09 经典网络解析

AlexNet

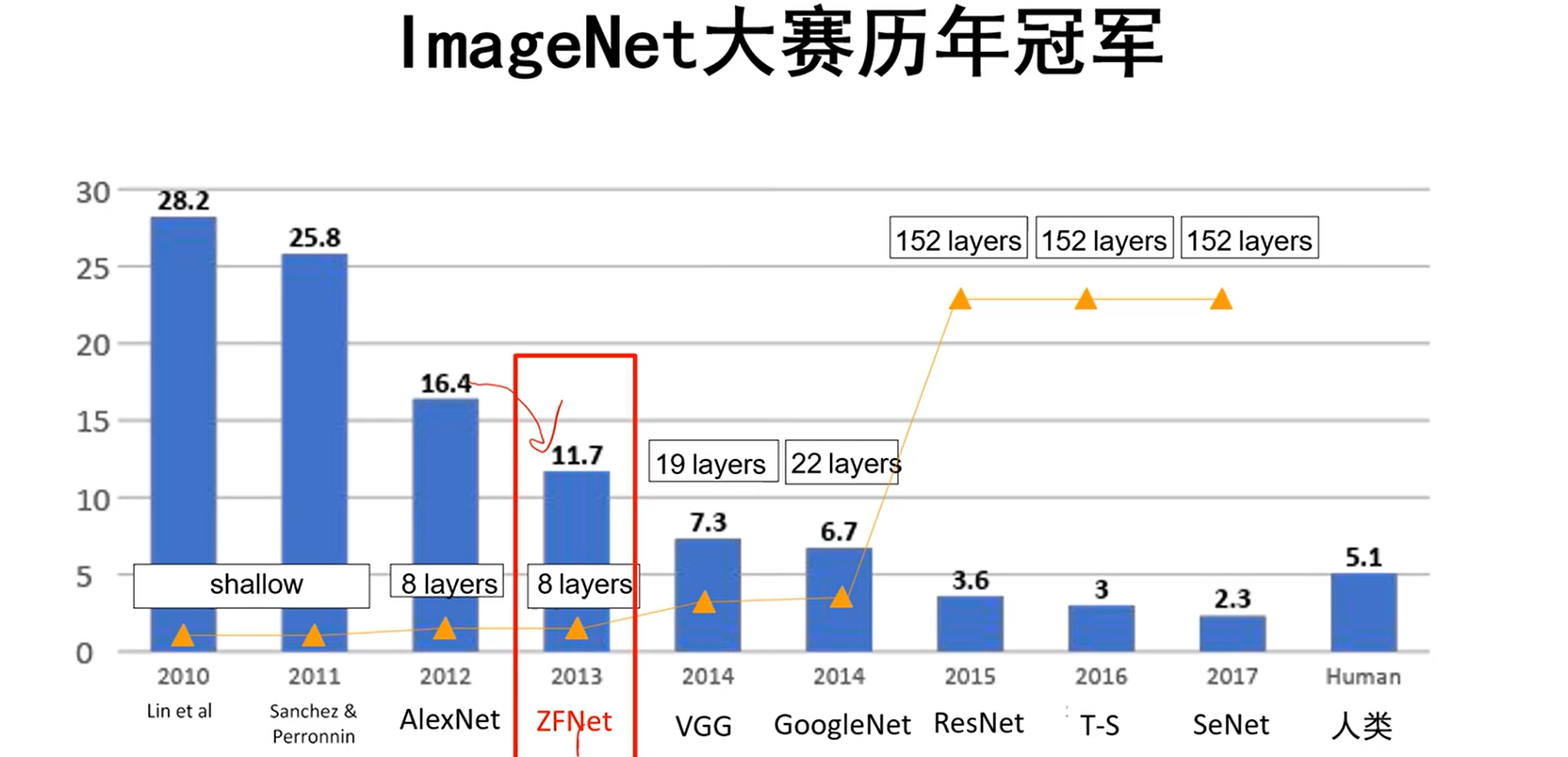
ImageNet大规模视觉挑战赛

主体贡献

层数统计说明

- 第一层
- 输出是96个特征图
- 特征图每个元素经过ReLU函数操作后输出
- 需要注意,输入图像在输入之前经过了去均值处理
- 统计数据集中所有图像的均值向量,也是2272273,这个向量会被存下。
- 当给定图像输入神经网络前,会先将图像减去均值图像后,再输入神经网络。
Q:那么为何要去均值呢?
A:我们在分类时,实际上比较张三和李四,两者绝对数值是没有意义的,我们更多比较是相对值用于分类。去均值是为了保留相对值,来保证数值计算时不会出那么多问题。而且绝对数值对分类很多时候是没有意义的。
:::info
注意,AlexNet去均值的操作和其他网络如VGG是不同的。
:::

