CopyOnWriteArrayList
1. 读写分离
写操作在一个复制的数组上进行,读操作还是在原数组中进行,读写分离,互不影响。
写操作需要加锁,防止并发写入时导致写入数据丢失。
写操作结束之后需要把原数组指向新的复制数组。
//写操作://通过过创建底层数组的新副本来实现的。//当 List 需要被修改的时候,并不修改原有内容,而是对原有数据进行一次复制,将修改的内容写入副本。//写完之后,把原数组指向新的复制数组。//这样可以保证写操作实在一个复制的数组上进行,而读操作还是在原数组中进行,不会影响读操作。public boolean add(E e) {//加锁final ReentrantLock lock = this.lock;lock.lock();try {Object[] elements = getArray();int len = elements.length;// newElements 是一个复制的数组Object[] newElements = Arrays.copyOf(elements, len + 1);newElements[len] = e;// 写操作在一个复制的数组上进行setArray(newElements);return true;} finally {lock.unlock();}}final void setArray(Object[] a) {array = a;}
//读操作//读操作没有任何同步控制和锁操作,//因为内部数组 array 不会被修改。private transient volatile Object[] array;public E get(int index) {return get(getArray(), index);}@SuppressWarnings("unchecked")private E get(Object[] a, int index) {return (E) a[index];}final Object[] getArray() {return array;}
2. 适用场景
CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读操作的性能,很适合读多写少的应用场景。
CopyOnWriteArrayList 有其缺陷:
- 内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右;
- 数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。
所以 CopyOnWriteArrayList 不适合内存敏感以及对实时性要求很高的场景。
ConcurrentHashMap
1. 存储结构
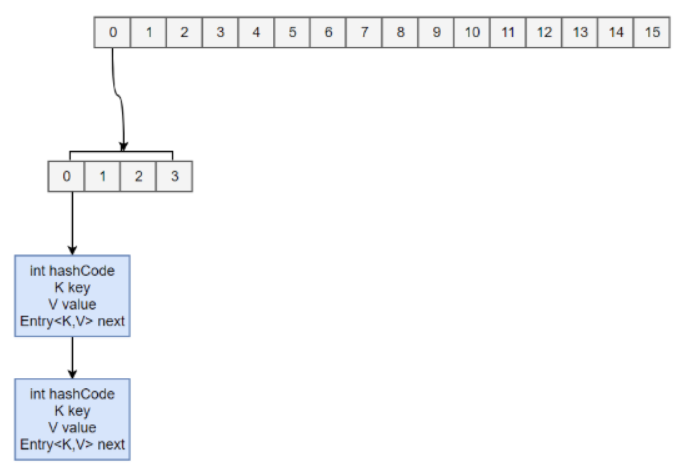
static final class HashEntry<K,V> {final int hash;final K key;volatile V value;volatile HashEntry<K,V> next;}
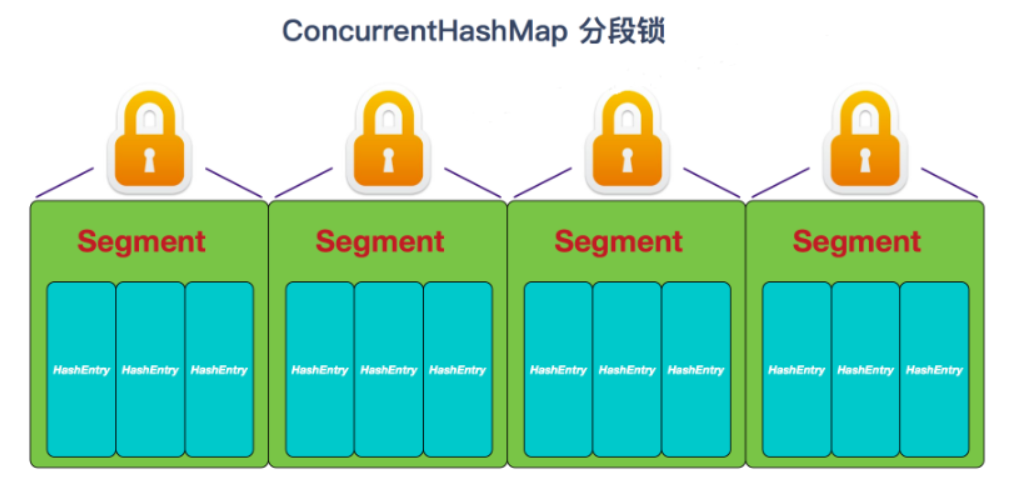
ConcurrentHashMap 采用了分段锁(Segment),每个分段锁维护着几个桶(HashEntry),多个线程可以同时访问不同分段锁上的桶, 从而使其并发度更高(并发度就是 Segment 的个数)。
//Segment 继承自 ReentrantLock。static final class Segment<K,V> extends ReentrantLock implements Serializable {private static final long serialVersionUID = 2249069246763182397L;static final int MAX_SCAN_RETRIES =Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;transient volatile HashEntry<K,V>[] table;transient int count;transient int modCount;transient int threshold;final float loadFactor;}
