Kafka 特点:
- 高可用
- 持久性
- 数据不易丢失
- 高吞吐量
Kafka 高可用
基于副本机制实现 Kafka 的高可用。
Kafka 持久性
Kafka 集群接收到 Producer 发过来的消息后,将其持久化到磁盘。此外,还支持数据备份。
Kafka 数据不易丢失
通过合理的配置,Kafka 消息不易丢失。
Kafka 高吞吐量
Kafka 高吞吐量的原因:
- 分区
- 网路传输
- 顺序读写
- 零拷贝
分区
当生产者向对应 Topic 传递消息,消息通过负载均衡机制传递到不同的 Partition 以减轻单个服务器实例的压力;
一个 Consumer Group 中可以有多个 Consumer,多个 Consumer 可以同时消费不同 Partition 的消息,大大的提高了消费者的并行消费能力。
网络传输
- 批量发送:在发送消息的时候,Kafka 不会直接将少量数据发送出去,否则每次发送少量的数据会增加网络传输频率,降低网络传输效率。Kafka 会先将消息缓存在内存中,当超过一个的大小或者超过一定的时间,那么会将这些消息进行批量发送。
- 端到端压缩: Kfaka会将这些批量的数据进行压缩,将一批消息打包后进行压缩,发送给 Broker 服务器后,最终这些数据还是提供给消费者用,所以数据在服务器上还是保持压缩状态,不会进行解压,而且频繁的压缩和解压也会降低性能,最终还是以压缩的方式传递到消费者的手上,在 Consumer 端进行解压。
顺序读写
Kafka 是个可持久化的日志服务,它将数据以数据日志的形式进行追加,最后持久化在磁盘中。
Kafka 消息存储时依赖于文件系统。为了利用数据的局部相关性:操作系统从磁盘中以数据块为单位读取数据,将一个数据块读入内存中,如果有相邻的数据,就不用再去磁盘中读取。所以,在某些情况下,顺序磁盘访问能比随机内存访问还要快。同时在写数据的时候也是将一整块数据块写入磁盘中,大大提升 I / O 效率。
零拷贝
普通的数据拷贝:

零拷贝主要的任务是避免 CPU 做大量的数据拷贝任务,减少不必要的拷贝。
内存映射文件(Memory Mapped Files,mmap)在 64 位操作系统中一般可以表示 20G 的数据文件,它的工作原理是直接利用操作系统的页缓存来实现文件到物理内存的直接映射。
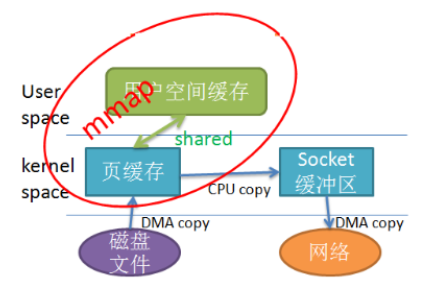
使用 mmap 替代 read 很明显减少了 1 次拷贝,当拷贝数据量很大时,无疑提升了效率。
参考资料

若有收获,就点个赞吧
0 人点赞
