初识TVM
(1) 什么是TVM
TVM是一款开源项目,主要由华盛顿大学的SAMPL组贡献开发。目前深度学习社区十分活跃,每天都有研究者提出新的operation(或者layer,具体称呼并不严谨)以期望更好的提升模型的准确率。同时,随着越来越多的厂商开始做硬件(比如寒武纪,商汤科技等等),我们跑神经网络的时候会有越来越多的后端设备可供选择。
而这对于做框架的人来说就比较头疼,既要尝试为新出现的各种operation提供支持,又要在新出现的后端设备上实现现有的operation。TVM项目因此应运而生,希望达到的目标就是研究人员只用写一次operation,然后TVM自动对各种后端设备生成性能可观的代码。
按照官方的定义,TVM是一套完整的stack,包括神经网络图优化(比如op fusion)和单个operation优化等部分。我习惯于将图优化的部分归类做Relay项目,而仅仅把单个operation优化看做TVM,因此文章之后提到的TVM基本是指单个算子优化这部分。
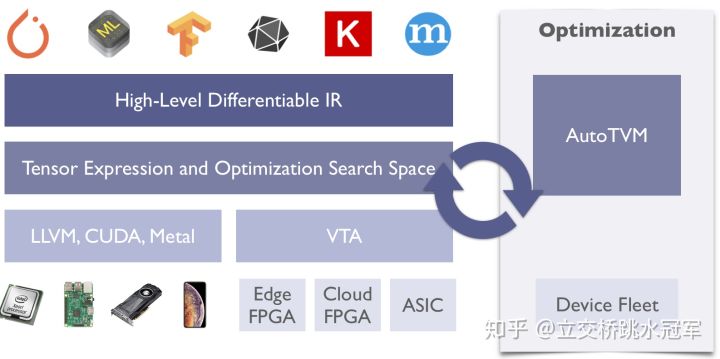 上面这张摘自tvm的官网(https://tvm.ai/about)的图片说明了TVM处于深度学习框架的位置。TVM位于神经网络图(High-Level Differentiable IR)的下方,底层硬件(LLVM, CUDA, Metal)的上方。
上面这张摘自tvm的官网(https://tvm.ai/about)的图片说明了TVM处于深度学习框架的位置。TVM位于神经网络图(High-Level Differentiable IR)的下方,底层硬件(LLVM, CUDA, Metal)的上方。
图片右边的AutoTVM我认为比较独立。这个目的是自动调整TVM生成的代码的一些参数,试图让TVM生成的代码尽可能快。做自动代码优化的优秀项目除了AutoTVM,还有Halide(https://halide-lang.org/papers/autoscheduler2019.html…),个人认为目前Halide做代码自动优化做的更好。TVM的基本思路参考自Halide,其中的数据结构也引用了很多Halide的实现,强烈推荐感兴趣的朋友研究一下Halide
(2) compute 与 schedule
Halide项目将所有operation的程序做了拆解,认为所有程序由两部分组成:compute和schedule。而将compute和schedule相分离也是一个里程碑式的重要想法,为自动代码生成提供了可能。
简单来说,我们看下面一段简单的C程序
for(int i = 0; i < 10; i ++) {for(int j = 0; j < 10; j++) {b[i][j] = a[i][j];}}
这段程序干了什么事情?就是把a数组的值赋值给数组b。这个高层的抽象的概念就是compute,这也是神经网络的研究者唯一关心的。他们只希望通过调用一个操作,完成这个赋值操作。
然而同样的赋值操作,可以有很多种实现,比如下面交换了行列顺序的程序
for(int i = 0; i < 10; i ++) {for(int j = 0; j < 10; j++) {b[j][i] = a[j][i];}}
上面两段代码的compute是一样的,即他们都干了一样的事情,但是显然性能是不一样的(考虑cache的命中率等等),这些涉及具体实现的因素就是schedule:嵌套循环之间的顺序就是schedule的一种,除此之外还有更复杂的schedule:比如在GPU上,哪些数组要放到share memory,某个block到底负责处理那些数据,某个循环是否要展开等等。在之后的文章中,会一起仔细探索这些schedule的实现
(3) example
下面我们通过TVM官方提供的一个简单的向量加法的例子(https://docs.tvm.ai/tutorials/tensor_expr_get_started.html…)来感受一下TVM的代码生成流程
最开始,用户需要根据TVM提供的接口,写出compute的定义
A = tvm.placeholder((10,), name='A')B = tvm.placeholder((10,), name='B')C = tvm.compute((10,), lambda i: A[i] + B[i], name="C")
其中A,B是placeholder类型,是一种特殊的tensor(目前tensor可以简单理解为任意维度的数组,和pytorch一样),代表输入。也就是说最后生成的代码会要求用户输入两个tensor(如果是生成C++代码的话,就是输入两个float*)。在代码中我们只是简单的声明了tensor的shape(在这里面是A、B都是一维,长度为n的tensor)
