- 没有和任务直接相关的数据。
- 比如输入分布相似,为动物的图片,但task是无关的,要分不同的动物。
- 或者输入分布不同,但要做相同的任务。
迁移学习的问题就是,能不能在有一些不相关数据的情况下,来帮助我们现在要做的task。
why?
Overview
Target Data:有一个我们想做的task,有些和这个task直接相关的data,即target data。
Source Data:和task不相关的data。(不相关的定义很模糊)
两种数据都是可能有标签的或无标签的。因此如下分四个象限讨论。Model Fine-tuning

1、Conservative training
- 加一个约束,比如约束新的模型和旧的模型差距不要太大,来防止overfitting,即target data只有一点点,将模型训练的情形。
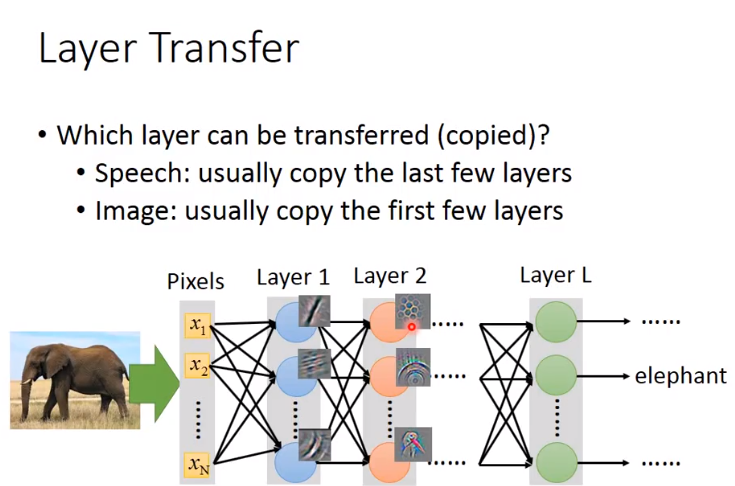
- 2、Layer transfer
- 将source data训练好的模型的某些layer拿出来,copy到新模型
- 接下来用target data训练剩下的layer,这样target data只需考虑较少参数,从而防止overfitting

Multitask Learning
- 同时care target domain 和 source domain 做得好不好,希望都能做好。
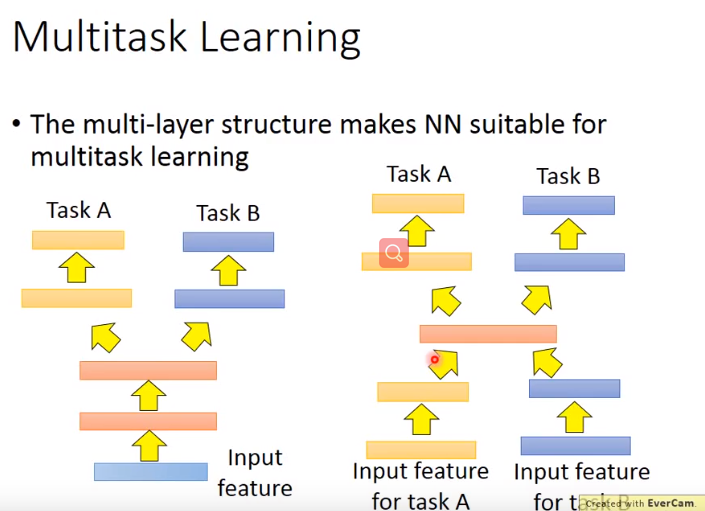
- 如下图:
- 左图,要确定这两个task可以共用前面的层。
- 即使任务A和任务B完全不同,如果你认为中间有共用的地方,也可以用右图来训练。
- 用不同的网络弄到一个domain上,然后应用不同的网络做task A,task B。
