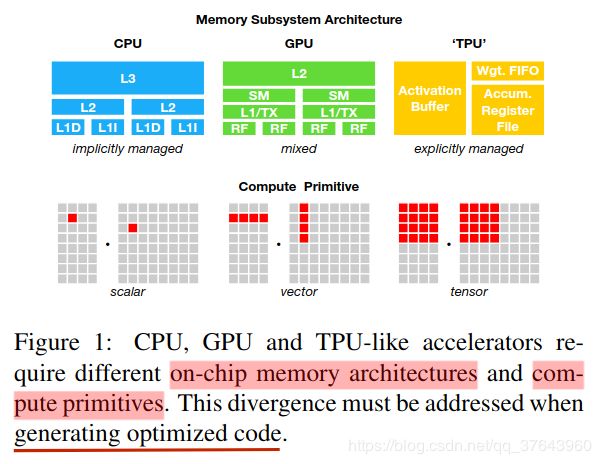 当前的深度学习框架,如TensorFlow,MXNet,Caffe和PyTorch,依赖于计算图中间表示(IR)来实现优化,例如自动微分和动态存储器管理。然而,计算图级优化通常过于高级,无法处理硬件后端特定的运算符级转换。这些框架中的大多数都集中在一小类服务器级GPU设备上,并将特定的目标优化委托给高度工程化和供应商特定的运算符库。这些运算符库需要大量的手动调整,因此过于专业化和不透明,使其无法轻松移植到硬件设备上。在各种深度学习框架中为各种硬件后端提供支持目前需要大量的工程工作。即使对于受支持的后端,框架也必须在以下两者之间做出艰难的选择:(1)避免产生不在预定义运算符库中的新运算符进行图优化,以及(2)使用这些未优化的新运算符进行实现。为了实现各种硬件后端的计算机图和操作符优化,我们采取了一种根本不同的端到端方法。我们构建了TVM,这是一种编译器,它从现有框架中获取深度学习程序的高级规范,并为各种硬件后端生成低级优化代码。为了吸引用户,TVM需要提供与各种硬件后端相关的众多手动优化运算符库相当的性能。该目标需要解决下面描述的关键挑战。利用特定的硬件功能和抽象。深度学习加速器引入了优化的张量计算原语(基元),同时GPU和CPU继续改善他们的处理元素。这对于为给定的运算符描述生成优化代码提出了重大挑战。硬件指令的输入是多维的,具有固定或可变长度; 他们规定了不同的数据布局; 他们对内存层次结构有特殊要求。系统必须有效地利用这些复杂的原语来从加速中受益。此外,加速器设计通常还倾向于更精简的控制并将大多数复杂调度交给编译器堆栈。对于专用加速器,系统现在需要生成显式控制管道依赖性的代码,以隐藏内存访问延迟- 硬件为CPU和GPU执行的工作。用于优化的大型搜索空间。另一个挑战是在不手动调整运算符的情况下生成高效代码。内存访问,线程模式和新颖的硬件原语的组合选择为生成的代码(例如,循环切片和排序,缓存,展开)创建了巨大的配置空间,如果我们实现黑盒子自动调整,则会产生大量的搜索成本。可以采用预定义的成本模型来指导搜索,但由于现代硬件的复杂性日益增加,因此难以建立准确的成本模型。此外,这种方法需要我们为每种硬件类型建立单独的成本模型。TVM利用三个关键模块解决了这些困难。(1)我们提出了一个张量描述语言(tensor expression language)来构建运算符并提供程序转换原语,这些原语通过各种优化以生成不同版本的程序。该层通过将目标硬件内在函数与变换原语分离,扩展了Halide的计算/调度分离概念,从而支持新的加速器及其相应的新内在函数。此外,我们还引入了新的转换原语来解决与GPU相关的挑战,并支持部署到专门的加速器。然后,我们可以应用程序转换的不同序列,以便为给定的运算符声明形成丰富的有效程序空间。(2)我们引入了一个自动程序优化框架(automated program optimization framework)来寻找优化的张量算子。优化器由基于ML的成本模型指导,当我们从硬件后端收集更多数据时,该模型适应并改进。(3)在自动代码生成器之上,我们引入了一个图重写器(graph rewriter),它充分利用了高级和运算符级的优化。通过将以上三个模块组合,TVM可以从现有的深度学习框架中获取模型描述,执行联合的高级和低级优化,并为后端生成特定于硬件的优化代码,例如CPU,GPU和基于FPGA的专业加速器。本文做出以下贡献:
当前的深度学习框架,如TensorFlow,MXNet,Caffe和PyTorch,依赖于计算图中间表示(IR)来实现优化,例如自动微分和动态存储器管理。然而,计算图级优化通常过于高级,无法处理硬件后端特定的运算符级转换。这些框架中的大多数都集中在一小类服务器级GPU设备上,并将特定的目标优化委托给高度工程化和供应商特定的运算符库。这些运算符库需要大量的手动调整,因此过于专业化和不透明,使其无法轻松移植到硬件设备上。在各种深度学习框架中为各种硬件后端提供支持目前需要大量的工程工作。即使对于受支持的后端,框架也必须在以下两者之间做出艰难的选择:(1)避免产生不在预定义运算符库中的新运算符进行图优化,以及(2)使用这些未优化的新运算符进行实现。为了实现各种硬件后端的计算机图和操作符优化,我们采取了一种根本不同的端到端方法。我们构建了TVM,这是一种编译器,它从现有框架中获取深度学习程序的高级规范,并为各种硬件后端生成低级优化代码。为了吸引用户,TVM需要提供与各种硬件后端相关的众多手动优化运算符库相当的性能。该目标需要解决下面描述的关键挑战。利用特定的硬件功能和抽象。深度学习加速器引入了优化的张量计算原语(基元),同时GPU和CPU继续改善他们的处理元素。