参考:综述-图像处理中的注意力机制;计算机视觉中的注意力机制;深度学习中的注意力机制;计算机视觉中的注意力机制
人类的视觉注意力
深度学习中的注意力机制借鉴了人类的注意力思维方式。因此,我们首先简单介绍人类视觉的选择性注意力。
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是所说的注意力焦点,然后对这一区域投入更多的注意力资源,以获取更多所需要关注目标的细节信息,从而抑制其它无用信息。这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制。人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
图2形象的展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标。很明显对于图2所示的场景,人们会把注意力更多的投入到人的脸部,文本的标题以及文章首句等位置。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
注意力(attention)其实是一个非常常见,但是又会被忽略的事实。比如天空一只鸟飞过去的时候,往往你的注意力会追随着鸟儿,天空在你的视觉系统中,自然成为了一个背景(background)信息。
但是这样训练出的神经网络,对图片的全部特征其实是等价处理的。虽然神经网络学习到了图片的特征来进行分类,但是这些特征在神经网络“眼里”没有差异,神经网络并不会过多关注某个“区域”(区域不仅仅指图片的某个区域,还可能是通道(channel)信息)。但是人类注意力是会集中在这张图片的一个区域内,而其他的信息受关注度会相应降低。
- 计算机视觉(computer vision)中的注意力机制(attention)的基本思想就是想让系统学会注意力——能够忽略无关信息而关注重点信息。
在深度学习发展的今天,搭建能够具备注意力机制的神经网络则开始显得更加重要,一方面是这种神经网络能够自主学习注意力机制,另一方面则是注意力机制能够反过来帮助我们去理解神经网络看到的世界[3]。
近几年来,深度学习与视觉注意力机制结合的研究工作,大多数是集中于使用掩码(mask)来形成注意力机制。掩码的原理在于通过另一层新的权重,将图片数据中关键的特征标识出来,通过学习训练,让深度神经网络学到每一张新图片中需要关注的区域,也就形成了注意力。
这种思想,进而演化成两种不同类型的注意力,一种是软注意力(soft attention),另一种则是强注意力
注意力分类与基本概念
该文分为: 硬注意力、软注意力、此外,还有高斯注意力、空间变换
- 就注意力的可微性来分:
- Hard-attention,就是0/1问题,哪些区域是被 attentioned,哪些区域不关注.硬注意力在图像中的应用已经被人们熟知多年:图像裁剪(image cropping)
- Soft-attention,[0,1]间连续分布问题,每个区域被关注的程度高低,用0~1的score表示.
硬注意力(强注意力)与软注意力不同点在于,首先强注意力是更加关注点,也就是图像中的每个点都有可能延伸出注意力,同时强注意力是一个随机的预测过程,更强调动态变化。当然,最关键是强注意力是一个不可微的注意力,训练过程往往是通过增强学习(reinforcement learning)来完成的。
软注意力的关键点在于,这种注意力更关注区域或者通道,而且软注意力是确定性的注意力,学习完成后直接可以通过网络生成,最关键的地方是软注意力是可微的,这是一个非常重要的地方。可以微分的注意力就可以通过神经网络算出梯度并且前向传播和后向反馈来学习得到注意力的权重。
- 就注意力关注的域来分:
- 空间域(spatial domain)
- 通道域(channel domain)
- 层域(layer domain)