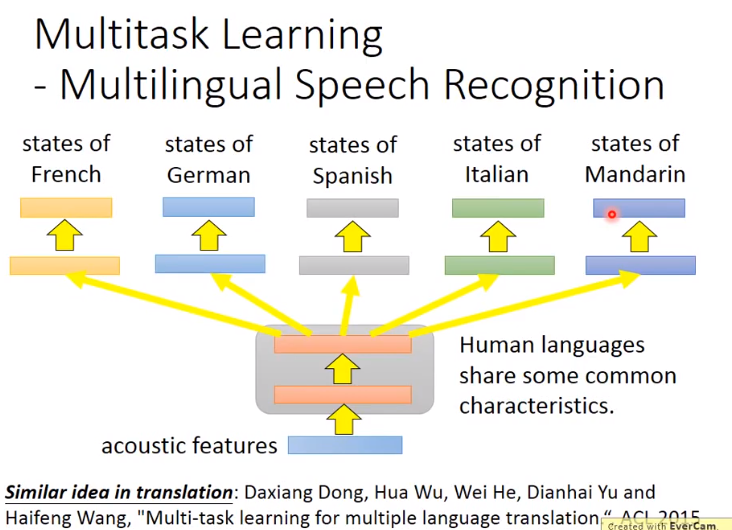
- 多任务学习一个成功的例子是多语言的语音识别:
- 假设手上有一堆不同语言的数据,可以训练一个模型同时识别这几种语言,模型前面的layer可能共用参数,而后面的layer有自己的参数。
如果两个task不像,迁移学习也会有负面作用。negative trasfer。
Domain-adversarial training
任务描述:

这时通常将source data视作训练数据,将target data视作测试数据。然而,训练数据和测试数据是非常mismatch的。
- 这时对抽取的数据特征做tsne降维,可以看出source domain和target domain的数据是在不同点的(不同domain的data数据特征完全不同)。
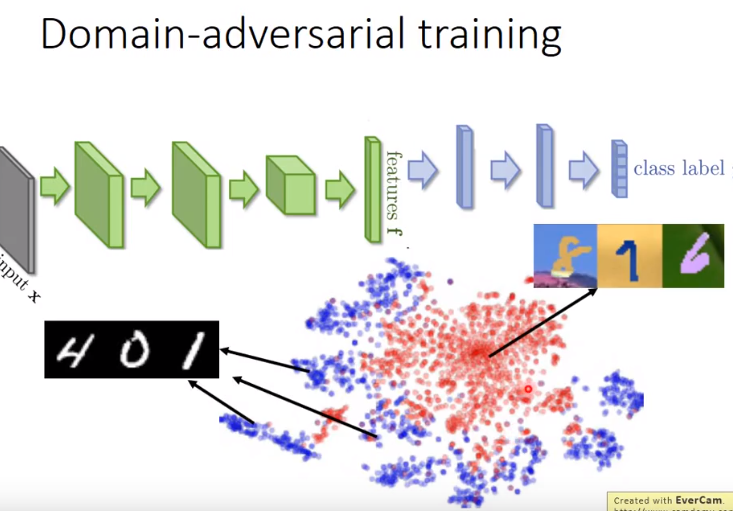
- 因此希望特征提取器可以做到,将domain的特性消掉,即混在一起。
- 因此在后面加一层domain classifier。而只训练domain classifier是不够的,因为特征提取器可以轻易骗过它。
- 因此不只要骗过domian classifier,还要同时让label predictor做得好。
- 即让domain特性消掉的同时保留原来digit的特性。
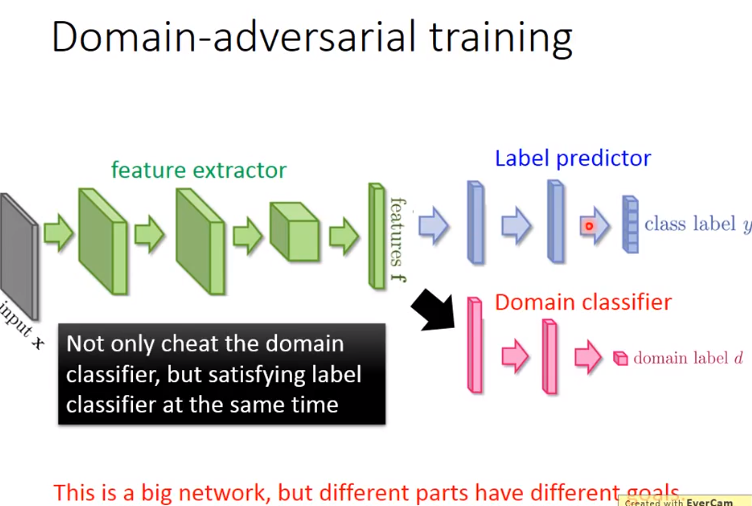
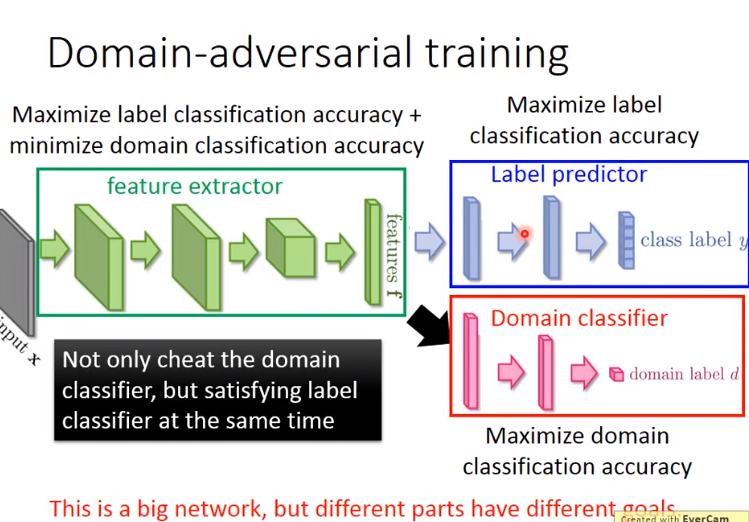
- 这是一个大的神经网络,网络中各部分目标是不同的,如右图。
- 那么特征提取器如何“陷害”domain classfier呢(因为两者目标是不同的)?