这对于为给定的运算符描述生成优化代码提出了重大挑战。硬件指令的输入是多维的,具有固定或可变长度; 他们规定了不同的数据布局; 他们对内存层次结构有特殊要求。系统必须有效地利用这些复杂的原语来从加速中受益。此外,加速器设计通常还倾向于更精简的控制并将大多数复杂调度交给编译器堆栈。对于专用加速器,系统现在需要生成显式控制管道依赖性的代码,以隐藏内存访问延迟- 硬件为CPU和GPU执行的工作。用于优化的大型搜索空间。另一个挑战是在不手动调整运算符的情况下生成高效代码。内存访问,线程模式和新颖的硬件原语的组合选择为生成的代码(例如,循环切片和排序,缓存,展开)创建了巨大的配置空间,如果我们实现黑盒子自动调整,则会产生大量的搜索成本。可以采用预定义的成本模型来指导搜索,但由于现代硬件的复杂性日益增加,因此难以建立准确的成本模型。此外,这种方法需要我们为每种硬件类型建立单独的成本模型。TVM利用三个关键模块解决了这些困难。(1)我们提出了一个张量描述语言(tensor expression language)来构建运算符并提供程序转换原语,这些原语通过各种优化以生成不同版本的程序。该层通过将目标硬件内在函数与变换原语分离,扩展了Halide的计算/调度分离概念,从而支持新的加速器及其相应的新内在函数。此外,我们还引入了新的转换原语来解决与GPU相关的挑战,并支持部署到专门的加速器。然后,我们可以应用程序转换的不同序列,以便为给定的运算符声明形成丰富的有效程序空间。(2)我们引入了一个自动程序优化框架(automated program optimization framework)来寻找优化的张量算子。优化器由基于ML的成本模型指导,当我们从硬件后端收集更多数据时,该模型适应并改进。(3)在自动代码生成器之上,我们引入了一个图重写器(graph rewriter),它充分利用了高级和运算符级的优化。通过将以上三个模块组合,TVM可以从现有的深度学习框架中获取模型描述,执行联合的高级和低级优化,并为后端生成特定于硬件的优化代码,例如CPU,GPU和基于FPGA的专业加速器。本文做出以下贡献:
- • 我们确定了主要的优化挑战,即为不同硬件后端的深度学习工作负载提供性能可移植性。
• 我们介绍了新颖的调度原语,它们利用了跨线程内存重用,新颖的硬件内在函数和延迟隐藏的优势。
• 我们提出并实现了一个基于机器学习的优化系统来自动探索并搜索优化的张量运算符。
• 我们构建了一个端到端的编译和优化堆栈,允许将高级框架(包括TensorFlow,MXNet,PyTorch,Keras,CNTK)中指定的深度学习工作负载部署到各种硬件后端(包括CPU, 服务器GPU,移动GPU和基于FPGA的加速器)。开源TVM在几家大公司内部正在生产中使用。
我们在服务器级GPU,嵌入式GPU,嵌入式CPU和基于FPGA的定制通用加速器上使用真实工作负载评估TVM。实验结果表明,TVM提供了跨后端的可移植性,并且比由手工优化库支持的现有框架实现了1.2到3.8倍的加速。
2. Overview
本节通过使用示例来介绍其组件来描述TVM。 Figure 2 总结了TVM中的执行步骤及其相应章节。系统首先从现有框架中获取模型作为输入,并将其转换为计算图表示。然后,它执行高级数据流重写以生成优化图。运算符级优化模块必须为此图中的每个融合运算符生成高效代码。操作符以声明性张量描述语言指定,执行细节未指定。TVM为给定的硬件目标的运算符识别可能的代码优化集合。可能的优化形成了一个很大的空间,因此我们使用基于ML的成本模型来查找优化的运算符。最后,系统将生成的代码打包到可部署的模块中。End-User Example.在几行代码中,用户可以从现有的深度学习框架中获取模型,并调用TVM API以获得可部署的模块:这个编译的runtime模块包含三个组件:最终优化的计算图 (graph),生成的运算符 (lib)和模块参数 (params)。然后,可以使用这些组件将模型部署到目标后端:TVM支持多种部署后端,如C ++,Java和Python等语言。 本文的其余部分描述了TVM的架构以及系统程序员如何扩展它以支持新的后端。
Deploy the Pretrained Model on Raspberry Pi:frommxnet.gluon.model_zoo.visionimportget_modelimporttvmfromtvmimportrelayfromtvmimportrpcfromtvm.contribimportgraph_runtimeasruntime