- 混合域(mixed domain)
- 时间域(time domain):还有另一种比较特殊的强注意力实现的注意力域,时间域(time domain),但是因为强注意力是使用reinforcement learning来实现的,训练起来有所不同。
- 对于3D数据如视频。
一个概念:Self-attention自注意力,就是 feature map 间的自主学习,分配权重(可以是 spatial,可以是 temporal,也可以是 channel间)
软注意力(soft attetion)
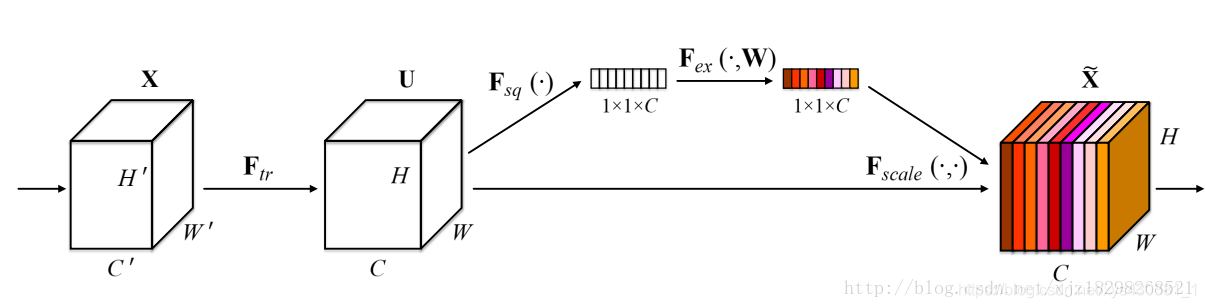
- SENET 2017CVPR《论文阅读笔记—SENET》(通道域)
- 中间的模块就是SENet的创新部分,也就是注意力机制模块。这个注意力机制分成三个部分:挤压(squeeze),激励(excitation),以及scale(attention)。
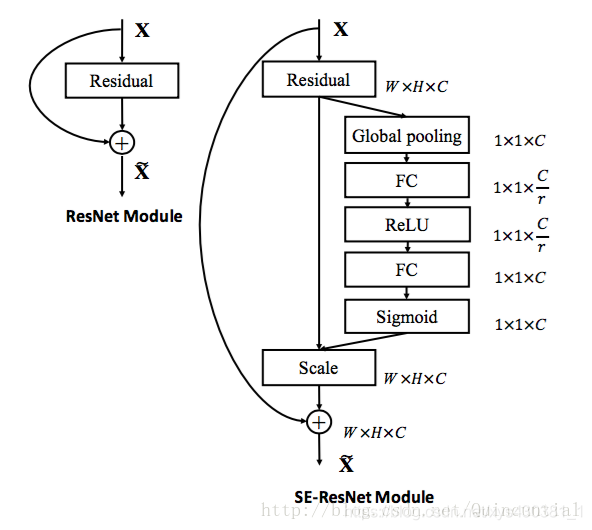
- SE block的灵活性意味着它可以直接应用于标准卷积之外的变换。为了说明这一点,我们通过将SE块集成到两个流行的网络架构系列Inception和ResNet中来开发SENets。如下图SE-ResNet Module
Squeeze就是一个全局平均池化,这一步的结果相当于表明该层C个feature map的数值分布情况,或者叫全局信息。Squeeze操作就是在得到U(多个feature map)之后采用全局平均池化操作对其每个feature map进行压缩,使其C个feature map最后变成1x1xC的实数数列 Excitation就是通过Excitation操作(如图2紫色框标注)来全面捕获通道依赖性(相互之间的重要性),论文提出需要满足两个标准: (1) 它必须是灵活的(特别是它必须能够学习通道之间的非线性交互); (2) 它必须学习一个非互斥的关系,因为独热激活相反,这里允许强调多个通道。 为了满足这些要求,论文选择采用一个简单的gating mechanism,使用了sigmoid激活函数。
- Non Local Neural Networks 2018CVPR
- FAIR的杰作,主要 inspired by 传统方法用non-local similarity来做图像 denoise。主要思想也很简单,CNN中的 convolution单元每次只关注邻域 kernel size 的区域,就算后期感受野越来越大,终究还是局部区域的运算,这样就忽略了全局其他片区(比如很远的像素)对当前区域的贡献。
- 所以 non-local blocks 要做的是,捕获这种 long-range 关系:对于2D图像,就是图像中任何像素对当前像素的关系权值;对于3D视频,就是所有帧中的所有像素,对当前帧的像素的关系权值。
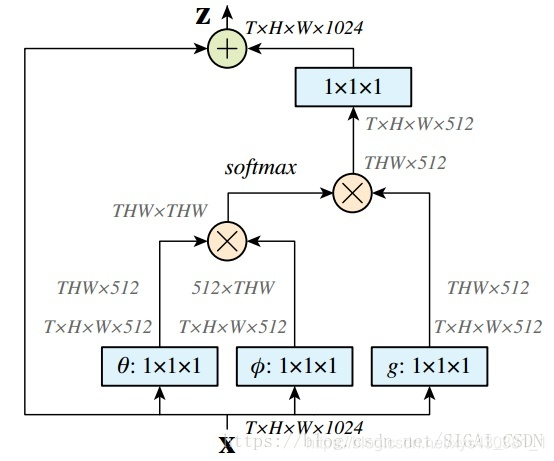
总结
Pros:non-local blocks很通用的,容易嵌入在任何现有的 2D 和 3D 卷积网络里,来改善或者可视化理解相关的CV任务。比如前不久已有文章把 non-local 用在 Video ReID [2] 的任务里。
Cons:文中的结果建议把non-local 尽量放在靠前的层里,但是实际上做 3D 任务,靠前的层由于 temporal T 相对较大,构造及点乘操作那步,超多的参数,需要耗费很大的GPU Memory
硬/强注意力(hard attention)
自注意力
- 自注意力机制是注意力机制的改进,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
- 在神经网络中,我们知道卷积层通过卷积核和原始特征的线性结合得到输出特征,由于卷积核通常是局部的,为了增加感受野,往往采取堆叠卷积层的方式,实际上这种处理方式并不高效。同时,计算机视觉的很多任务都是由于语义信息不足从而影响最终的性能。自注意力机制通过捕捉全局的信息来获得更大的感受野和上下文信息。
