利用TVM优化ARM GPU上的移动深度学习
随着深度学习的巨大成功,对移动设备部署深度神经网络的需求正在迅速增长。与我们在桌面平台上的工作类似,在移动设备中使用GPU可以同时提高推理速度和能效。但是,大多数现有的深度学习框架都不能很好地支持移动GPU。难点在于移动GPU架构和桌面GPU架构之间的差异。这意味着在移动GPU上进行优化需要花费更多精力。导致移动GPU在大多数深度学习框架中的支持不友好。
TVM通过引入统一的IR堆栈解决了部署不同硬件的难度,通过该堆栈可以轻松完成对不同硬件的优化。在这篇文章中,我们将展示如何使用 TVM / NNVM为ARM Mali GPU生成高效的内核并进行端到端编译。在我们对Mali-T860 MP4的测试中,与Arm Compute Library相比 ,我们的方法在VGG-16上快了1.4倍,在MobileNet上快了2.2倍。图形级和操作级优化都有助于提高速度。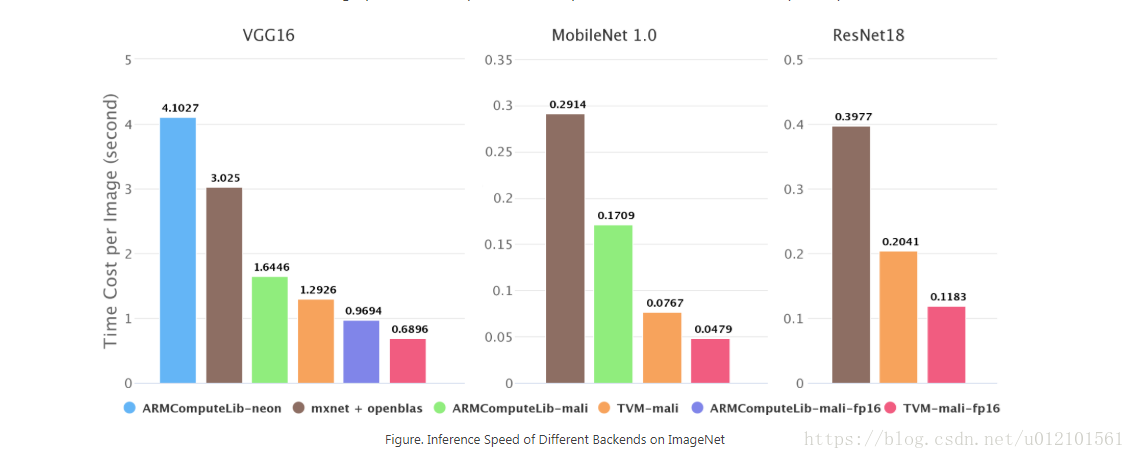
Mali Midgrad GPU
我们将使用Firefly-RK3399和Mali-T860 MP4作为我们的测试环境,因此我们主要关注下面的Mali T8xx。
架构
图1是T860和T880上Mali Architecture的概述。GPU可扩展至16个相干着色器核心。在每个着色器核心内部,有2或3个算术管道,1个加载/存储管道和1个纹理管道(所谓的TriPipe)。每个算术流水线中的ALU具有四个128位向量单元和一个标量单元。
我们使用OpenCL进行GPU计算。映射到OpenCL模型时,每个着色器核心都会执行一个或多个工作组。每个着色器核心最多支持384个并发执行的线程。OpenCL中的每个工作项通常映射到Mali GPU上的单个线程。Mali GPU使用VLIW(超长指令字)架构。每个指令字包含多个操作。Mali GPU也使用SIMD,因此大多数算术指令同时对多个数据元素进行操作。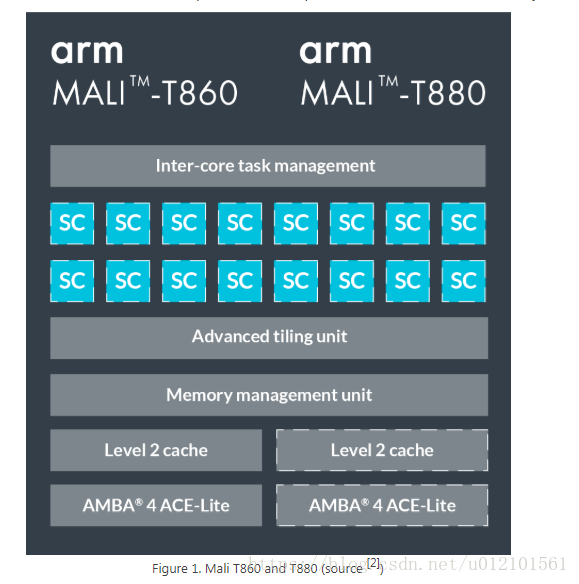
与NVIDIA的GPU不同
与为NVIDIA的GPU编写代码相比,在为Mali GPU编写OpenCL代码时,我们应该关注一些差异。
- Mali GPU使用统一的全局内存。在NVIDIA的GPU中,我们通常将数据复制到共享内存,因为NVIDIA的GPU具有物理上独立的全局内存,共享内存和寄存器。在马里,此副本不会提高性能,可以删除。此外,Mali GPU通常与CPU共享全局内存,因此不需要在CPU和GPU之间进行复制。
- Mali Midgrad GPU基于SIMD(单指令多数据)并需要显式矢量化。在NVIDIA CUDA中,并行性是通过SIMT(单指令多线程)实现的,不需要显式矢量化。但另请注意,较新的Mali Bitfrost GPU基于四元矢量化,不需要显式矢量化。
- Mali GPU中的所有线程都有单独的程序计数器。它意味着
warp size是1,因此分支差异不是主要问题。优化:卷积为例
卷积层是大多数深度神经网络的核心,占用了大部分的计算时间。因此,我们以卷积层为例,演示如何在TVM中应用包装,平铺,展开和矢量化等常用优化技术。Im2Col与GEMM
众所周知的卷积层算法是im2col,它将小的3D输入立方体转换为矩阵的列并执行GEMM。该方法的优点是易于利用高度优化的BLAS库。但是,内存冗余(3x3内核的9倍内存)非常糟糕。空间包装
相反,我们采用一种方法来计算卷积,并逐步应用优化技术。VGG-16中的卷积层用作调谐情况,其配置如下所示。我们假设批量大小为1用于推断。 | input shape