# one line to get the modelblock=get_model(‘resnet18_v1’, pretrained=True)# port the Gluon model to a computational graphshape_dict={‘data’: x.shape}graph, params=relay.frontend.from_mxnet(block, shape_dict)# compile the graphlocal_demo=False
iflocal_demo:target=tvm.target.creat(‘llvm’)else:target=tvm.target.arm_cpu(‘rasp3b’)
withrelay.build_config(opt_level=3):graph, lib, params=relay.build(graph, target, params=params)
# create the runtime modelctx=remote.cpu(0)module=runtime.create(graph, lib, ctx)module.set_input(**params)# set parametermodule.set_input(‘data’, tvm.nd.array(x.astype(‘float32’)))# set input data
# runmodule.run()
# get outputout=module.get_output(0)
# get top1 resulttop1=np.argmax(out.asnumpy())print(‘TVM prediction top-1:{}’.format(synset[top1]))
3. Optimizing Computational Graphs
计算图是在深度学习框架中表示程序的常用方法。Figure 3 展示了一个双层卷积神经网络的示例计算图表示。这种高级表示与低级编译器中间表示(IR)(例如LLVM)之间的主要区别在于中间数据项是大型多维张量。计算图提供了运算符的全局视图,但它们避免指定必须如何实现每个运算符。与LLVM IR一样,计算图可以转换为功能等效的图以应用优化。我们还利用常见深度学习工作负载中的形状特异性来优化固定的输入形状。TVM利用计算图表示来应用高级优化:节点(node)表示对张量或程序输入的操作,边缘(edges)表示操作之间的数据依赖性。TVM实现了许多图级优化,包括:运算符融合(operator fusion),将多个小型运算符融合在一起;常量折叠(constant-folding),预先计算可静态确定的图形部分,节省执行成本;静态内存规划通道(static memory planning pass),预先分配内存以保存每个中间张量;以及数据布局转换(data layout transformations),将内部数据布局转换为后端友好形式。我们现在讨论运算符融合和数据布局转换。Operator Fusion. 运算符融合(operator fusion)将多个运算符组合到一个内核中,而不会将中间结果保存在内存中。这种优化可以大大缩短执行时间,特别是在GPU和专用加速器中。具体来说,我们认识到四类图运算符:(1)单射 injective(一对一映射,例如,add),(2)缩减reduction(例如,sum),(3)复杂可融合 complex-out-fusable(可以将元素映射融合到输出,例如,conv2d),(4)不透明 opaque(不能融合,例如,排序sort)。如下所示,我们提供通用规则来融合这些运算符。多个单射运算符可以融合到另一个单射运算符中。缩减运算符可以与输入的单射运算符融合(例如,fuse scale & sum)。像conv2d 这样的运算符是复杂可融合的,我们可以将元素运算符融合到其输出中。我们可以应用这些规则将计算图转换为融合版。Figure 4 演示了此优化对不同工作负载的影响。我们发现通过减少内存访问,融合运算符可以产生高达1.2到2倍的加速。Data Layout Transformation.有多种方法可以在计算图中存储给定的张量。最常见的数据布局选择是列和行。实际上,我们可能更喜欢使用更复杂的数据布局。例如,DL加速器可能利用4 4矩阵操作,要求将数据平铺成4 4块以优化访问位置。数据布局优化将计算图转换为可以在目标硬件上执行的更好的内部数据布局图。它首先根据内存层次结构所规定的约束为每个运算符指定首选数据布局。然后,如果生产者和消费者的首选数据布局不匹配,我们将在生产者和消费者之间进行适当的布局转换。虽然高级图优化可以极大地提高DL工作负载的效率,但它们仅与运算符库提供的效率一样。目前,支持运算符融合的少数DL框架要求运算符库提供融合模式的实现。随着定期引入更多的神经网络运算符,可能的融合内核数量会急剧增加。当针对越来越多的硬件后端时,这种方法不再可持续,因为所需数量的融合模式实现与必须支持的数据布局,数据类型和加速器内在函数的数量组合增长。为程序所需的各种操作和每个后端手工编写操作符内核是不可行的。为此,我们接下来提出了一种代码生成方法,该方法可以为给定模型的运算符生成各种可能的实现。
