在介绍卷积神经网络中的 1x1 卷积之前,首先回顾卷积网络的基本概念[1]。
卷积核(convolutional kernel):可以看作对某个局部的加权求和;它是对应局部感知,它的原理是在观察某个物体时我们既不能观察每个像素也不能一次观察整体,而是先从局部开始认识,这就对应了卷积。
卷积核的大小一般有 1x1,3x3 和 5x5 的尺寸(一般是奇数 x 奇数)。卷积核的个数就对应输出的通道数(channels),这里需要说明的是对于输入的每个通道,输出每个通道上的卷积核是不一样的。比如输入是 28x28x192(WxDxK,K 代表通道数),然后在 3x3 的卷积核,卷积通道数为 128,那么卷积的参数有 3x3x192x128,其中前两个对应的每个卷积里面的参数,后两个对应的卷积总的个数(一般理解为,卷积核的权值共享只在每个单独通道上有效,至于通道与通道间的对应的卷积核是独立不共享的,所以这里是 192x128)。池化(pooling):卷积特征往往对应某个局部的特征。要得到 global 的特征需要将全局的特征执行一个 aggregation(聚合)。
池化就是这样一个操作,对于每个卷积通道,将更大尺寸(甚至是 global)上的卷积特征进行 pooling 就可以得到更有全局性的特征。这里的 pooling 当然就对应了 cross region。与 1x1 的卷积相对应,而 1x1 卷积可以看作一个 cross channel 的 pooling 操作。pooling 的另外一个作用就是升维或者降维,后面我们可以看到 1x1 的卷积也有相似的作用。
下面从一般卷积过程介绍 1x1 的卷积,下面动图来表示卷积的过程:
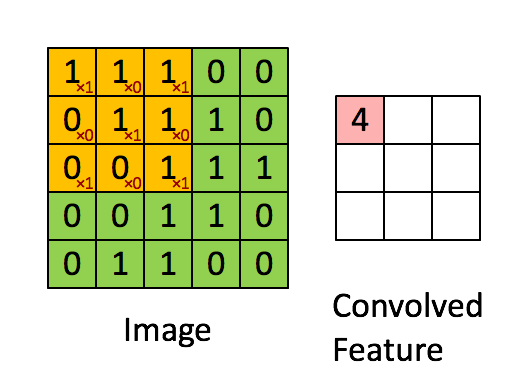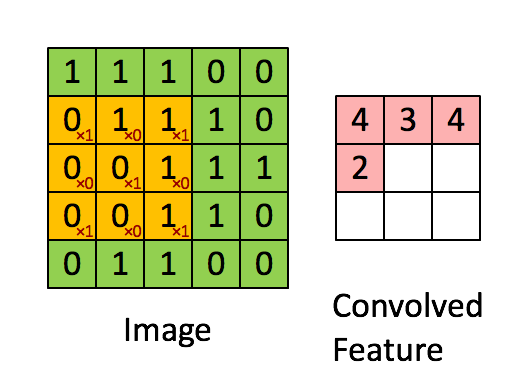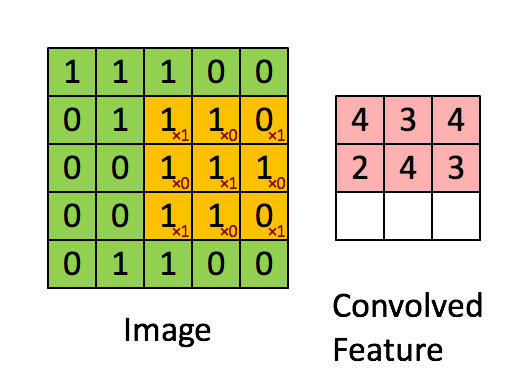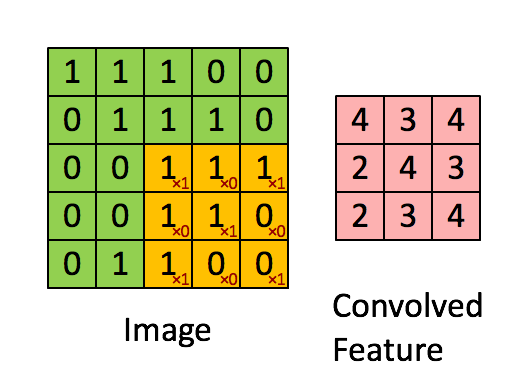
1x1 卷积,又称为网中网(Network in Network)[2]。
这里通过一个例子来直观地介绍 1x1 卷积。输入 6x6x1 的矩阵,这里的 1x1 卷积形式为 1x1x1,即为元素 2,输出也是 6x6x1 的矩阵。但输出矩阵中的每个元素值是输入矩阵中每个元素值 x2 的结果。
上述情况,并没有显示 1x1 卷积的特殊之处,那是因为上面输入的矩阵 channel 为 1,所以 1x1 卷积的 channel 也为 1。这时候只能起到升维的作用。这并不是 1x1 卷积的魅力所在。
让我们看一下真正 work 的示例。当输入为 6x6x32 时,1x1 卷积的形式是 1x1x32,当只有一个 1x1 卷积核的时候,此时输出为 6x6x1。此时便可以体会到 1x1 卷积的实质作用:降维。当 1x1 卷积核的个数小于输入 channels 数量时,即降维[3]。
注意,下图中第二行左起第二幅图像中的黄色立方体即为 1x1x32 卷积核,而第二行左起第一幅图像中的黄色立方体即是要与 1x1x32 卷积核进行叠加运算的区域。
其实 1x1 卷积,可以看成一种全连接(full connection)。