- 自注意力机制 (self-attention)[1] 在序列模型中取得了很大的进步;另外一方面,上下文信息(context information)对于很多视觉任务都很关键,如语义分割,目标检测。自注意力机制通过(key, query, value)的三元组提供了一种有效的捕捉全局上下文信息的建模方式。接下来首先介绍几篇相应的工作,然后分析相应的优缺点以及改进方向。
自注意力机制作为一个有效的对上下文进行建模的方式,在很多视觉任务上都取得了不错的效果。同时,这种建模方式的缺点也是显而易见的,一是没有考虑channel上信息,二是计算复杂度仍然很大。相应的改进策,一方面是如何进行spatial和channel上信息的有效结合,另外一方面是如何进行捕捉信息的稀疏化,关于稀疏的好处是可以更加鲁棒的同时保持着更小的计算量和显存。最后,图卷积作为最近几年很火热的研究方向,如何联系自注意力机制和图卷积,以及自注意力机制的更加深层的理解都是未来的很重要的方向。
TODO
Tell Me Where to Look: Guided Attention Inference Network (软注意力)
Fully Convolutional Attention Networks for Fine-Grained Recognition (硬注意力)
本文利用基于强化学习的视觉 attenation model 来模拟学习定位物体的part,并且在场景内进行物体分类。这个框架模拟人类视觉系统的识别过程,通过学习一个任务驱动的策略,经过一系列的 glimpse 来定位物体的part。那么,这里的 glimpse 是什么呢?每一个 glimpse 对应一个物体的part。将原始的图像以及之前glimpse 的位置作为输入,下一次 glimpse位置作为输出,作为下一次物体part。每一个 glimpse的位置作为一个 action,图像和之前glimpse的位置作为 state,奖励衡量分类的准确性。本文方法可以同时定位多个part,之前的方法只能一次定位一个part。
另一个角度
什么是attention机制(视觉中)
其实我没有找到attention的具体定义,但在计算机视觉的相关应用中大概可以分为两种:
1)学习权重分布:输入数据或特征图上的不同部分对应的专注度不同,对此Jason Zhao在知乎回答中概括得很好,大体如下:
- 这个加权可以是保留所有分量均做加权(即soft attention);也可以是在分布中以某种采样策略选取部分分量(即hard attention),此时常用RL来做。
- 这个加权可以作用在原图上,也就是《Recurrent Model of Visual Attention》(RAM)和《Multiple Object Recognition with Visual Attention》(DRAM);也可以作用在特征图上,如后续的好多文章(例如image caption中的《 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》)。
这个加权可以作用在空间尺度上,给不同空间区域加权;也可以作用在channel尺度上,给不同通道特征加权;甚至特征图上每个元素加权。
这个加权还可以作用在不同时刻历史特征上,如Machine Translation。
2) 任务聚焦:通过将任务分解,设计不同的网络结构(或分支)专注于不同的子任务,重新分配网络的学习能力,从而降低原始任务的难度,使网络更加容易训练。attention机制应用在了哪些地方?(主要关注视觉中的相关应用)
针对于1部分中的attention的两大方式,这里主要关注其在视觉的相关应用中。
介绍了一些相关论文,详见原博客。

若有收获,就点个赞吧
0 人点赞