- 加一个gradient reversal layer即可,由domain classifier传回的梯度加上负号,让特征提取器做一个和domain classifier相反的事情。
- 最后domain classifier会fail,但它应该奋力挣扎努力判断feature属于哪个domain。
思想类似GAN。
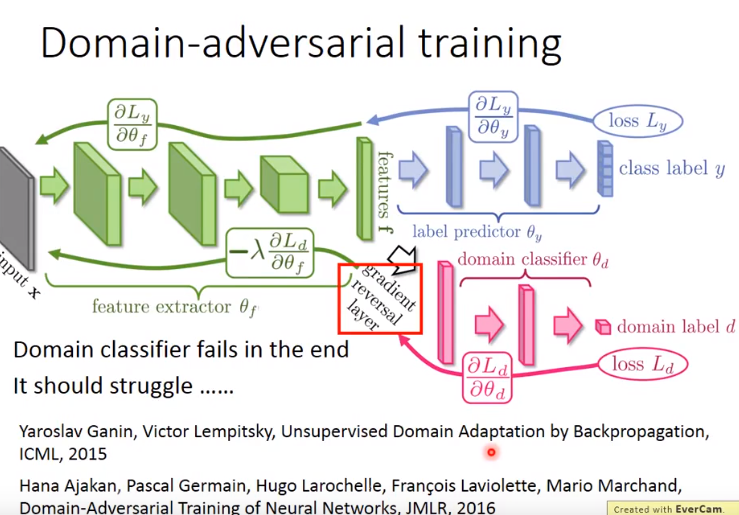
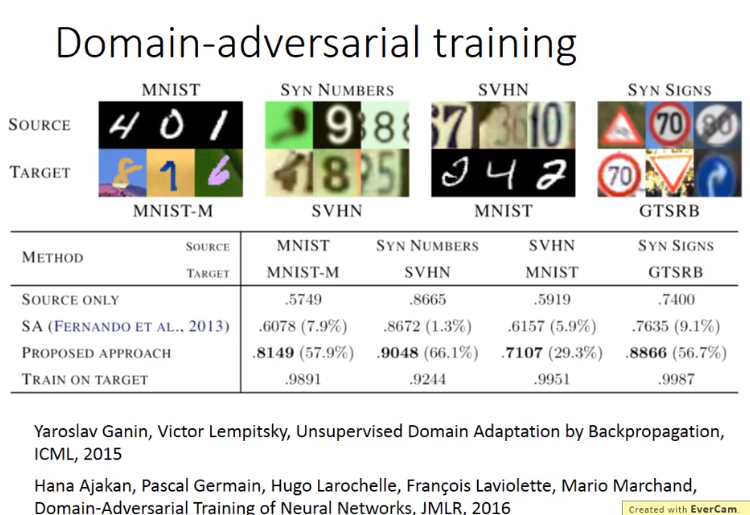
Zero-shot Learning
- 相对于上面的,零样本学习有了更严格的定义,即两个任务是不同的。比如source data要分辨猫和狗,里面有猫、狗的class。但target data里面,图像为羊驼,这在source data里面从来没有出现过。
这在语音识别中有solution,比如将不同的word看作不同的类。那么测试数据里本身有很多词汇就在训练时没有看过。 做法就是,不要直接识别某一段声音属于哪个word,而是识别某一段声音属于哪一个音标。识别的单位,不要定成word,而定成phoneme;然后再做一个phoneme和word间对应关系的表,即词典。这样就算某些word没有出现在训练数据,只要识别出属于哪个phoneme就可以解决这个问题。