4. Generating Tensor Operations
TVM通过在每个硬件后端生成许多有效的实现并选择优化后的实现,为每个运算符生成有效的代码。此过程建立在Halide将描述descriptions与计算规则(或调度优化)分离的概念之上,并将其扩展为支持新的优化(嵌套并行,张量化和延迟隐藏)以及各种硬件后端。我们现在重点介绍TVM特有的功能。
Halide是用C++作为宿主语言的一个图像处理相关的DSL(Domain Specified Language)语言,全称领域专用语言。其主要作用是在软硬层面上(与算法本身的设计无关)实现对算法的底层加速。因为不论是传统的图像处理方法亦或是深度学习应用都使用到了halide的思想。其中,在OpenCV(传统图像处理库)中部分算法使用了Halide后端,而TVM(神经网络编译器)也是用了Halide的思想去优化神经网络算子。Halide的特点是其图像算法的计算的实现(Function和Expression)和这些计算在计算硬件单元上的调度(Schedule)是分离的,其调度以Function为单位。最终将整个图像算法转换为高效率的多层for循环,for循环的分部数据范围划分和数据加载都是由Halide来完成的,而且可以实现数据的加载和算法计算的Overlay,掩盖数据加载导致的延迟。Halide的Schedule可以由程序员来指定一些策略,指定硬件的buffer大小,缓冲线的相关设置,这样可以根据不同的计算硬件的特性来实现高效率的计算单元的调度,而图像算法的计算实现却不需要修改。Reference URL:图像、神经网络优化利器:了解Halide - Oldpan的个人博客oldpan.me Halidehalide-lang.org—-
Halidehalide-lang.org—-
4.1 Tensor Expression and Schedule Space
我们提出了一种张量描述语言来支持代码自动生成。与高级计算图表示不同,张量操作的实现是不透明的,每个操作在索引公式表达式语言中描述。以下代码显示了用于计算转置矩阵乘法的示例张量描述: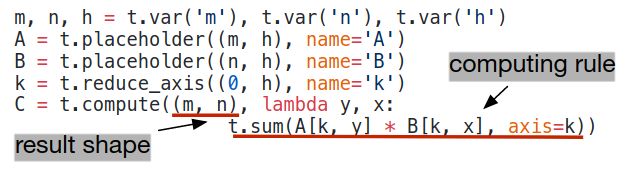 每个计算操作都指定输出张量的形状大小和描述如何计算它的每个元素的表达式。我们的张量描述语言支持常见的算术和数学运算,并涵盖常见的DL运算符模式。该语言未指定循环结构和许多其他执行细节,并且它为各种后端添加硬件感知优化提供了灵活性。采用Halide [32]中的解耦计算/调度原理,我们使用调度来表示从张量表达式到低级代码的特定映射。许多可能的计划可以执行此功能。我们通过逐步应用保留程序逻辑等效性的基本转换(调度原语)来构建调度。Figure 5 显示了在专用加速器上调度矩阵乘法的示例。在内部,TVM使用数据结构来跟踪循环结构和其他信息,因为我们应用了调度转换。所以,此信息可帮助生成给定最终调度的低级代码。
每个计算操作都指定输出张量的形状大小和描述如何计算它的每个元素的表达式。我们的张量描述语言支持常见的算术和数学运算,并涵盖常见的DL运算符模式。该语言未指定循环结构和许多其他执行细节,并且它为各种后端添加硬件感知优化提供了灵活性。采用Halide [32]中的解耦计算/调度原理,我们使用调度来表示从张量表达式到低级代码的特定映射。许多可能的计划可以执行此功能。我们通过逐步应用保留程序逻辑等效性的基本转换(调度原语)来构建调度。Figure 5 显示了在专用加速器上调度矩阵乘法的示例。在内部,TVM使用数据结构来跟踪循环结构和其他信息,因为我们应用了调度转换。所以,此信息可帮助生成给定最终调度的低级代码。 我们的张量描述来自Halide [32],Darkroom [17]和TACO [23]。其增加的主要功能包括支持下面讨论的新调度优化。为了在许多后端实现高性能,我们必须支持足够的调度原语,以涵盖不同硬件后端上的各种优化。Figure 6总结了TVM支持的操作代码生成过程和调度原语。我们重用了来自Halide的有用原语和的低级循环程序AST,我们引入了新的原语来优化GPU和加速器性能。新原语是实现最佳GPU性能和加速器基本原理所必需的。CPU,GPU,TPU类加速器是深度学习的三种重要硬件类型。本节介绍CPU,GPU和TPU类加速器的新优化原语,而第5节介绍如何自动派生有效的调度。