- 池化层

- 局部响应归一化层
- 不作详细介绍,后来的网络如VGG就不再使用此层,因为意义不大。

- 同理,第二层256个5*5卷积核,步长为1,使用零填充p=2
- 第二层增加了卷积核的个数,相当于增加了基元的描述能力,能够描述更多的信息。
- 对上一层输出的2727做55卷积,大致相当于在原图上做50*50卷积,有很大的感受野。
- 输出为2727256
- 第三、四个卷积层

- 第五层卷积层(conv5):256个3*3卷积核,步长为1,使用零填充p=1
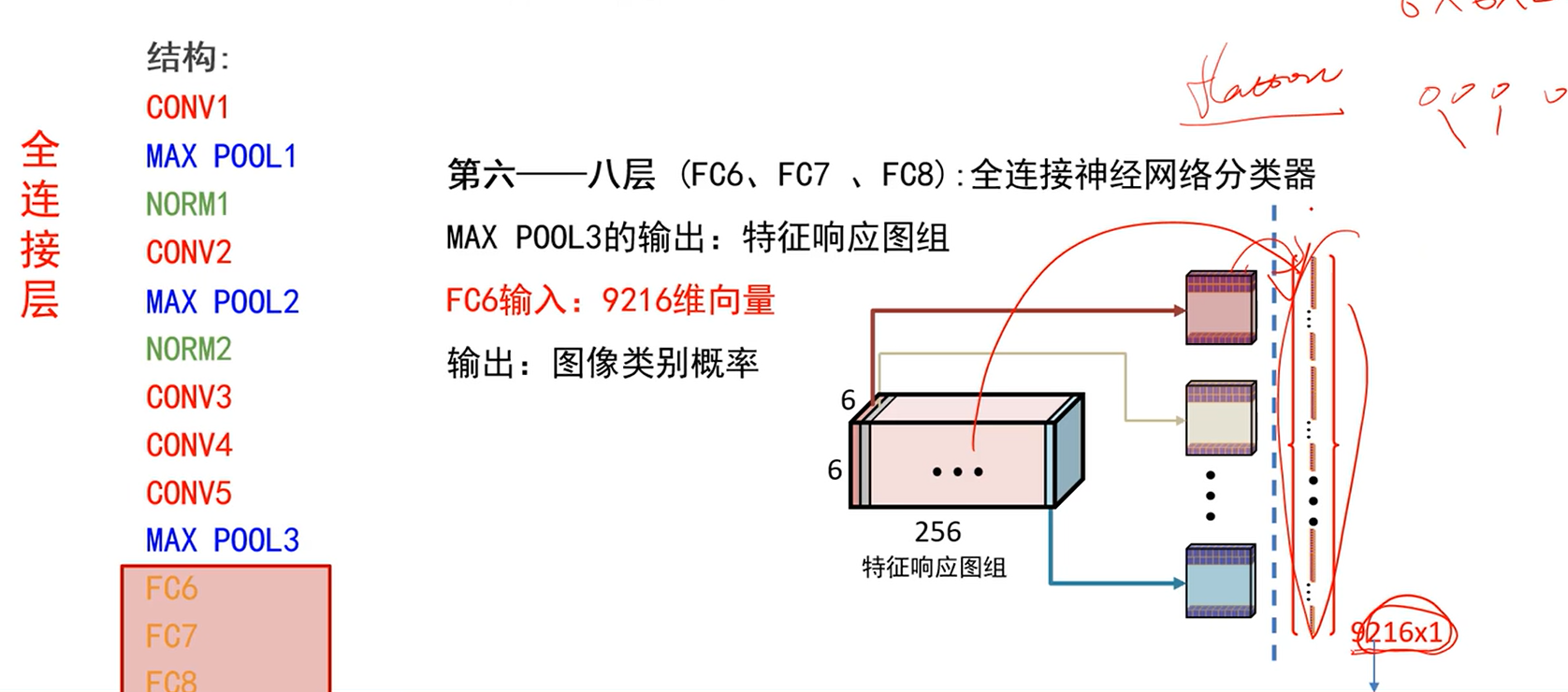
- 第六到第八层:全连接神经网络分类器
- MAX POOL3的输出:66256的特征响应图组
- FC6期望输入:向量,将特征响应图组展开flatten(一个特征图一个特征图连接起来)得到9216维向量。
- 输出:图像类别概率
- 重要说明:
- 整个是端到端的

- 重要技巧:

AlexNet卷积层在做什么?

