HashMap
- HashMap类使用散列表实现Map接口并扩展AbstractMap。HashMap采用哈希算法实现, 底层采用了哈希表存储数据。
- HashMap 根据键的 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。
- HashMap 最多只允许一条记录的键为 null,允许多条记录的值为 null。
- HashMap 非线程安全,即任一时刻可以有多个线程同时写 HashMap,可能会导致数据的不一致。
- 如果需要满足线程安全,可以用 Collections 的 synchronizedMap 方法使HashMap 具有线程安全的能力,或者使用 ConcurrentHashMap
1.8前
- 构造方法执行的时候会创建一个长度为16的数组Entry[] table,用来存储键值对的数据
1.8后
- 构造方法执行的时候会创建一个空的数据,在Put方法执行后通过扩容来判断是否扩容数组Node[] table名字没变 ```java HashMap的构造方法:
HashMap() //构造一个默认的散列映射 HashMap(Map<? extends K, ? extends V> m) //用m的元素初始化散列映射 HashMap(int initialCapacity) //初始化散列映射容量 HashMap(int initialCapacity, float loadFactor) //初始化散列映射的容量和填充比
填充比:它决定在散列映射向上调整大小之前,有多少能被充满。 具体说,就是当 元素个数 > 散列映射容量*填充比 时,散列映射被扩大。 没有获得填充比,默认使用0.75。
注:散列映射并不保证它的元素的顺序。因此,元素加入散列映射的顺序不一定是它们被迭代方法读出的顺序**HashMap与HashTable的区别**<br /> 1. HashMap: 线程不安全,效率高。允许key或value为null。<br /> 2. HashTable: 线程安全,效率低。不允许key或value为null。<a name="gOYUr"></a>## 基本方法<a name="yf85T"></a>### 1.存储数据过程put(key,value)首先会将传入的 Key 做 `hash` 运算计算出 hashcode,然后根据数组长度取模计算出在数组中的 index 下标。由于在计算中位运算比取模运算效率高的多,所以 HashMap 规定数组的长度为 `2^n` 。这样用 `2^n - 1` 做位运算与取模效果一致,并且效率还要高出许多。由于数组的长度有限,所以难免会出现不同的 Key 通过运算得到的 index 相同,这种情况可以利用**链表**来解决,HashMap 会在 `table[index]`处形成链表,1.7 采用**头插法**将数据插入到链表中(**1.8是尾插法**)。```javapublic V put(K key, V value) {return putVal(hash(key), key, value, false, true);}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {//tab=初始map数组;n=初始map数组得长度//p=hash计算后map数组;i=hash计算后map数组下标位置Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)//初始化扩容n = (tab = resize()).length;//计算下标 将数据 赋值给 p (hash计算后map数组)//1、当前下标无数据if ((p = tab[i = (n - 1) & hash]) == null)//新建Node数组 赋值 给 tab数组tab[i] = newNode(hash, key, value, null);else {//当前hash在Node中的位置Node<K,V> e; K k;// hash 相等 && key 相等if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))//当前hash在Node中的位置e = p;//如果 p得类型是树节点else if (p instanceof TreeNode)//添加到树节点中e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {//1、 当前下标有数据//如果 不是树节点 并且当前key 不重复 遍历插入for (int binCount = 0; ; ++binCount) {//下一个引用node 是空的if ((e = p.next) == null) {//遍历插入到 p Node节点中p.next = newNode(hash, key, value, null);//如果长度>= (8-1)if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st//转红黑树treeifyBin(tab, hash);break;}//下一个引用不是空的;hash 和 key 相同 跳出当前循环if (e.hash == hash &&((k = e.key) == key ||(key != null && key.equals(k))))break;//下一个引用不是空的; ash 和 key 不相同p = e;}}//如果 链表下一个 不是空的 但是 key 存在时,将现有得 节点加入到最后//e不为空表示存在相同的key,替换value并返回旧值if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;//链表元素增加,并判断是否大于阈值,如果大于,则扩容if (++size > threshold)resize();afterNodeInsertion(evict);return null;}// Create a regular (non-tree) nodeNode<K,V> newNode(int hash, K key, V value, Node<K,V> next) {return new Node<>(hash, key, value, next);}final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,int h, K k, V v) {Class<?