我们的张量描述来自Halide [32],Darkroom [17]和TACO [23]。其增加的主要功能包括支持下面讨论的新调度优化。为了在许多后端实现高性能,我们必须支持足够的调度原语,以涵盖不同硬件后端上的各种优化。Figure 6总结了TVM支持的操作代码生成过程和调度原语。我们重用了来自Halide的有用原语和的低级循环程序AST,我们引入了新的原语来优化GPU和加速器性能。新原语是实现最佳GPU性能和加速器基本原理所必需的。CPU,GPU,TPU类加速器是深度学习的三种重要硬件类型。本节介绍CPU,GPU和TPU类加速器的新优化原语,而第5节介绍如何自动派生有效的调度。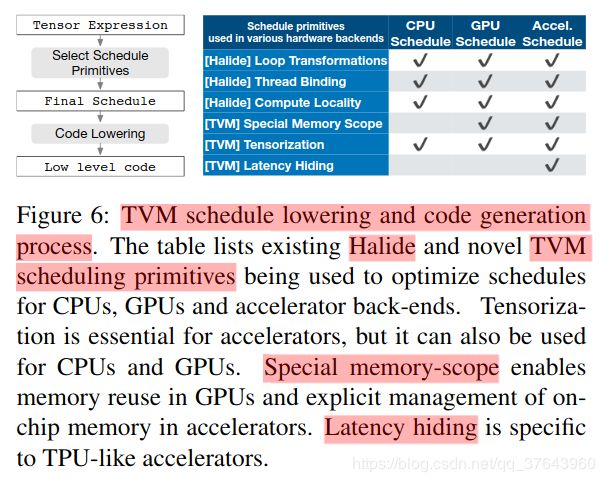
4.2 Nested Parallelism with Cooperation并行性是提高DL工作负载中计算密集型内核效率的关键。现代GPU提供大规模并行性,要求我们将并行模式融入到调度转换中。大多数现有解决方案采用称为嵌套并行的模型,这是一种fork-join形式。该模型需要并行调度原语来并行化数据并行任务; 每个任务可以进一步递归地细分为子任务,以开发目标体系结构的多级线程层次结构(例如,GPU中的线程组)。我们将此模型称为无共享嵌套并行性(shared-nothing nested parallelism),因为一个工作线程无法在同一并行计算阶段查看其兄弟的数据。无共享方法的替代方案是协同获取数据。具体而言,线程组可以协作地获取它们所需的数据并将其放入共享存储空间。此优化可以利用GPU内存层次结构,并通过共享内存区域跨线程实现数据重用。TVM使用调度原语支持这种众所周知的GPU优化,以实现最佳性能。以下GPU代码示例优化了矩阵乘法。 Figure 7 展示了这种优化的影响。我们将内存范围(memory scopes)的概念引入调度空间,以便可以将计算阶段(代码中的AS和BS)标记为共享。如果没有显式的内存范围,自动范围推断会将计算阶段标记为线程本地。共享任务必须计算组中所有工作线程的依赖关系。此外,必须正确插入内存同步障碍,以确保消费者可以看到共享的已加载数据。最后,除了对GPU有用之外,内存范围还允许我们标记特殊的内存缓冲区,并在针对专用DL加速器时创建特殊的降低规则。
Figure 7 展示了这种优化的影响。我们将内存范围(memory scopes)的概念引入调度空间,以便可以将计算阶段(代码中的AS和BS)标记为共享。如果没有显式的内存范围,自动范围推断会将计算阶段标记为线程本地。共享任务必须计算组中所有工作线程的依赖关系。此外,必须正确插入内存同步障碍,以确保消费者可以看到共享的已加载数据。最后,除了对GPU有用之外,内存范围还允许我们标记特殊的内存缓冲区,并在针对专用DL加速器时创建特殊的降低规则。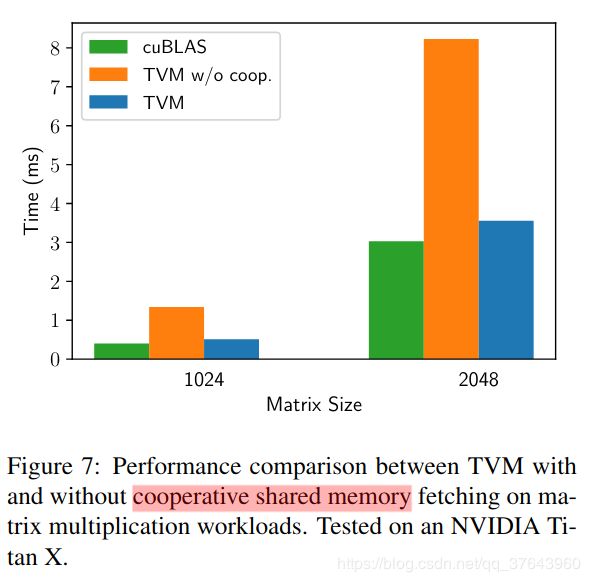
4.3 Tensorization DL工作负载具有高算术强度,通常可以将其分解为张量运算符,如矩阵 - 矩阵乘法或1D卷积。这些自然分解最近产生了添加张量计算原语的趋势[1,12,21]。这些新原语为基于调度的编译创造了机会和挑战; 使用它们可以提高性能,编译框架必须无缝集成它们。我们称这种张量化:它类似于SIMD架构的矢量化,但有很大差异。指令输入是多维的,具有固定或可变长度,并且每个都具有不同的数据布局。更重要的是,我们不能支持一组固定的原语,因为新的加速器正在出现其张量指令的变化。因此,我们需要一个可扩展的解决方案。我们通过使用张量内在声明机制将目标硬件内在与调度分离来使张量化可扩展。我们使用相同的张量描述语言来声明每个新硬件内在的行为和与之相关的降低规则。以下代码显示了如何声明8 * 8张量硬件内在函数。
另外,我们引入了一个张量调度原语来用相应的内在函数替换计算单元。编译器将计算模式与硬件声明匹配,并将其降低到相应的硬件内部。张量化将调度与特定硬件原语分离,从而可以轻松扩展TVM以支持新的硬件体系结构。生成的张量调度代码与高性能计算中的实践保持一致:将复杂操作分解为一系列微内核调用。我们还可以使用张量原语来利用手工制作的微内核,这在某些平台上可能是有益的。例如,我们通过利用位串行矩阵向量乘法微内核,为移动CPU实现超低精度运算符,这些运算符在一位或两位宽的数据类型上运行。该微内核将结果累积为逐渐变大的数据类型,以最小化内存占用。将微内核呈现为TVM固有的张量,可以比非张量版本提高1.5倍的速度。### 4.4 Explicit Memory Latency Hiding