- 输出是66256的特征图。可以将整个红框圈住的层看成是256个超级卷积核(输出256个特征图,就相当于有256个卷积核)。就可以这样认为:一张图像,经过256个卷积核得到256个特征响应图。
- 从数据中学习对于分类有意义的结构特征
- 描述输入图像中的结构信息
- 描述结果存储在256个6*6的特征响应图里
ZAFNet
这个网络让我们对网络中每个神经元在做什么,或每个卷积核在做什么,有了更深入的理解。
做了如上改进,那么这些改进有什么作用呢?
- 第一个改进:
- 第一个卷积层的卷积核改小,有利于感受细粒度的信息,即不要第一次就丢掉太多细粒度的东西。
- 第二个改进:
- 步长降低是希望分辨率不要很快降下来,而是慢慢降下来,这样不至于像素信息突然从大图变为小图,导致信息损失太快。
- 第三个改进:
- 作者通过可视化发现第三、四层已经不再是基元结构,有了很多种基元组合的结构(概念)了,而模板少是记不住的,分类能力当然弱,因此增加卷积核个数,多一些基元,分类效果就会变好。
VGG

- 输入图像去均值方法:
- 计算均值的方式不同于AlexNet:将图像的每一个点都拿出来,算这些点的r、g、b的均值,得到一个三维向量。
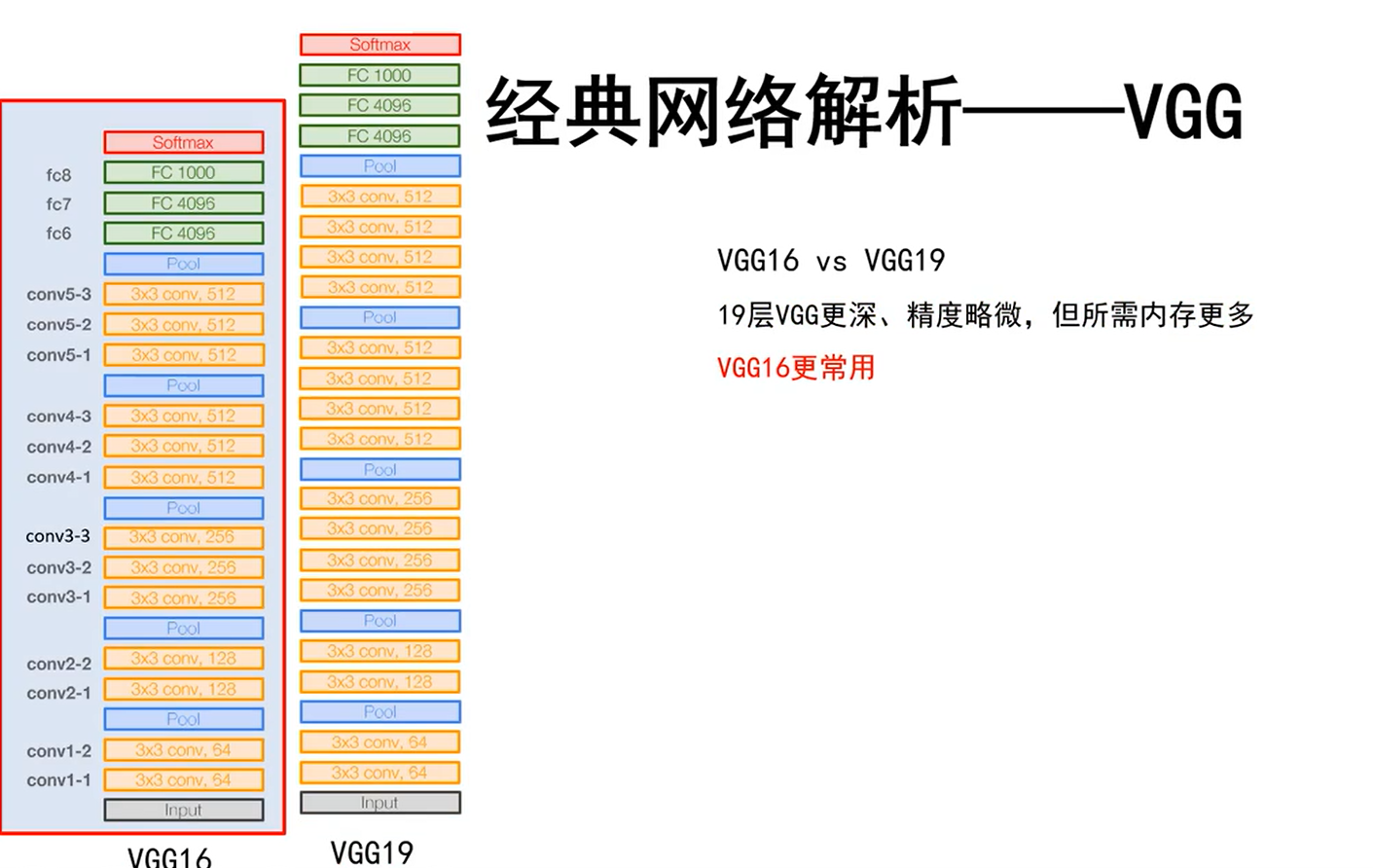
- 采用了5组卷积(一组卷积包含2或3个卷积层),3个全连接。
- 13个卷积层和3个全连接,因此是个16层的网络。