> kc = null;boolean searched = false;TreeNode<K,V> root = (parent != null) ? root() : this;for (TreeNode<K,V> p = root;;) {int dir, ph; K pk;if ((ph = p.hash) > h)dir = -1;else if (ph < h)dir = 1;else if ((pk = p.key) == k || (k != null && k.equals(pk)))return p;else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0) {if (!searched) {TreeNode<K,V> q, ch;searched = true;if (((ch = p.left) != null &&(q = ch.find(h, k, kc)) != null) ||((ch = p.right) != null &&(q = ch.find(h, k, kc)) != null))return q;}dir = tieBreakOrder(k, pk);}TreeNode<K,V> xp = p;if ((p = (dir <= 0) ? p.left : p.right) == null) {Node<K,V> xpn = xp.next;TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);if (dir <= 0)xp.left = x;elsexp.right = x;xp.next = x;x.parent = x.prev = xp;if (xpn != null)((TreeNode<K,V>)xpn).prev = x;moveRootToFront(tab, balanceInsertion(root, x));return null;}}}
2.遍历方法
Iterator<Map.Entry<String, Integer>> entryIterator = map.entrySet().iterator();while (entryIterator.hasNext()) {Map.Entry<String, Integer> next = entryIterator.next();System.out.println("key=" + next.getKey() + " value=" + next.getValue());}
Iterator<String> iterator = map.keySet().iterator();while (iterator.hasNext()){String key = iterator.next();System.out.println("key=" + key + " value=" + map.get(key));}
map.forEach((key,value)->{System.out.println("key=" + key + " value=" + value);});
强烈建议使用第一种 EntrySet 进行遍历。
第一种可以把 key value 同时取出,第二种还得需要通过 key 取一次 value,效率较低, 第三种需要 JDK1.8 以上,通过外层遍历 table,内层遍历链表或红黑树。
HashMap底层实现
HashMap底层实现采用了 数组+单向链表+红黑树
数据结构中由数组和链表来实现对数据的存储,他们各有特点。
(1) 数组:占用空间连续。 寻址容易,查询速度快。但是,增加和删除效率非常低。
(2) 链表:占用空间不连续。 寻址困难,查询速度慢。但是,增加和删除效率非常高。
结合数组和链表的优点(即查询快,增删效率也高)=“哈希表”。 哈希表的本质就是“数组+链表”。
1. 存储结构
内部包含了一个 Entry 类型的数组 table。
// HashMap的核心数组结构,也称之为“位桶数组”transient Entry[] table;
一个Entry对象存储了:
1. key:键对象
2.value:值对象
3. next:下一个节点
4. hash: 键对象的hash值
其中有两个重要的参数:
- 容量(capacity),始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍
- 负载因子(loadFactor)
容量的默认大小是 16,负载因子是 0.75,当 HashMap 的 size > 16*0.75 时就会发生扩容(容量和负载因子都可以自由调整)。
显然每一个Entry对象就是一个单向链表结构。
数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值相同的 Entry。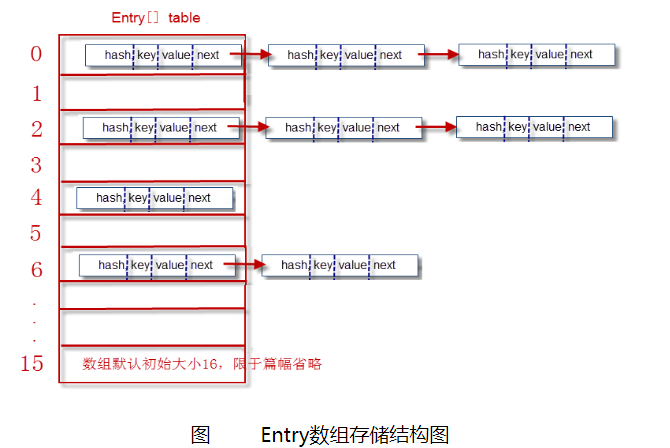