final Segment<K,V>[] segments;//默认的并发级别为 16,也就是说默认创建 16 个 Segment。static final int DEFAULT_CONCURRENCY_LEVEL = 16;
2. size 操作
每个 Segment 维护了一个 count 变量来统计该 Segment 中的键值对个数。
/*** The number of elements. Accessed only either within locks* or among other volatile reads that maintain visibility.*/transient int count;Copy to clipboardErrorCopied
在执行 size 操作时,需要遍历所有 Segment 然后把 count 累计起来。
ConcurrentHashMap 在执行 size 操作时先尝试不加锁,如果连续两次不加锁操作得到的结果一致,那么可以认为这个结果是正确的。
尝试次数使用 RETRIES_BEFORE_LOCK 定义,该值为 2,retries 初始值为 -1,因此尝试次数为 3。
如果尝试的次数超过 3 次,就需要对每个 Segment 加锁。
/*** Number of unsynchronized retries in size and containsValue* methods before resorting to locking. This is used to avoid* unbounded retries if tables undergo continuous modification* which would make it impossible to obtain an accurate result.*/static final int RETRIES_BEFORE_LOCK = 2;public int size() {// Try a few times to get accurate count. On failure due to// continuous async changes in table, resort to locking.final Segment<K,V>[] segments = this.segments;int size;boolean overflow; // true if size overflows 32 bitslong sum; // sum of modCountslong last = 0L; // previous sumint retries = -1; // first iteration isn't retrytry {for (;;) {// 超过尝试次数,则对每个 Segment 加锁if (retries++ == RETRIES_BEFORE_LOCK) {for (int j = 0; j < segments.length; ++j)ensureSegment(j).lock(); // force creation}sum = 0L;size = 0;overflow = false;for (int j = 0; j < segments.length; ++j) {Segment<K,V> seg = segmentAt(segments, j);if (seg != null) {sum += seg.modCount;int c = seg.count;if (c < 0 || (size += c) < 0)overflow = true;}}// 连续两次得到的结果一致,则认为这个结果是正确的if (sum == last)break;last = sum;}} finally {if (retries > RETRIES_BEFORE_LOCK) {for (int j = 0; j < segments.length; ++j)segmentAt(segments, j).unlock();}}return overflow ? Integer.MAX_VALUE : size;}Copy to clipboardErrorCopied