- 为什么每次池化后都增加卷积核个数?
- 因为增加卷积核就能增加模板个数,就能增加图像中学习到的局部模式/结构的个数。
- 为什么前层卷积核少,后层多?

为什么VGG每经过一次池化操作,卷积核个数就增加一倍?

问什么卷积核个数增加到512后就不再增加

VGG16 vs VGG19
VGG证明的一些结论
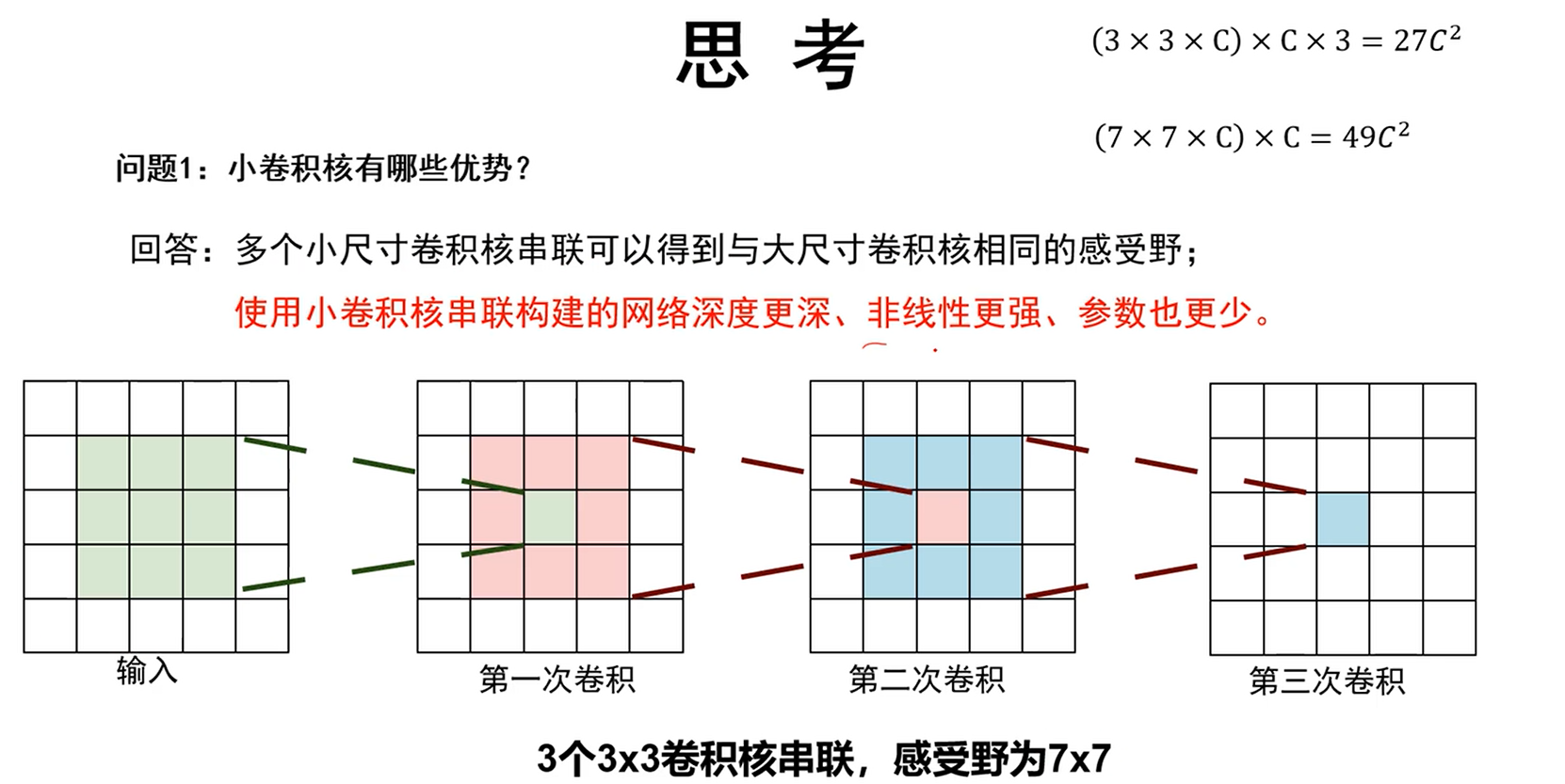
1、往深度上做神经网络对性能是有帮助的
2、小卷积核就足够了,串联能仿真大卷积核的结果
3、AlexNet的归一化层作用并不明显
GoogleNet
- 最大创新点:提出了一种Inception结构