第一层有 6 个神经元,分别是 a1—a6,通过全连接之后变成 5 个,分别是 b1—b5,第一层的六个神经元要和后面五个实现全连接,本图中只画了 a1—a6 连接到 b1 的示意,可以看到,在全连接层 b1 其实是前面 6 个神经元的加权和,权对应的就是 w1—w6,到这里就很清晰了:
第一层的 6 个神经元其实就相当于输入特征里面那个通道数:6,而第二层的 5 个神经元相当于 1*1 卷积之后的新的特征通道数:5。
w1—w6 是一个卷积核的权系数,若要计算 b2—b5,显然还需要 4 个同样尺寸的卷积核[4]。
上述列举的全连接例子不是很严谨,因为图像的一层相比于神经元还是有区别的,图像是 2D 矩阵,而神经元就是一个数字,但是即便是一个 2D 矩阵(可以看成很多个神经元)的话也还是只需要一个参数(1*1 的核),这就是因为参数的权值共享。
注:1x1 卷积一般只改变输出通道数(channels),而不改变输出的宽度和高度
- 降维 / 升维
由于 1×1 并不会改变 height 和 width,改变通道的第一个最直观的结果,就是可以将原本的数据量进行增加或者减少。这里看其他文章或者博客中都称之为升维、降维。但我觉得维度并没有改变,改变的只是 height × width × channels 中的 channels 这一个维度的大小而已[5]。
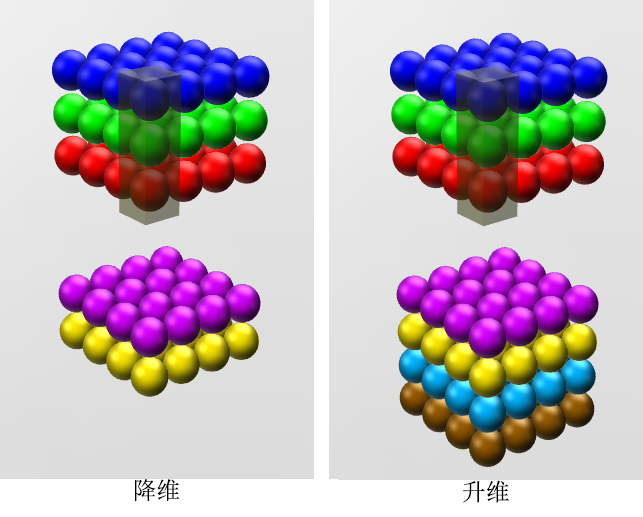
图像来自知乎 ID: YJango[6]
- 增加非线性
1*1 卷积核,可以在保持 feature map 尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很 deep。
备注:一个 filter 对应卷积后得到一个 feature map,不同的 filter(不同的 weight 和 bias),卷积以后得到不同的 feature map,提取不同的特征,得到对应的 specialized neuron[7]。
- 跨通道信息交互(channal 的变换)
例子:使用 1x1 卷积核,实现降维和升维的操作其实就是 channel 间信息的线性组合变化,3x3,64channels 的卷积核后面添加一个 1x1,28channels 的卷积核,就变成了 3x3,28channels 的卷积核,原来的 64 个 channels 就可以理解为跨通道线性组合变成了 28channels,这就是通道间的信息交互[7]。
注意:只是在 channel 维度上做线性组合,W 和 H 上是共享权值的 sliding window
Inception
- 这一点孙琳钧童鞋讲的很清楚。1×1 的卷积层(可能)引起人们的重视是在 NIN 的结构中,论文中林敏师兄的想法是利用 MLP 代替传统的线性卷积核,从而提高网络的表达能力。文中同时利用了跨通道 pooling 的角度解释,认为文中提出的 MLP 其实等价于在传统卷积核后面接 cccp 层,从而实现多个 feature map 的线性组合,实现跨通道的信息整合。而 cccp 层是等价于 1×1 卷积的,因此细看 NIN 的 caffe 实现,就是在每个传统卷积层后面接了两个 cccp 层(其实就是接了两个 1×1 的卷积层)。
- 进行降维和升维引起人们重视的(可能)是在 GoogLeNet 里。对于每一个 Inception 模块(如下图),原始模块是左图,右图中是加入了 1×1 卷积进行降维的。虽然左图的卷积核都比较小,但是当输入和输出的通道数很大时,乘起来也会使得卷积核参数变的很大,而右图加入 1×1 卷积后可以降低输入的通道数,卷积核参数、运算复杂度也就跟着降下来了。