延迟隐藏是指通过计算重叠内存操作以最大化内存和计算资源利用率的过程。它需要不同的策略,具体取决于目标硬件后端。在CPU上,内存延迟隐藏是通过同步多线程[14]或硬件预取[10,20]隐式实现的。GPU依赖于许多线程的快速上下文切换[44]。相比之下,特殊化的DL加速器(如TPU [21])通常更倾向于使用解耦访问执行(DAE)架构进行更精简的控制[35],并将细粒度同步问题卸载到软件中。Figure 9 显示了一个减少运行时延迟的DAE硬件管道。与单片硬件设计相比,管道可以隐藏大多数存储器访问,并几乎完全利用计算资源。为了实现更高的利用率,必须使用细粒度的同步操作来扩充指令流。没有它们,就无法强制执行依赖关系,从而导致错误的执行。因此,DAE硬件流水线需要在流水线级之间进行细粒度的依赖入队/出队操作,以保证正确执行,如Figure 9 的指令流所示。编程需要显式低级同步的DAE加速器很困难。为了减少编程负担,我们引入了一个虚拟线程调度原语,它允许程序员指定高级数据并行程序,因为它们是支持多线程的硬件后端。然后,TVM自动将程序降级为具有低级显式同步的单个指令流,如Figure 8 所示。该算法以高级多线程程序计划开始,然后插入必要的低级同步操作来保证每个线程内的正确执行。接下来,它将所有虚拟线程的操作交织成单个指令流。最后,硬件恢复由指令流中的低级同步指示的可用流水线并行性。延迟隐藏的硬件评估。我们现在证明延迟隐藏在基于FPGA的加速器设计上的有效性,我们将在6.4小节中深入介绍。我们在加速器上运行ResNet的每一层,并使用TVM生成两个时间表:一个具有延迟隐藏,一个没有。具有延迟隐藏的调度将程序与虚拟线程并行化以暴露管道并行性,从而隐藏存储器访问延迟。结果如Figure 10 所示为屋顶线图[47]; 屋顶线性能图可以深入了解给定系统在不同基准测试中使用计算和内存资源的情况。总体而言,延迟隐藏改善了所有ResNet层的性能。峰值计算利用率从没有延迟隐藏的70%增加到延迟隐藏的88%。
5. Automating Optimization
有了丰富的调度基元集,我们剩下的问题是为DL模型的每一层找到最佳运算符实现。在这里,TVM为与每个层相关的特定输入形状和布局创建了一个专门的操作符。这种专业化提供了显着的性能优势(与针对较小的形状和布局的手工编码相比),但它也带来了自动化挑战。系统需要选择计划优化 - 例如修改循环顺序或优化内存层次结构,以及特定于计划的参数,例如平铺大小和循环展开因子。这种组合选择为每个硬件后端创建了大型的运营商实现搜索空间。为了应对这一挑战,我们构建了一个自动调度优化器,其中包含两个主要组件:一个提供有前途的新配置的调度管理器,以及一个预测给定配置性能的机器学习成本模型。本节介绍这些组件和TVM的自动优化流程(Figure 11)。 ### 5.1 Schedule Space Specification
我们构建了一个调度模板规范API,让开发人员在计划空间中声明旋钮knobs。在指定可能的调度时,模板规范允许在必要时结合开发人员的特定于域的知识。我们还为每个硬件后端创建了一个通用的主模板,它可以根据使用张量描述语言表达的计算描述自动提取可能的旋钮。在较高的层面上,我们希望考虑尽可能多的配置,让优化器管理选择负担。因此,优化器必须搜索过多的可能配置,以用于我们实验中使用的真实DL工作负载。### 5.2 ML-Based Cost Model
从大型配置空间中找到最佳时间表的一种方法是通过黑盒优化,即自动调整(auto-tuning)。该方法用于调整高性能计算库[15,46]。但是,自动调整需要许多实验来识别良好的配置。另一种方法是构建预定义的成本模型(predefined cost model),以指导搜索特定硬件后端,而不是运行所有可能性并测量其性能。理想情况下,完美的成本模型会考虑影响性能的所有因素:内存访问模式,数据重用,流水线依赖性和线程模式等。遗憾的是,由于现代硬件的复杂性日益增加,这种方法很麻烦。此外,每个新硬件目标都需要新的预定义成本模型。我们采用统计方法来解决成本建模问题。在此方法中,调度管理器提出可以改善运算符的性能配置。对于每个调度配置,我们使用ML模型将降低的循环程序作为输入并预测其在给定硬件后端上的运行时间。使用在探索期间收集的runtime测量数据训练的模型不需要用户输入详细的硬件信息。我们定期更新模型,因为我们在优化期间探索更多配置,这也提高了其他相关工作负载的准确性。通过这种方式,ML模型的质量随着更多的实验试验而提高。Table 1 总结了自动化方法之间的主要区别。基于ML的成本模型在自动调整和预定义成本建模之间取得平衡,并且可以从相关工作负载的历史性能数据中受益。