平均池化的思想和我们之前讲纹理时的相似,用平均值代替就可以了,不必使用空间位置,意义不大。
比如有一条很粗的线,如果前一层卷积核较小,那么只会提取到边缘的线,这样就导致信息丢失。
Inception模块
1*1的卷积不会改变长宽,不考虑邻域,考虑的是对一个像素点的所有深度通道上的数值进行非线性操作,在深度方向上进行压缩。
- 3*3是在原始输入信息上提取小感受野的东西
- 5*5是在原始输入信息上提取大感受野的东西
- max pooling相当于将强的信息向周围扩张
- 相当于将前面的特征图在深度方向拼起来,会要求所有的输出都是相同宽高(可以通过padding实现),这样才能连起来。
- 这种方法就得以保留更多的信息。

Inception v1
这样直接用起来会很慢,这么多卷积在里面,尤其5*5卷积,会慢很多,因此提出了下面瓶颈的方法。
- 11卷积不改变宽高,但可以通过控制此层卷积核的个数来改变后面55卷积核的深度(卷积核的深度等于前层输出的特征图的个数)。
- 因此,通过11卷积可以降低深度通道,然后再去做卷积。这样运算量就会小(11卷积本身运算量很小)
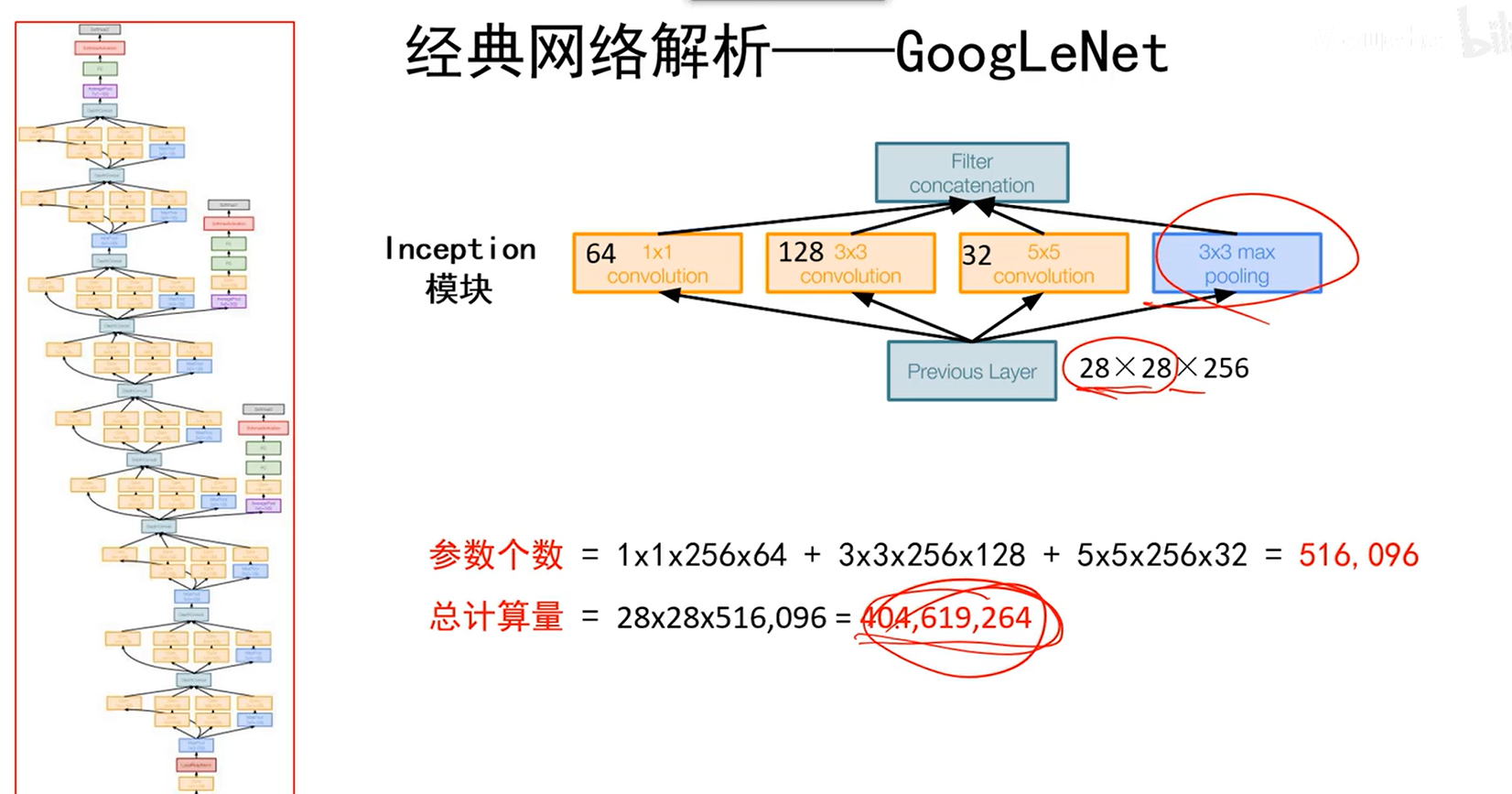