3. JDK 1.8 的改动
ConcurrentHashMap 取消了 Segment 分段锁。
JDK 1.8 使用 CAS 操作来支持更高的并发度,在 CAS 操作失败时使用内置锁 synchronized。
数据结构与HashMap 1.8 的结构类似,数组+链表 / 红黑二叉树(链表长度 > 8 时,转换为红黑树 )。synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 Hash 值不冲突,就不会产生并发。
4. JDK 1.8 中的 put 方法
(1)hash 算法
static final int spread(int h) {return (h ^ (h >>> 16)) & HASH_BITS;}
(2)定位索引位置
i = (n - 1) & hash
(3)获取 table 中对应索引的元素 f
f = tabAt(tab, i = (n - 1) & hash
// Unsafe.getObjectVolatile 获取 f// 因为可以直接指定内存中的数据,保证了每次拿到的数据都是新的static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);}
(4)如果 f 是 null,说明 table 中是第一次插入数据,利用
- 如果 CAS 成功,说明 Node 节点插入成功
- 如果 CAS 失败,说明有其他线程提前插入了节点,自旋重新尝试在该位置插入 Node
(5)其余情况把新的 Node 节点按链表或红黑树的方式插入到合适位置,这个过程采用内置锁实现并发。
5. 和 Hashtable 的区别
底层数据结构:
- JDK1.7 的ConcurrentHashMap底层采用分段的数组+链表实现, JDK1.8 的ConcurrentHashMap底层采用的数据结构与JDK1.8 的HashMap的结构一样,数组+链表/红黑二叉树。
- Hashtable和JDK1.8 之前的HashMap的底层数据结构类似都是采用数组+链表的形式, 数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的。
实现线程安全的方式
- JDK1.7的ConcurrentHashMap(分段锁)对整个桶数组进行了分割分段(Segment), 每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问度。 JDK 1.8 采用数组+链表/红黑二叉树的数据结构来实现,并发控制使用synchronized和CAS来操作。
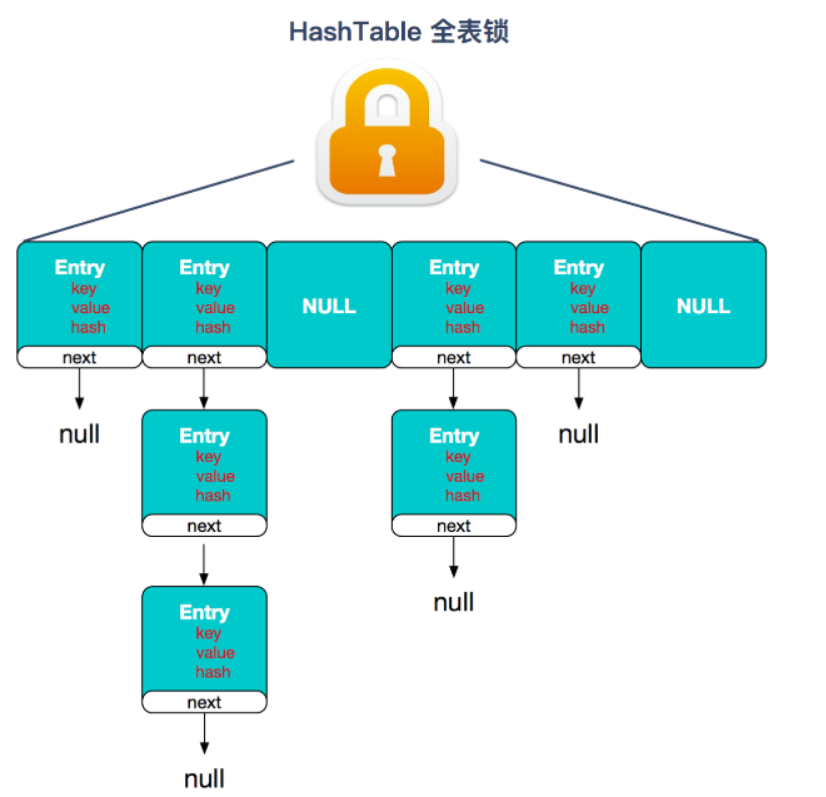
- Hashtable:使用 synchronized 来保证线程安全,效率非常低下。 当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态, 如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈。
Hashtable 全表锁
ConcurrentHashMap 分段锁
补充
红黑树性质
- 每个节点或者是红色的,或者是黑色的
- 根节点是黑色的
每一个叶子节点(最后的空节点)是黑色的
这其实是一个定义
如果一个节点是红色的,那么它们的孩子节点都是黑色的
因为红节点和其父亲节点表示一个3节点,黑色节点的右孩子一定是黑色节点。
从任意一个节点到叶子节点经过的黑色节点都是一样的
因为2-3树是绝对平衡的
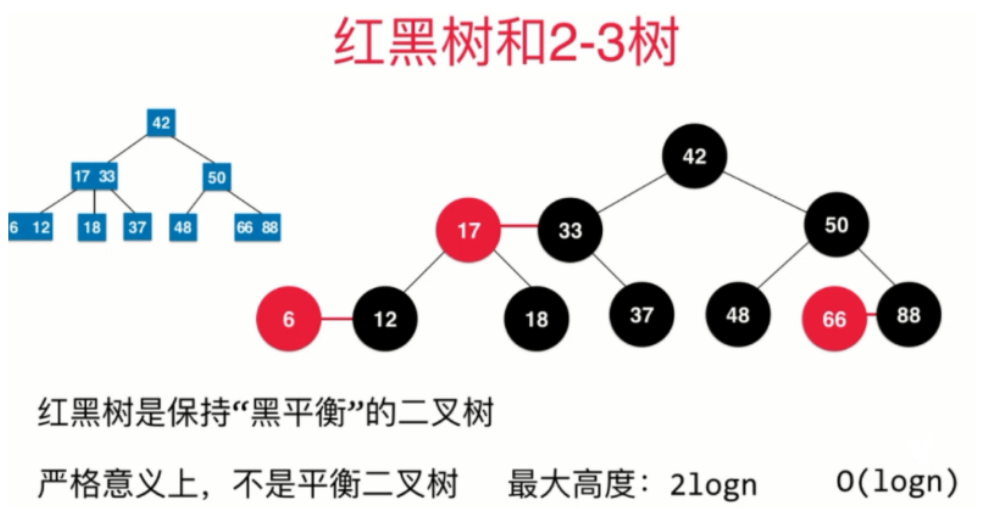
相较于 AVL 树,红黑树上的查找的操作的效率的低于 AVL 树的。但对于增删操作,红黑树的性能是更优的。

若有收获,就点个赞吧
0 人点赞