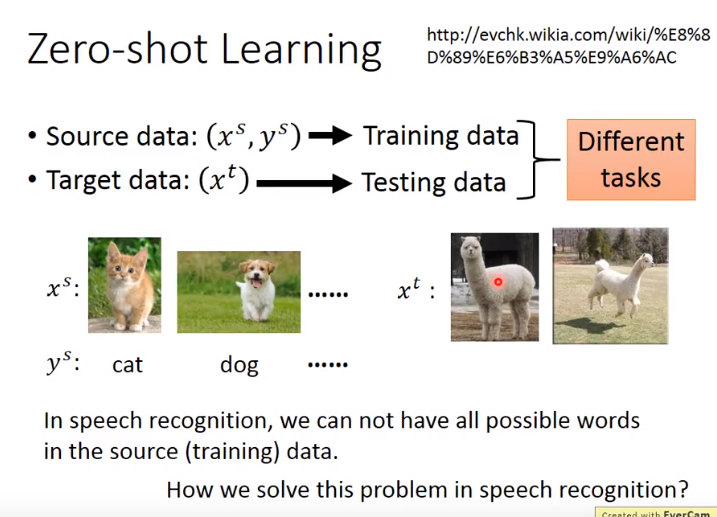
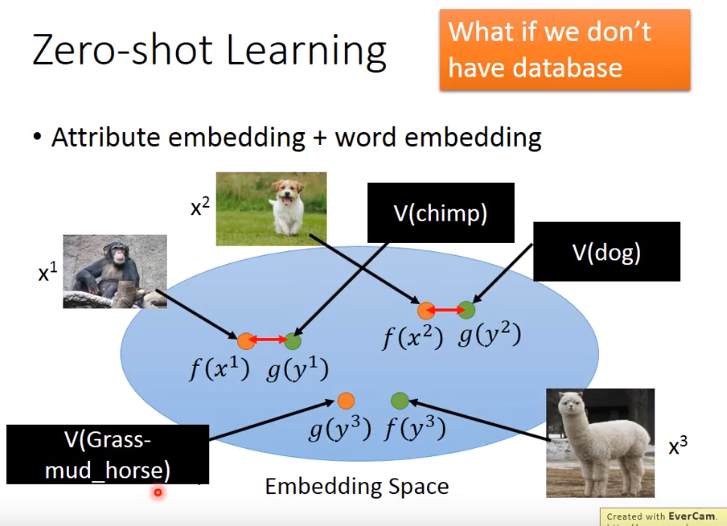
- 在图像上,可以将一个类由它的属性表示。即,有一个database,里面会有所有不同的可能的object和它的属性。属性要定义的足够丰富,对于每个class有独一无二的属性。
- 训练时,不直接识别属于哪个类,而是识别图像具备什么样的属性。
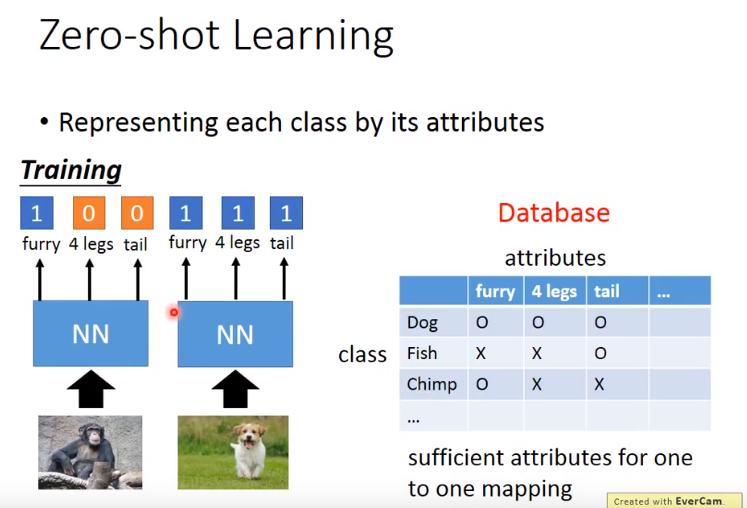

- 有时属性可能非常复杂,维度很大,甚至可以做attribute embedding。
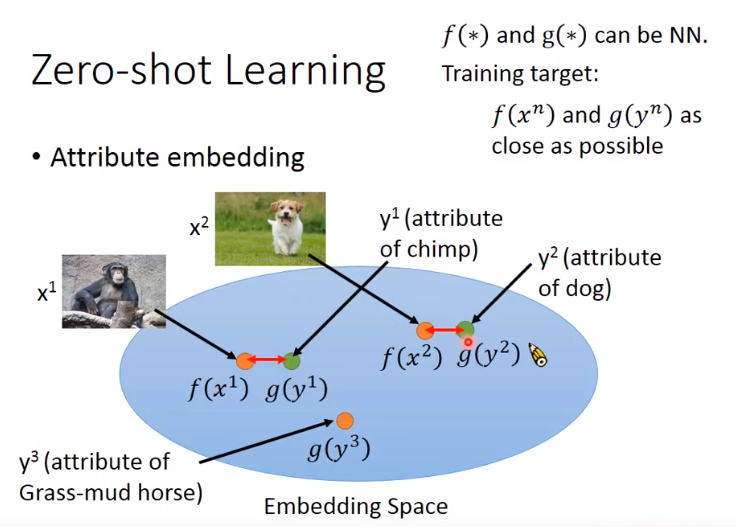
- 比如有一个embedding space,把每个图像都通过一个tranform变成空间上的一个点,然后将所有的属性也变成空间上的一个点。
- 变换f()、g()都可以是神经网络,训练时即希望f(x^n)和g(y^n)越接近越好。
- 测试时,如果有没见过的image,就看这个图像的属性,embedding以后和哪个属性的embedding最接近,就知道是什么类别的图像。