- 注意,新加的层11卷积和后面层的11卷积作用是不一样的。

- 输入:

- 输出:
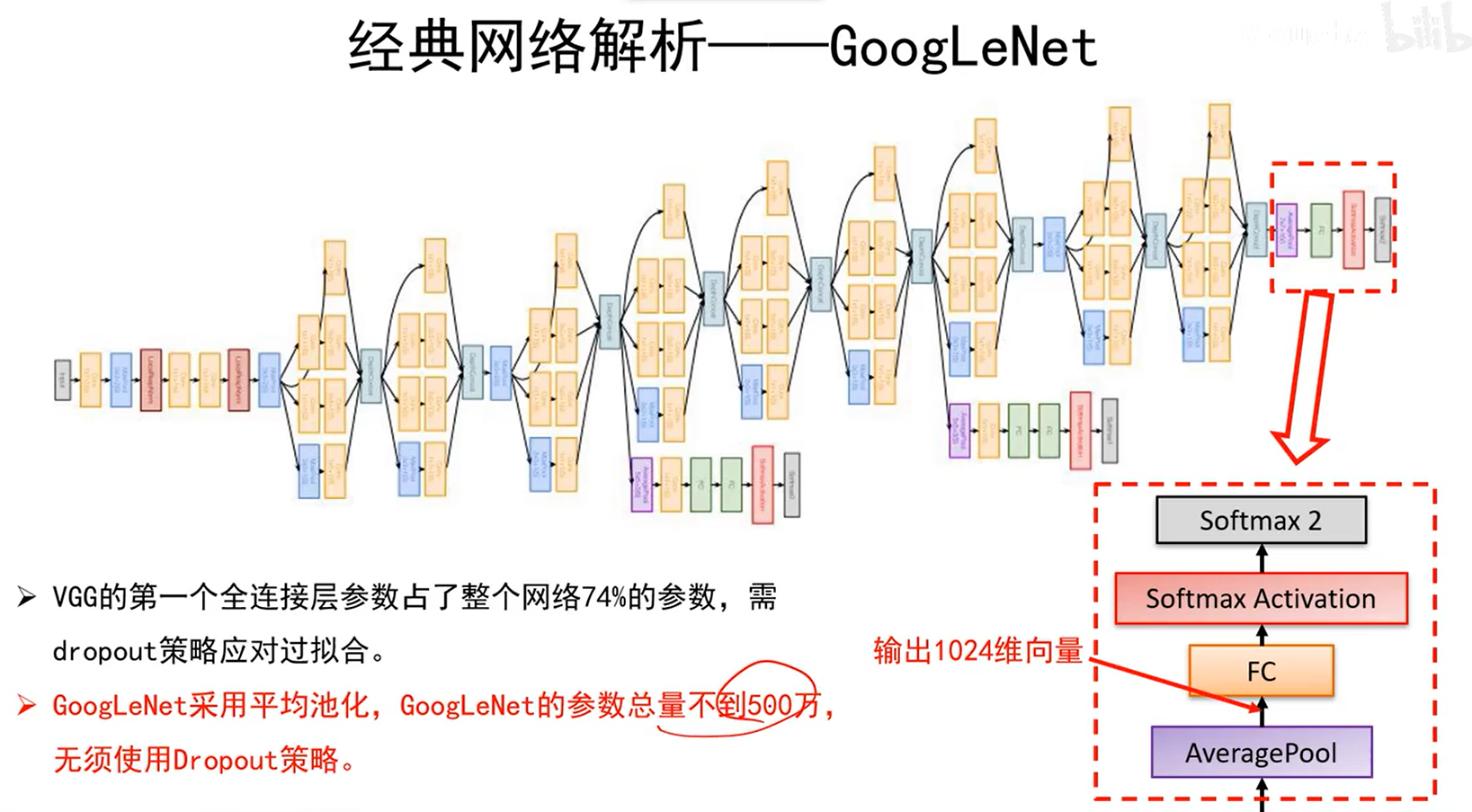
