学习词汇表示
建模语言的上下文
因为词汇的意思,会依赖上下文,因此学习词汇表示时,要建模词汇的上下文。

那么如何直接建模长程依赖呢?
那么如何直接建模一个长句子中词和词之间的长程依赖呢?
- 全连接
全连接存在一个问题,就是在于,连接上面的权重如w_ij,是可学习的参数,学好后就固定了,固定后的权重就带来两个问题: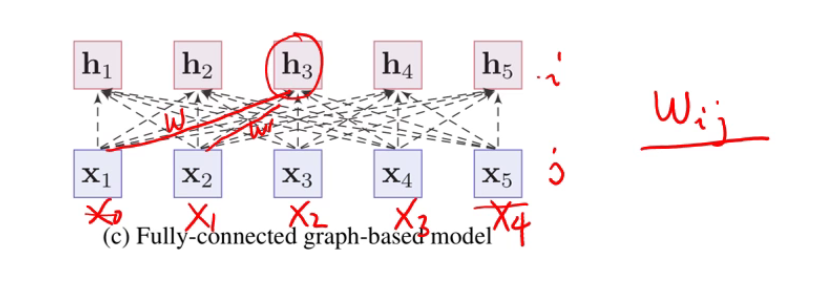
- 句子长度不能发生变化,不然就没法处理了。
- 语言的组合是很灵活的,比如可以在任意词之间插一个没有意义的虚拟词,这样会导致原来词之间的依赖关系会发生变换。
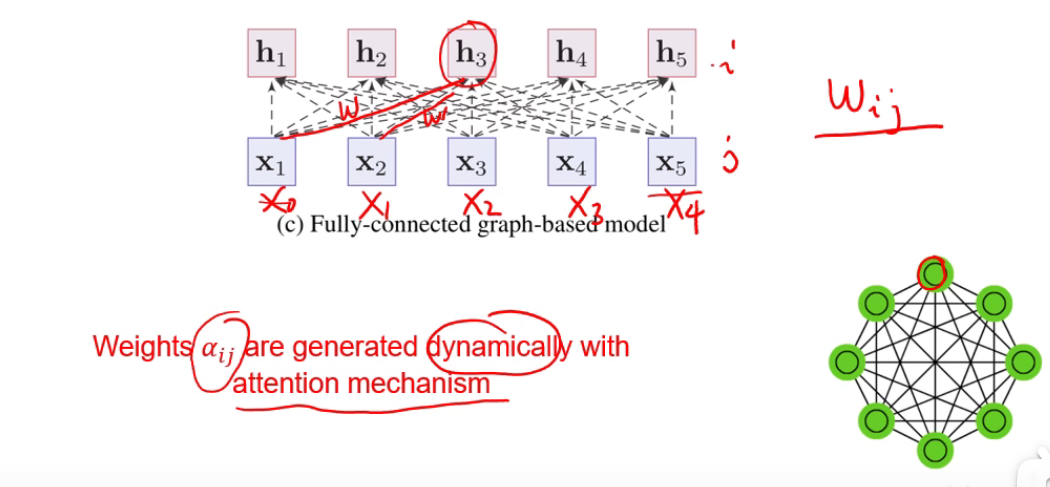
如何处理这个问题呢?
只需要让连接上的权重,不要是固定的可学习的参数,而是个动态生成的,比如用注意力机制。
注意力机制
- x_i是神经网络输入的信息,这些信息中有些是重要的,有些是不重要的。
- 如何判断是否重要呢?有一个查询向量q,或者叫任务相关向量,在这个任务上我们只关注部分信息。
- 现在的目的是从输入的候选信息中,只选取和我们的任务相关的信息,分两步做:
- 计算注意力分布,通过q和每个x计算一下相关程度,打个分,一般直接用相似度。打分可能很大或很小,要做个softmax归一化,这样所有alpha加起来是1,是个分布。
- 根据这个分布对所有信息进行加权。