图像和属性都可以表示成向量,因此希望将两者投影到一个空间,但是如何找f、g呢,就是训练神经网络。
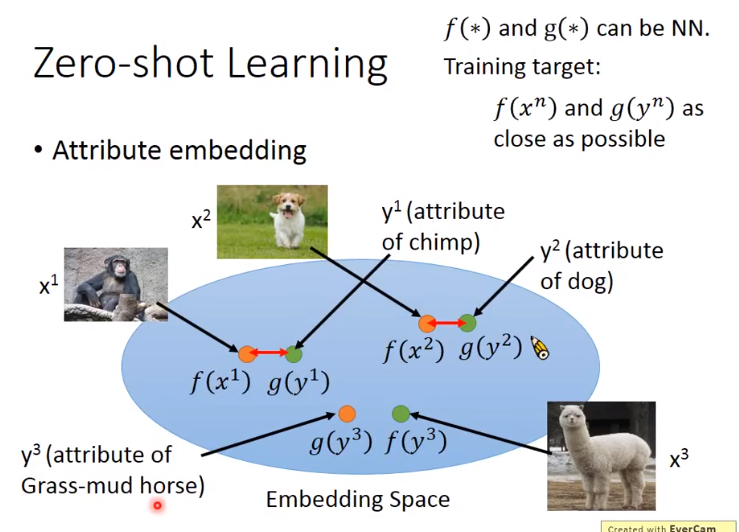
- 有时会遇到一个问题,就是根本没有database,不知道每一个动物的属性是什么。
- 这时可以借用词向量。因为词向量的每个维度代表了现在这个word的某种属性。
- 因此不一定需要一个database来告诉你动物的属性是什么。
- 这时就可以把属性直接换成word vector,再做跟刚才一样的embedding就可以了。

- 训练:
- 我们定义目标时,第一种目标函数是有问题的,因为只考虑了让每个pair越接近越好,而没有考虑到,如果xn和另一个y不是一个pair,它们的距离应该被拉大。
- 如图第二个函数。
- 什么时候会有Zero Loss呢(即损失为0)
- 当如图所示条件时,即左边的乘积大于右边所有的乘积,至少大k。
- 因此这时式子不仅把pair拉近,同时把不成对的拆散。
- 还有个更简单的零样本学习方法:Convex Combination of Semantic Embedding
- 只需要有一组词向量,一个图像识别模型,就可以做这样的transfer learning。



若有收获,就点个赞吧
0 人点赞