以 GoogLeNet 的 3a 模块为例,输入的 feature map 是 28×28×192,3a 模块中 1×1 卷积通道为 64,3×3 卷积通道为 128,5×5 卷积通道为 32,如果是左图结构,那么卷积核参数为 1×1×192×64+3×3×192×128+5×5×192×32,而右图对 3×3 和 5×5 卷积层前分别加入了通道数为 96 和 16 的 1×1 卷积层,这样卷积核参数就变成了 1×1×192×64+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32),参数大约减少到原来的三分之一。
同时在并行 pooling 层后面加入 1×1 卷积层后也可以降低输出的 feature map 数量,左图 pooling 后 feature map 是不变的,再加卷积层得到的 feature map,会使输出的 feature map 扩大到 416,如果每个模块都这样,网络的输出会越来越大。
而右图在 pooling 后面加了通道为 32 的 1×1 卷积,使得输出的 feature map 数降到了 256。GoogLeNet 利用 1×1 的卷积降维后,得到了更为紧凑的网络结构,虽然总共有 22 层,但是参数数量却只是 8 层的 AlexNet 的十二分之一(当然也有很大一部分原因是去掉了全连接层)[8]。

ResNet
ResNet 同样也利用了 1×1 卷积,并且是在 3×3 卷积层的前后都使用了,不仅进行了降维,还进行了升维,使得卷积层的输入和输出的通道数都减小,参数数量进一步减少,如下图的结构[8]。

[1] 1*1 的卷积核与 Inception:https://blog.csdn.net/a1154761720/article/details/53411365
[2] 《Network in network》:https://arxiv.org/abs/1312.4400
[3]吴恩达 DeepLearning.ai 视频教程 《
Networks in Networks and 1x1 Convolutions》
[5]【CNN】卷积神经网络中的 1*1 卷积 的作用:https://blog.csdn.net/sscc_learning/article/details/79863922
[6] https://www.zhihu.com/question/56024942/answer/194997553
[7] 1×1 卷积核的作用?(附实例):https://zhuanlan.zhihu.com/p/35814486
[8] 1X1 卷积核到底有什么作用呢?:http://www.caffecn.cn/?/question/136
扩展知乎话题:卷积神经网络中用 1*1 卷积有什么作用或者好处呢?:https://www.zhihu.com/question/56024942
https://blog.csdn.net/amusi1994/article/details/81091145?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.channel_param

若有收获,就点个赞吧
0 人点赞