将attention机制应用在语言建模上
建模词和词之间的依赖关系。
- 右图以“The”为例,希望其上下文表示由句子中所有的词组合而成,直接一起建模局部和非局部的依赖关系。
- 那么就将“The”作为查询向量q,其他词汇作为x。
- 每个词都用这样的方式建模,即得到了每个词的上下文表示。
因为这种注意力机制用法,并没有句子外部的查询向量q,因此叫做self-attention。
QKV Model
- 上述的自注意力机制实际使用起来稍显简单:
- 一个词即当query,又当候选信息来用。
- 本身不带参数,导致模型容量比较小。
- 为了提高自注意力模型的能力,实际使用中通常会用变体,即QKV模式。
- 计算的时候不用一个个算,直接用矩阵的方式。
- 矩阵中每一行就是每个词对其他所有词的attention,按行softmax就得到一个注意力矩阵。
由于softmax性质比较特殊,如果输入的一组数中有些数显著比其他数大的话,就会使得这个分布非常sharp,这样就不利于在神经网络学习中的梯度回传。 因此使用中,除以一个
 的缩放因子,然后再过softmax,使得整个分布比较平滑一些,这样学习起来效率更高。
的缩放因子,然后再过softmax,使得整个分布比较平滑一些,这样学习起来效率更高。
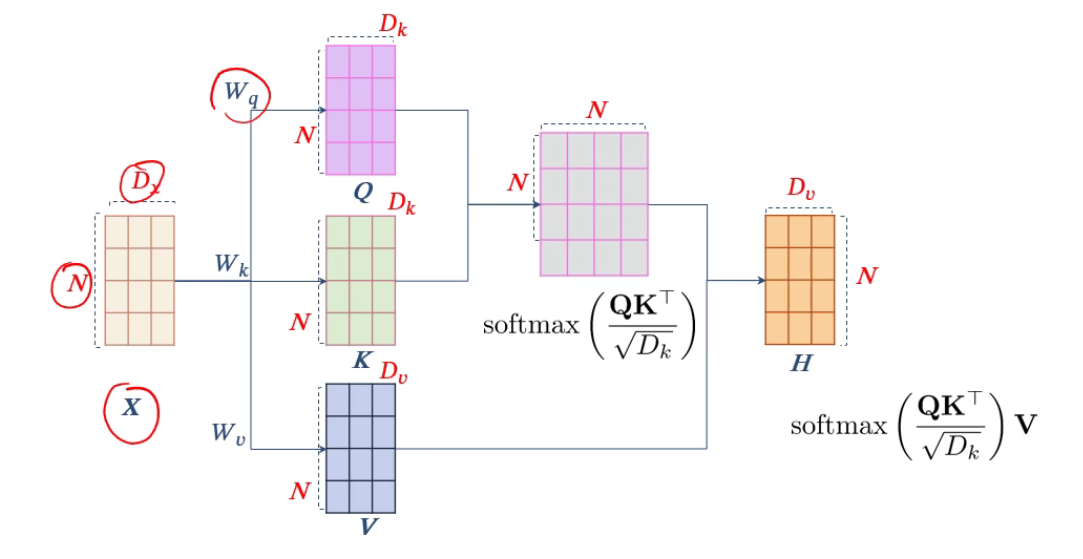
QKV模式中三个可学习矩阵:W_q,W_k,W_v。能力变得更强。
Multi-head Self attention
进一步可以同multi-head来增加自注意力模型的能力。
上述讲的相当于将原始的x通过QKV映射到一个空间,然后在这个空间中计算它们的依赖关系,事实上,我们可以做多种不同的映射,每种映射的QKV都不一样,不是共享的。
- 每次映射都是在特定空间中建模它们的语义交互关系,不同的映射就称为不同的head。
得到不同的组合后,将它们拼一下,然后通过另外的参数W映射为原来的维度。
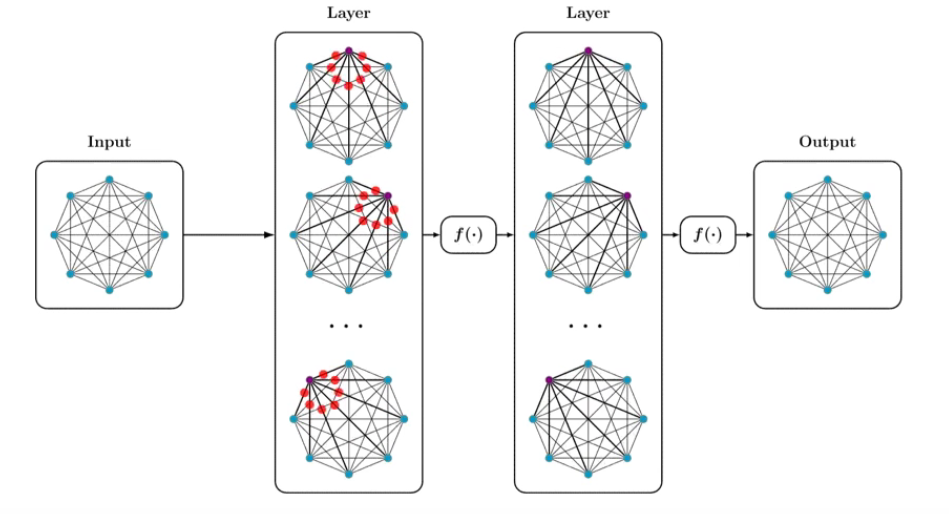
Multi-layer Self-Attention
在多头注意力的基础上,还可以把它再堆叠起来,形成多层的结构。
Transformer

在知道self-attention概念的基础上,就可以看一下transformer具体是什么样的结构,核心是自注意力,但仅此还不够。
Positional Embedding刚才讲的自注意力模块中,所有的连接上的权重,只和内容相关,而和位置无关。
- 而在语言建模中,位置虽然不是最主要的,但依然重要,特别是词和词间的相对位置。因此需要加入位置信息。
Layer Normalization
- 另外,为了训练深层的网络,需要用到层规范化。
- 通过规范化,使得神经网络训练更加稳定。
Skip Connection,也是为了训练深层网络用的。
Position-wise FFN 逐位的FFN,可以理解为窗口为1的卷积。

若有收获,就点个赞吧
0 人点赞