辅助分类器的作用
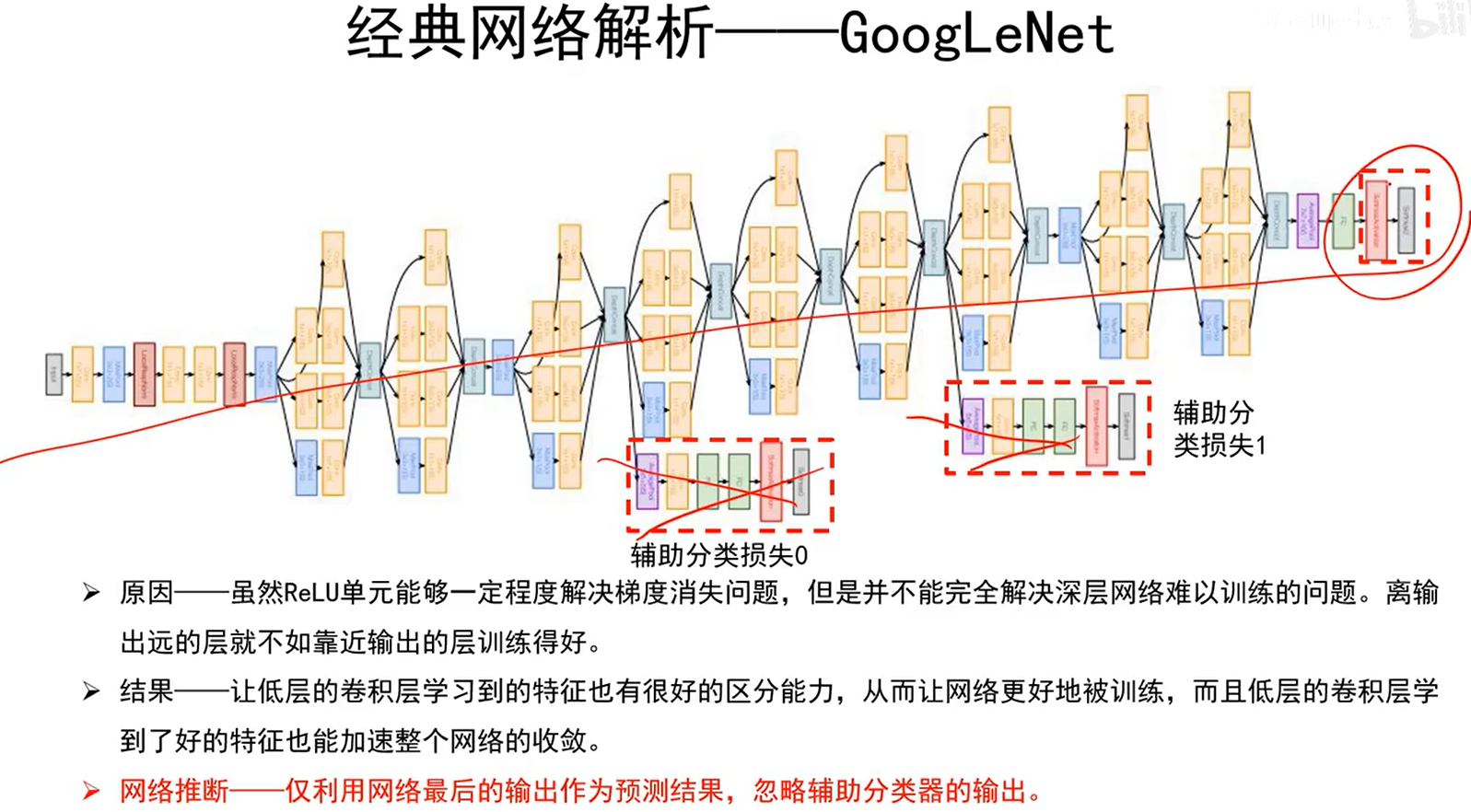
使得上述红线标的地方也能有梯度回传,避免训练过程中网络太深导致的梯度消失问题。