| —- | —- | —- | —- | —- | | 56x56x256| output shape| kernel size| stride| pad|
| 56x56x256| 3×3| (1,1)| (1,1)|
作为baseline,我们还在Arm Compute Library中列出了该层的性能。 | kernel | cost(second) | GFLOPS | | —- | —- | —- | | ARM Compute Lib中的GEMM方法 | 0.1821 | 20.3111 |
声明计算:平铺和打包(tiling and packing)
平铺和打包是两种旨在更好地访问内存的方法。平铺将整个计算分成小块以获得更好的数据使用。打包根据平铺重新排列输入矩阵,以便我们可以顺序访问内存,从而降低缓存未命中率。
我们对输入图像的宽度尺寸和滤波器矩阵的CO尺寸进行平铺。这是由tvm.compute描述。
1. 1# set tiling factor1. 211. 341. 41. 5# get input shape1. 61. 71. 821. 921. 101. 11# calc output shape1. 122// H_STR + 11. 132// W_STR + 11. 141. 15# data shape after packing1. 16// (VH*H_STRIDE), TW // (VW*W_STRIDE), CI, VH*H_STRIDE+HCAT, VW*W_STRIDE+WCAT)1. 171. 18# kernel shape after packing1. 19// VC, CI, KH, KW, VC)1. 201. 21// VC, OH // VH, OW // VW, VH, VW, VC)1. 221. 231. 24# define packing1. 251. 26'data_vec'1. 271. 281. 29'kernel_vec'1. 301. 31# define convolution1. 320'ci'1. 330'kh'1. 340'kw'1. 351. 361. 371. 381. 39'conv'1. 401. 41# unpack to correct layout1. 421. 43//VC][h/VH][w//VW][h%VH][w%VW][co%VC],1. 44'output_unpack''direct_conv_output'
我们可以检查定义的IR
print(tvm.lower(s, [data, kernel, output], simple_mode=True))
我在这里选择卷积部分。
1. 11. 2for0641. 3for0561. 4for0141. 5forinit041. 6forinit041. 756144init4init01. 81. 91. 10for02561. 11for031. 12for031. 13for041. 14for041. 1556144456144414256362563341. 161. 171. 181. 191. 201. 211. 221. 231. 24
内核1:绑定线程
在TVM中,我们首先声明计算然后安排它。该机制将算法和实现细节分离。(这个想法来自Halide)。
以下计划简单地将轴绑定到GPU线程,以便我们的代码可以在Mali GPU上运行。