### 5.1 Schedule Space Specification
我们构建了一个调度模板规范API,让开发人员在计划空间中声明旋钮knobs。在指定可能的调度时,模板规范允许在必要时结合开发人员的特定于域的知识。我们还为每个硬件后端创建了一个通用的主模板,它可以根据使用张量描述语言表达的计算描述自动提取可能的旋钮。在较高的层面上,我们希望考虑尽可能多的配置,让优化器管理选择负担。因此,优化器必须搜索过多的可能配置,以用于我们实验中使用的真实DL工作负载。### 5.2 ML-Based Cost Model
从大型配置空间中找到最佳时间表的一种方法是通过黑盒优化,即自动调整(auto-tuning)。该方法用于调整高性能计算库[15,46]。但是,自动调整需要许多实验来识别良好的配置。另一种方法是构建预定义的成本模型(predefined cost model),以指导搜索特定硬件后端,而不是运行所有可能性并测量其性能。理想情况下,完美的成本模型会考虑影响性能的所有因素:内存访问模式,数据重用,流水线依赖性和线程模式等。遗憾的是,由于现代硬件的复杂性日益增加,这种方法很麻烦。此外,每个新硬件目标都需要新的预定义成本模型。我们采用统计方法来解决成本建模问题。在此方法中,调度管理器提出可以改善运算符的性能配置。对于每个调度配置,我们使用ML模型将降低的循环程序作为输入并预测其在给定硬件后端上的运行时间。使用在探索期间收集的runtime测量数据训练的模型不需要用户输入详细的硬件信息。我们定期更新模型,因为我们在优化期间探索更多配置,这也提高了其他相关工作负载的准确性。通过这种方式,ML模型的质量随着更多的实验试验而提高。Table 1 总结了自动化方法之间的主要区别。基于ML的成本模型在自动调整和预定义成本建模之间取得平衡,并且可以从相关工作负载的历史性能数据中受益。
机器学习模型设计选择。在选择调度管理器使用的ML模型时,我们必须考虑两个关键因素:质量和速度。调度管理器经常查询成本模型,由于模型预测时间和模型重新设置时间而导致开销。为了有用,这些开销必须小于在真实硬件上测量性能所花费的时间,这可能是几秒钟,具体取决于特定的工作负载/硬件目标。这种速度要求将我们的问题与传统的超参数调整问题区分开来,传统的超参数调整问题相对于模型开销而言执行测量的成本非常高,并且可以使用更昂贵的模型。除了模型的选择,我们还需要选择一个目标函数来训练模型,例如配置预测的运行时间中的错误。但是,由于资源管理器仅根据预测的相对顺序(A运行速度快于B)选择最高候选项,因此我们无需直接预测绝对执行时间。相反,我们使用排名来预测运行时成本的相对顺序。我们在ML优化器中实现了几种类型的模型。我们采用gradient tree boosting模型(基于XGBoost [8]),它基于从循环程序中提取的特征进行预测;这些功能包括每个循环级别的每个内存缓冲区的内存访问计数和重用率,以及循环注释的单热编码,如“vectorize”,“unroll”和“parallel”。我们还评估神经元使用TreeRNN[38]的网络模型在没有特征工程的情况下总结循环程序的AST。Figure 13 总结了成本模型的工作流程。我们发现tree boosting和TreeRNN具有相似的预测质量。然而,前者执行预测的速度是后者的两倍,并且花费更少的时间训练。因此,我们选择gradient tree boosting作为我们实验中的默认成本模型。尽管如此,我们认为这两种方法都很有价值,并期望在此问题上有更多未来研究。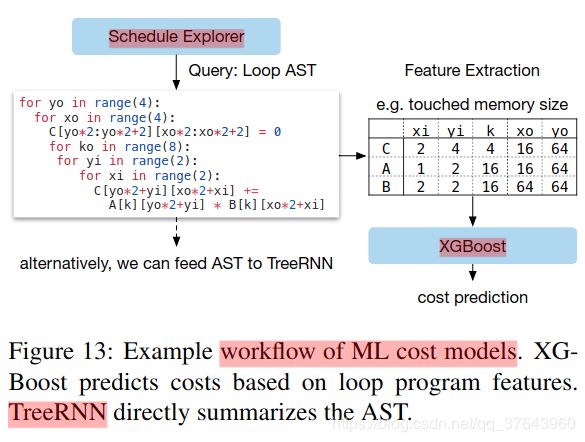 平均而言,tree boosting模型在0.67毫秒内进行预测,比运行实际测量快数千倍。Figure 12 比较了基于ML的优化器和黑盒自动调整方法; 前者比后者更快地发现更好配置。
平均而言,tree boosting模型在0.67毫秒内进行预测,比运行实际测量快数千倍。Figure 12 比较了基于ML的优化器和黑盒自动调整方法; 前者比后者更快地发现更好配置。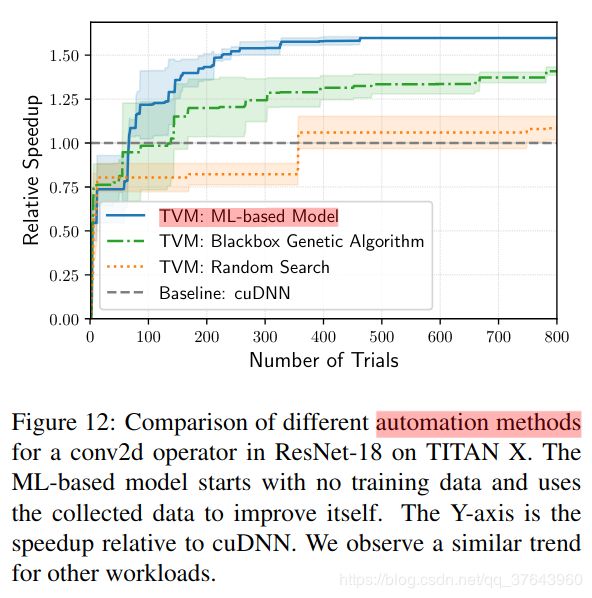
### 5.3 Schedule Exploration
一旦我们选择了成本模型,我们就可以使用它来选择更好的配置,在这些配置上迭代运行实际测量。在每次迭代中,调度管理器使用ML模型的预测来选择要运行测量的一批候选项。然后将收集的数据用作训练数据以更新模型。如果不存在初始训练数据,则调度管理器会选择要测量的随机候选者。最简单的探索算法通过成本模型枚举并运行每个配置,选择前k个预测的执行者。但是,这种策略在大型搜索空间中变得难以处理。相反,我们运行并行模拟退火算法[22]。调度管理器以随机配置开始,并在每个步骤中随机走到附近的配置。如果成本模型预测成本降低,则此转换是成功的。如果目标配置具有更高的成本,则可能失败(拒绝)。随机游走倾向于收敛于成本模型预测的具有较低成本的配置。成本模型更新时探索状态持续存在,我们会在这些更新后继续上一次配置。### 5.4 Distributed Device Pool and RPC