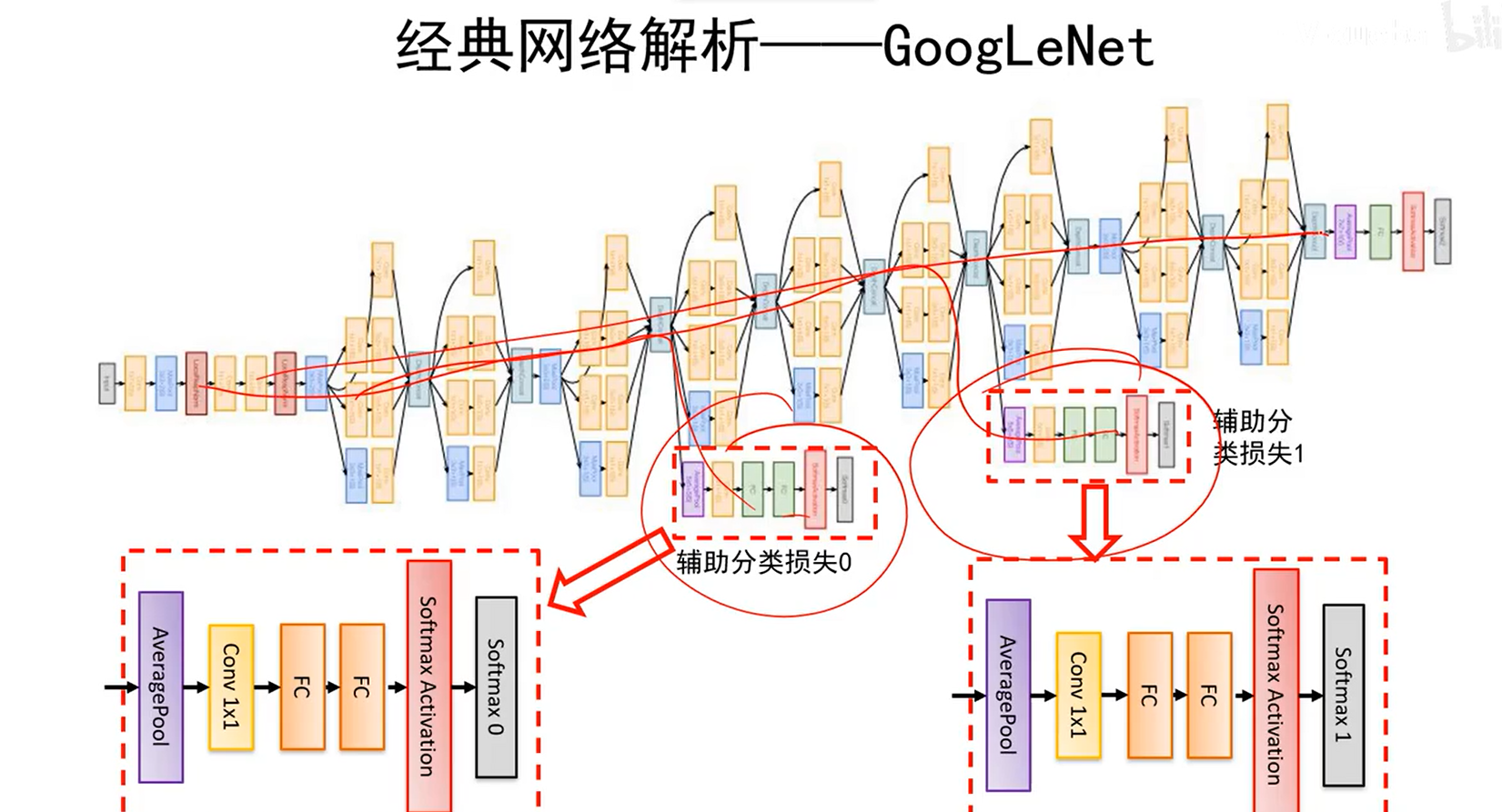
平均池化向量化与直接展开向量化有何区别?


若有收获,就点个赞吧
0 人点赞