1. 1# helper function for binding thread1. 2def tile_and_bind3d(s, tensor, z, y, x, z_factor=2, y_factor=None, x_factor=None):1. 3""" tile and bind 3d """1. 4or1. 5or1. 61. 71. 81. 9"blockIdx.z"1. 10"threadIdx.z"1. 11"blockIdx.y"1. 12"threadIdx.y"1. 13"blockIdx.x"1. 14"threadIdx.x"1. 151. 16# set tunable parameter1. 1781. 181. 19# schedule data packing1. 201. 2111. 221. 23# schedule kernel packing1. 241. 2511. 261. 27# schedule conv1. 281. 291. 301. 311. 32111. 331. 341. 3511
使用这个计划,我们的代码现在可以运行,但性能很糟糕。 | 核心 | 成本(秒) | GFLOPS | 加速 | | —- | —- | —- | —- | | ARMComputeLib中的GEMM方法 | 0.1821 | 20.3111 | 1X | | 内核1:简单绑定 | 5.6154 | 0.6588 | 0.03X |
内核2:展开
循环展开可以减少循环控制的指令,减少分支惩罚并隐藏读取内存中的延迟。在TVM中,这可以通过呼叫轻松完成s.unroll(axis)
1. 1# set tunable parameter1. 281. 31. 4# schedule data packing1. 51. 611. 71. 8"""!! ADD UNROLL HERE !!"""1. 91. 101. 11# schedule kernel packing1. 121. 1311. 141. 15"""!! ADD UNROLL HERE !!"""1. 161. 171. 181. 191. 20# schedule conv1. 211. 221. 231. 241. 25111. 261. 27"""!! ADD UNROLL HERE !!"""1. 281. 291. 301. 311. 321. 331. 3411
| 核心 | 成本(秒) | GFLOPS | 加速 | | —- | —- | —- | —- | | ARMComputeLib中的GEMM方法 | 0.1821 | 20.3111 | 1X | | 内核1:简单绑定 | 5.6154 | 0.6588 | 0.03X | | 内核2:+展开 | 0.3707 | 9.9796 | 0.49x |
Kernel3:矢量化
如前所述,我们需要明确地进行矢量化,以便在Mali GPU上实现最佳性能。
1. 1# set tunable parameter1. 281. 31. 4# schedule data packing1. 51. 611. 71. 8# unroll1. 91. 101. 11# schedule kernel packing1. 121. 1311. 141. 15# unroll1. 161. 171. 18"""!! VECTORIZE HERE !!"""1. 191. 201. 21# schedule conv1. 221. 231. 241. 251. 26111. 271. 28# unroll1. 291. 301. 311. 32"""!! VECTORIZE HERE !!"""1. 331. 341. 351. 3611