分布式设备池可以扩展硬件试用的运行,并实现多个优化作业之间的细粒度资源共享。TVM实现了一个基于RPC的定制分布式设备池,可以使客户端在特定类型的设备上运行程序。我们可以使用此接口在主机编译器上编译程序,请求远程设备,远程运行该函数,以及在主机上的相同脚本中访问结果。TVM的RPC支持动态上传,并运行使用其运行时约定的交叉编译模块和函数。 因此,相同的基础架构可以执行单个工作负载优化和端到端图推断。我们的方法可以跨多个设备自动执行编译,运行和配置文件步骤。这种基础设施对于嵌入式设备尤其重要,因为嵌入式设备传统上需要繁琐的手动操作来进行交叉编译,代码部署和测量。
6. Evaluation
6.1 Server-Class GPU Evaluation
6.2 Embedded CPU Evaluation
6.3 Embedded GPU Evaluation
对于我们的 mobile GPU实验,我们在配备ARM Mali-T860 MP4 GPU的 Firefly-RK3399板上运行我们的端到端管道。基线是供应商提供的库,即ARM Compute Library(v18.03)。如 Figure 19 所示,我们在三个可用模型的float 16和float 32上表现优于基线(基线尚不支持DCGAN和LSTM)。加速范围从1.2到1.6倍。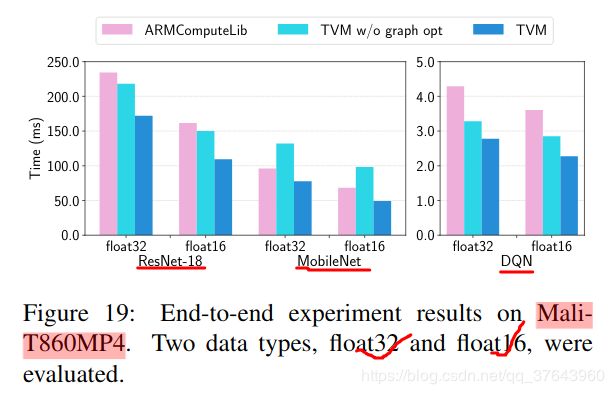
### 6.4 FPGA Accelerator Evaluation
7. Related Work
深度学习框架为用户提供了方便的接口,用以表示DL工作负载并在不同的硬件后端轻松部署它们。虽然现有框架目前依赖特定供应商的张量运算符库来执行其工作负载,但它们可以利用TVM的堆栈为大量硬件设备生成优化代码。高级计算图DSL(Domain Specified Language) 是表示和执行高级优化的典型方式。Tensorflow的XLA和最近推出的DLVM属于这一类。这些工作中计算图表示是相似的,本文也使用了高级计算图DSL。虽然计算图级表示非常适合高级优化,但它们的级别太高,无法在各种硬件后端优化张量运算符。以前的工作依赖于特定的降低规则来直接生成低级LLVM或使用供应商制作的库。这些方法需要为每个硬件后端和运算符变体组合进行大量的工程工作。Halide介绍了分离计算和调度的想法。我们采用Halide的思想,并在我们的编译器中重用其现有的有用调度原语。我们的张量运算符调度也与用于GPU和基于多面体的循环变换的DSL上的其他工作有关。TACO引入了一种在CPU上生成稀疏张量运算符的通用方法。Weld是用于数据处理任务的DSL。我们专注于解决GPU和专用加速器的DL工作负载的新调度挑战。在这些工作中,优化管道可能会采用我们的新原语。诸如ATLAS [46]和FFTW [15]等高性能库使用自动调整来获得最佳性能。Tensor理解[42]将黑盒自动调整与多面体优化结合使用,以优化CUDA内核。OpenTuner [5]和现有的超参数调整算法[26]应用了域无关的搜索。预定义的成本模型用于在Halide [29]中自动调度图像处理流水线。TVM的ML模型使用有效的域感知成本建模来考虑程序结构。基于分布式的调度优化器可扩展到更大的搜索空间,并且可在大量支持的后端上找到最先进的内核。更重要的是,我们提供了一个端到端的堆栈,可以直接从DL框架中进行描述,并且与计算图级堆栈一起进行联合优化。尽管用于深度学习的加速器越来越受欢迎[11,21],但仍然不清楚如何构建编译栈以有效地针对这些设备。我们评估中使用的VDLA设计提供了一种通用的方法来总结类似TPU的加速器的属性,并为如何编译加速器代码提供了一个具体的案例研究。我们的方法可能有利于将深度学习编译到FPGA的现有系统[34,40]。本文提供了通过张量化和编译器驱动的延迟隐藏有效地定位加速器的通用解决方案。
8. Conclusion
我们提出了一个端到端的编译堆栈,以解决跨多种硬件后端深度学习的基本优化挑战。我们的系统包括自动端到端优化,这在历史上是一项劳动密集型和高度专业化的任务。我们希望这项工作能够鼓励对端到端编译方法进行更多研究,并为深度学习系统软件 - 硬件协同设计技术开辟新的机会。

若有收获,就点个赞吧
0 人点赞