static class Node<K,V> implements Map.Entry<K,V> {//包含了四个字段final int hash;final K key;V value;//next指向下一个节点,说明是链表结构Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}public final boolean equals(Object o) {if (o == this)return true;if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>)o;if (Objects.equals(key, e.getKey()) &&Objects.equals(value, e.getValue()))return true;}return false;}}
2. 拉链法的工作原理
HashMap<String, String> map = new HashMap<>();map.put("K1", "V1");map.put("K2", "V2");map.put("K3", "V3");
- 新建一个 HashMap,默认大小为 16;
- 插入
- 插入
- 插入
应该注意到是 1.7 采用头插法将数据插入到链表中(1.8是尾插法)方式进行链表的插入
查找需要分成两步进行:
- 计算键值对所在的桶
- 在链表上顺序查找,时间复杂度显然和链表的长度成正比
3.hash
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}
4.扩容
除了初始化的时候会指定 HashMap 的容量,在进行扩容的时候,其容量也可能会改变。HashMap 有扩容机制,就是当达到扩容条件时会进行扩容。HashMap 的扩容条件就是当 HashMap 中的元素个数(size)超过临界值(threshold)时就会自动扩容。
在 HashMap 中,threshold = loadFactor * capacity。loadFactor 是装载因子,表示 HashMap 满的程度,默认值为 0.75f,设置成 0.75 有一个好处,那就是 0.75 正好是 3/4,而 capacity 又是 2 的幂。所以,两个数的乘积都是整数。
对于一个默认的 HashMap 来说,默认情况下,当其 size 大于 12(16*0.75) 时就会触发扩容。下面是 HashMap 中的扩容方法(resize)中的一段:
if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}
从上面代码可以看出,扩容后的 table 大小变为原来的两倍,这一步执行之后,就会进行扩容后 table 的调整,这部分非本文重点,省略。
可见,当HashMap中的元素个数(size)超过临界值(threshold)时就会自动扩容,扩容成原容量的2倍,即从16扩容到32、64、128 …
所以,通过保证初始化容量均为 2 的幂,并且扩容时也是扩容到之前容量的2倍,所以,保证了 HashMap 的容量永远都是2的幂。
5.链表转换红黑树
根据泊松分布,在负载因子默认为 0.75 的时候,单个 hash 槽内元素个数为 8 的概率小于百万分之一,所以将7作为一个分水岭,等于 7 的时候不转换,大于等于 8 的时候才进行转换,小于等于 6 的时候就化为链表。
与 HashTable 的比较
- HashMap 是非线程安全的,HashTable 使用 synchronized 来进行同步,是线程安全的。
- HashMap 要比 HashTable 效率高一点。Hashtable 基本被淘汰,不要在代码中使用它。
- HashMap 可以插入键为 null 的 Entry;HashTable 中插入的键只要有一个为 null,直接抛出 NullPointerException。
- HashMap 的迭代器是 fail-fast 迭代器。
- HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的。
- HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间;Hashtable 没有这样的机制。
- HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍;Hashtable 容量默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。在初始化时如果给定了容量初始值,HashMap 会将其扩充为2的幂次方大小;Hashtable 会直接使用初始值。
与 HashSet 的比较
HashSet 底层就是基于HashMap实现的。(HashSet 的源码非常非常少,因为除了 clone() 方法、writeObject()方法、readObject()方法是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。)
| HashMap | HashSet |
|---|---|
| HashMap实现了Map接口 | HashSet实现了Set接口 |
| HashMap储存键值对 | HashSet存储对象 |
| 调用put()向map中添加元素 | 调用add()方法向Set中添加元素 |
| HashMap使用键(Key)计算Hashcode | HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false |
| HashMap相对于HashSet较快,因为它是使用唯一的键获取对象 | HashSet较HashMap来说比较慢 |

若有收获,就点个赞吧
0 人点赞