C是输出,它的shape和A、B相同。这里很重要的是这个lambda表达式(也可以是一个函数),也就是最重要的定义compute的部分。这个函数接受shape维度那么多的参数作为输入(如果shape是[4,5,6],那么就接受三个输入)。对于这个tensor来说,它某个点的值就是该函数以这几个值作为输入的返回值。比如C[3]的值就是A[3] + B[3],因为这里输入i的值是3
(如果还没有理解,可以看一个方阵翻转的例子)
A = tvm.placeholder((5, 5), name='input')B = tvm.compute((5, 5), lambda i,j: A[j][i], name='output')
继续我们向量加法的例子。在完成了compute的定义之后,接下来我们要完成schedule的部分。
s = tvm.create_schedule(C.op)
如果我们对这个schedule什么都不做,那么按照默认情况,会生成朴素的嵌套循环形式,如下所示(以下的代码摘自TVM的真实生成结果):
for (int32_t i = 0; i < 10; ++i) {C[i] = (A[i] + B[i]);}
而我们也可以选择做一些事情,比如最简单的loop split
bx, tx = s[C].split(C.op.axis[0], factor=2)
我们会将C的最外层循环,也就是第0个循环(因为在例子中C是一维的,因此也只有这一个循环)切成两个循环,且内层循环的长度是2。也就是说现在我们生成的代码会长这样(以下的代码摘自TVM的真实生成结果):
for (int32_t i_outer = 0; i_outer < 5; ++i_outer) {for (int32_t i_inner = 0; i_inner < 2; ++i_inner) {C[((i_outer * 2) + i_inner)] = (A[((i_outer * 2) + i_inner)] + B[((i_outer * 2) + i_inner)]);}}
这个split一点好处没有,只是用来做演示。不过在复杂的Operation中,通过将split和其他schedule变换共同使用,我们的确可以大幅提升生成的代码的速度。
在我们做完所有schedule变换之后,我们最终会将compute和schedule合起来,生成一个可以执行的代码,这就是build的用处。build函数接受的输入包括:schedule,输入输出列表,要生成代码对应的目标设备(对cpu,gpu自然需要生成不同的代码)
fadd = tvm.build(s, [A, B, C], ‘c', target_host=‘c’)
之后我们就会得到这样刚才看到的那个两层循环的代码。当然,除了那个循环之外还会一并生成一些其他代码,包括对输入数据做检查。这些代码比较繁琐,在此抛开不谈。
在一般情况下,我们都需要希望使用cpu之外的device来执行主要操作,从而提升速度。这就无形中将要生成的代码分成了两部分:host和device。就比如英伟达的GPU程序,我们既需要写cuda代码从而控制GPU的执行,同时我们也要写c代码,控制CPU对GPU的交互控制。
因此上面的例子更常见的完整形式如下:
A = tvm.placeholder((10,), name='A')B = tvm.placeholder((10,), name='B')C = tvm.compute((10,), lambda i: A[i] + B[i], name="C")s = tvm.create_schedule(C.op)bx, tx = s[C].split(C.op.axis[0], factor=2)s[C].bind(bx, tvm.thread_axis("blockIdx.x"))s[C].bind(tx, tvm.thread_axis("threadIdx.x"))
注意,最后两行也是一种schedule操作,他们将原本的循环分别绑定到了block和thread上做。这里隐含一个假设,就是循环的顺序并不重要(因为绑定到block/thread上,意思就是原来循环的一次迭代会由一个block/thread负责,而block/thread的执行顺序是无法控制的)。这个假设在深度学习领域往往是成立的(除非是RNN,不过这些情况我们暂不考虑)。
之后我们设置target_host和target来设置生成代码的执行环境
fadd = tvm.build(s, [A, B, C], target_host='c',target='cuda', name='sample_fadd')
上面的内容会生成如下两部分代码:
device部分:
extern "C" __global__ void sample_fadd_kernel0( float* __restrict__ C, float* __restrict__ A, float* __restrict__ B) {C[((((int)blockIdx.x) * 2) + ((int)threadIdx.x))] = (A[((((int)blockIdx.x) * 2) + ((int)threadIdx.x))] + B[((((int)blockIdx.x) * 2) + ((int)threadIdx.x))]);}
host部分(节选):
TVMValue ret_val1;int ret_type_code1;if (TVMFuncCall(sample_fadd_kernel0_packed, (TVMValue*) stack_value, (int*) stack_tcode, 5, &ret_val1, &ret_type_code1) != 0) {return -1;}
(4) schedule的种类
正如之前所说,compute决定了一段程序的输入输出的关系,而schedule决定了计算的顺序等因素。schedule虽然多种多样,也可以自由组合,但是无论如何也不会改变计算的结果。
在TVM目前(2019.10.23)提供的schedule中,主要常用的可以归纳为如下两种:
在TVM中,一个普通的算子一般是如下两种形式。一种是完美嵌套循环,即循环之间没有其他代码
for(int i = 0; i < 10; i++) {for(int j = 0; j < 10; j++) {a[i][j] = b[i][j];}}
一种是非完美嵌套循环,但是也仅仅有一处中断:
for(int i = 0; i < 10; i++) {int k = 0;for(int j = 0; j < 10; j++) {k += b[i][j];}a[i] = k;}
因此在代码中,循环是重要的影响性能的因素。TVM提供了循环展开(unroll),循环交换顺序(reorder)我们常见的循环优化,以及bind(上文提到过)等schedule原语。除此之外,为了更好的发挥他们的威力,也提供了循环切割(split),循环合并(fuse),循环切块(tiling)等原语
熟悉GPU的同学一定明白用好share,local memory对提升程序性能的重要性。比如上面的例子,如果换成这种写法,性能有可能会大打折扣(虽然因为cache命中的问题,实际上往往没有多大的性能差异。但是作为上层程序员,我们要尽可能把代码写好,不能过分指望编译器和底层系统的优化)
for(int i = 0; i < 10; i++) {a[i] = 0;for(int j = 0; j < 10; j++) {a[i] += b[i][j];}}
TVM也提供了帮助我们利用memory hierarchy的原语:cache read与cache write。这两个原语比较复杂,今天我们不详细展开
虽然程序员主要关注的优化应该在循环和访存上,但是TVM也提供了其他的schedule,在一些情况下,合理运用这些schedule也可以帮我们显著提升生成的代码速度。
这些schedule包括但不限于:double buffer(通过将空间扩大一倍,从而实现访存和计算的重叠),vectorize(向量化指令,通过这个schedule,我们可以在生成的代码中加入向量化,比如使用float4类型),compute inline(效果如下所示)等等。
A = tvm.placeholder((10,), name='A')B = tvm.compute((10,), lambda i: A[i] + 1, name='B')C = tvm.compute((10,), lambda i: B[i] + 1, name="C")s = tvm.create_schedule(C.op)fadd = tvm.build(s, [A, B, C], target_host='c',target='c')print(fadd.get_source())'''output:for (int32_t i = 0; i < 10; ++i) {B[i] = (A[i] + 1.000000e+00f);}for (int32_t i1 = 0; i1 < 10; ++i1) {C[i1] = (B[i1] + 1.000000e+00f);}'''s[B].compute_inline()fadd = tvm.build(s, [A, B, C], target_host='c',target='c')print(fadd.get_source())'''output:for (int32_t i = 0; i < 10; ++i) {C[i] = ((A[i] + 1.000000e+00f) + 1.000000e+00f);}'''
在之后的篇章中,我们会依次介绍这些schedule

若有收获,就点个赞吧
0 人点赞