| 核心 | 成本(秒) | GFLOPS | 加速 | | —- | —- | —- | —- | | ARMComputeLib中的GEMM方法 | 0.1821 | 20.3111 | 1X | | 内核1:简单绑定 | 5.6154 | 0.6588 | 0.03X | | 内核2:+展开 | 0.3707 | 9.9796 | 0.49x | | 内核3:+矢量化 | 0.1304 | 28.3679 | 1.40x |
如何设置可调参数
至于上面的可调参数,可以计算一些。对于矢量化维度VC,我们应该填充128位寄存器,因此对于float32可以设置为128/32 = 4,对于float16,可以设置为128/16 = 8。
但由于运行时间复杂,我们更常无法确定最佳值。我们在TVM中使用网格搜索。由于我们在TVM的高级IR而不是直接的OpenCL代码中编写python代码,因此它可以非常有效。
生成的OpenCL代码
我们可以通过查看生成的OpenCL代码
print(func.imported_modules[0].get_source())
OpenCL代码太长而无法在此处粘贴,并且由于大量展开而难以阅读。如果有兴趣,可以 在这里查看。
端到端基准测试
在本节中,我们比较了一些流行的深度神经网络上不同后端之间的综合性能。我们的测试环境是
1. 1Firefly-RK3399G1. 2CPUdual-coreCortex-A72quad-coreCortex-A531. 3GPUMali-T860MP41. 41. 5ArmComputeLibraryv17.121. 6MXNetv1.0.11. 7Openblasv0.2.18
我们使用NNVM和TVM进行端到端编译。
性能
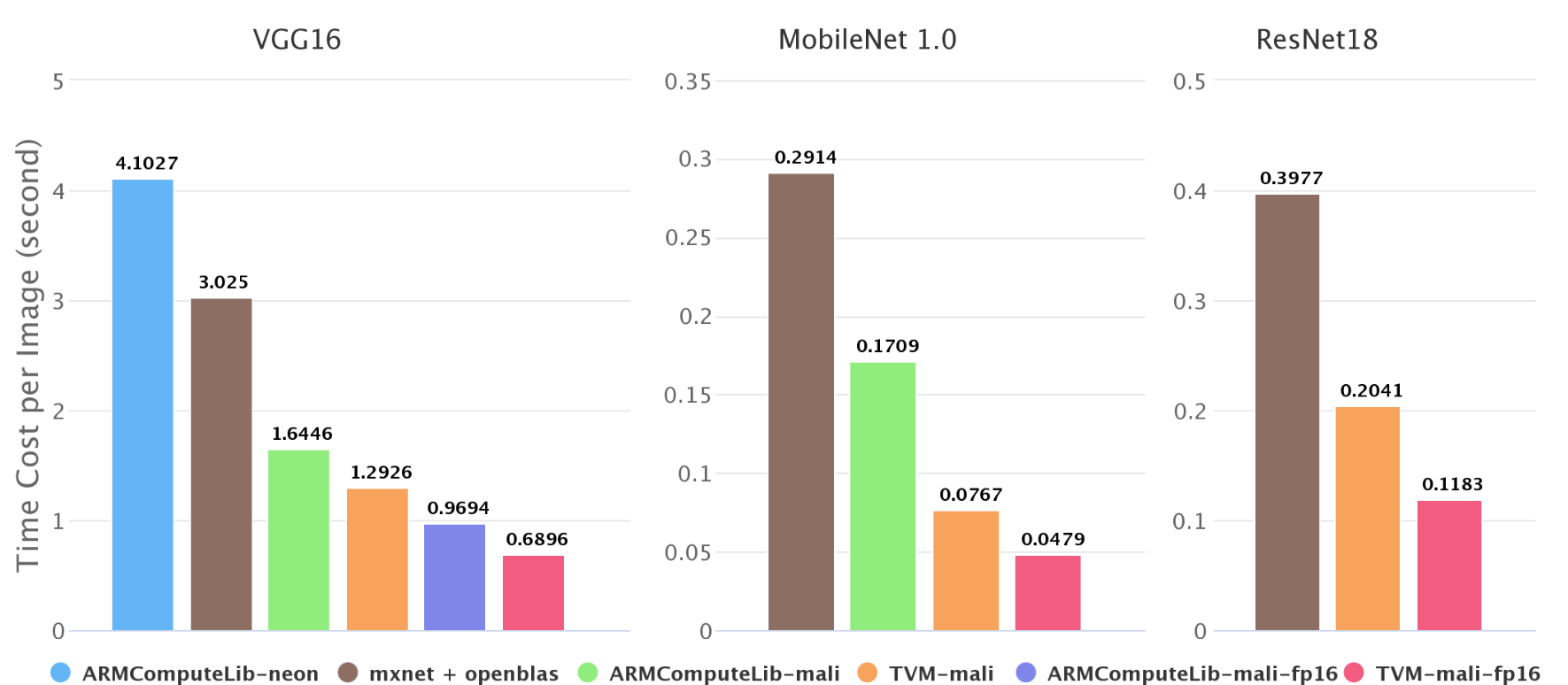
图2. ImageNet上不同后端的推理速度
如图2所示,我们测试了ImageNet上的推理速度。在Firefly-RK3399上,Mali GPU比6核big.LITTLE CPU快2倍~4倍。我们的端到端管道比Arm Compute Library快1.4倍~2.2倍。我们在Arm Compute Library中尝试了GEMM和卷积层的直接方法,在这些测试用例中GEMM方法总是比直接方法快,所以我们只绘制GEMM方法的结果。
一些结果,如Arm Compute Library上的resnet18,在图2中缺失。这是因为Arm Compute Library的图形运行时当前不支持跳过连接,并且深度卷积的霓虹灯实现很差。这也反映了NNVM软件堆栈的优势。
半精度性能
深度神经网络的精度不是很重要,特别是对于移动设备的推断。使用低精度算法可以使推理更快。我们还测试了Mali GPU上的半精度浮点数。 | 模型 | 后端 | 每张图像的时间成本(秒) | 加速到FP32 | | —- | —- | —- | —- | | vgg16 | ACM-马里 | 0.9694 | 1.69 | | vgg16 | TVM-马里 | 0.6896 | 1.87x | | MobileNet 1.0 | TVM-马里 | 0.0479 | 1.60x | | ResNet18 | TVM-马里 | 0.1183 | 1.73x |
表1. ImageNet上FP16的推理速度
从理论上讲,FP16可以使峰值计算加倍,并使内存消耗减半,从而使速度加倍。但它需要良好的输入形状,以实现更长的矢量化和微调某些参数。

若有收获,就点个赞吧
0 人点赞
