是什么
Keras是一个非常流行、简单的深度学习框架,它的设计参考了torch,用Python语言编写,是一个高度模块化的神经网络库,支持GPU和CPU。能够在TensorFlow,CNTK或Theano之上运行。 Keras的特点是能够快速实现模型的搭建, 简单方便地让你实现从想法到实验验证的转化,这都是高效地进行科学研究的关键。
安装配置
Keras的安装非常简单,但是需要先安装一个后端框架作为支撑,TensorFlow, CNTK,Theano都可以,但是官网上强烈建议使用TensorFlow作为Keras的后端进行使用。本例以TensorFlow 1.4.0 版本作为Keras的后端进行测试。
sudo pip install tensorflow==1.4.0sudo pip install keras==2.1.4
通过上面两条命令就可以完成TensorFlow和Keras的安装,此处需要注意的一点是Keras的版本和TensorFlow的版本要对应,否则会出现意外的错误。具体版本对应关系可在网上进行查询。
tf.keras和keras区别(在tf1.x中)
- keras的历史
keras是François Chollet于2014-2015年开始编写的开源高层深度学习API。所谓“高层”,是相对于“底层”运算而言(例如add,matmul,transpose,conv2d)。keras把这些底层运算封装成一些常用的神经网络模块类型(例如Dense, Conv2D, LSTM等),再加上像Model、Optimizer等的一些的抽象,来增强API的易用性和代码的可读性,提高深度学习开发者编写模型的效率。keras本身并不具备底层运算的能力,所以它需要和一个具备这种底层运算能力的backend(后端)协同工作。keras的特性之一就是可以互换的后端,你在所有后端上写的keras代码都是一样的。从一个后端训练并存储的模型,可以用别的后端加载并运行。
- tf.keras
一个不强调后端可互换性、和tensorflow更紧密整合、得到tensorflow其他组建更好支持、且符合keras标准的高层次API
主要共同点
- 基于同一个API:如果不使用tf.keras的特有特性(见下文)的话,模型搭建、训练、和推断的代码应该是可以互换的。把import keras 换成from tensorflow import keras,所有功能都应该可以工作。反之则未必,因为tf.keras有一些keras不支持的特性,见下文。Google Brain组负责两个代码库之间的同步,每个代码库的重要bug fix和新特性,只要是后端无关的,都会被同步到另一个代码库。
相同的JSON和HDF5模型序列化格式和语义。从一方用model.to_json() 或model.save()保存的模型,可以在另一方加载并以同一语义运行。TensorFlow的生态里面那些支持HDF5或JSON格式的其他库,比如TensorFlow.js,也同等支持keras和tf.keras保存的模型。
主要差别
tf.keras全面支持tensorflow的eager execution模式。eager execution是TensorFlow未来首推的另一个主要特性,也和易用性有关。但是这个对于tf.keras的用户有什么影响呢?如果你只是使用keras.Sequential()或keras.Model()的“乐高式”模型搭建API的话,这个没有影响。Eager execution相对于graph mode的性能劣势,通过tf.function的imperative-to-graph变换来弥补。但是你如果是要自己编写模型内部的运算逻辑的话,结合eager execution和tf.keras.Model方便动态模型的编写。下图里的代码实例展示了如何用这个API来编写一个动态RNN。这样写相对于仅仅使用tensorflow的底层API的好处,在于可以使用`tf.keras.Model`类型所提供的fit()、predict()等抽象。这个特性主要是面向做深度学习研究的用户。
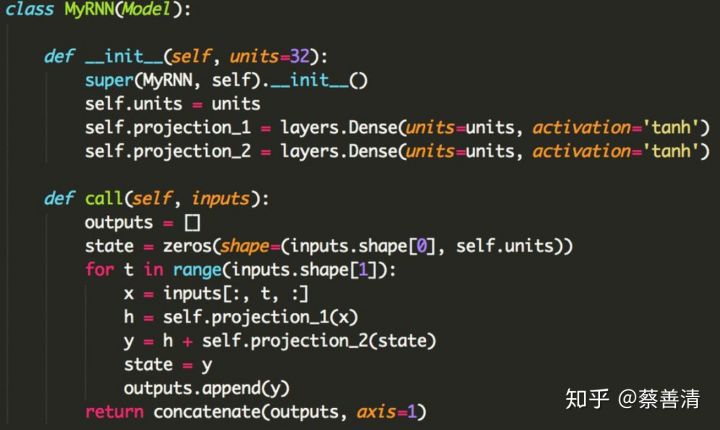
- tf.keras支持基于tf.data的模型训练。tf.data是TensorFlow自2017年初左右推出的新特性。由于基于lazy范式、使用了多线程数据输入管路,tf.data可以显著提高模型训练的效率,同时降低数据相关的代码的复杂性。tf.data带来的性能提高,对于TPU训练来说至关重要。tf.keras.Mode.fit()直接支持tf.data.Dataset 或iterator对象作为输入参数。比如这个MNIST训练例子:https://gist.github.com/datlife/abfe263803691a8864b7a2d4f87c4ab8gist.github.com
- tf.keras支持TPU训练。
tf.keras支持tf.distribution里面的DistributionStrategy进行多GPU或多机分布式训练。tf.distribution是tensorflow里面比较新的API,提供一套易用的分布式训练的抽象,帮助用户实现多卡或多机模型训练。比如,keras用户应该知道,普通版的keras是不支持多GPU训练的。tf.keras可以克服这一局限,详见官方文档里面的例子:https://www.tensorflow.org/guide/distribute_strategy#example_with_keras_apiwww.tensorflow.org
keras也支持多GPU训练,但是基于一个不同的API:
keras.utils.multi_gpu_modeltf.keras的其他特有特性:
tf.keras.models.model_to_estimator():将模型转换成estimator对象 。见文档。tf.contrib.saved_model.save_keras_model():将模型保存为tensorflow的SavedModel格式。见文档。如何选择
如果你需要任何一个上述tf.keras的特有特性的话,那当然应该选择tf.keras。
- 如果后端可互换性对你很重要的话,那选择keras。
- 如果以上两条对你都不重要的话,那选用哪个都可以。
tf2.0 后,建议使用tf.keras
现在已经发布了TensorFlow 2.0,keras和tf.keras都是同步的,这意味着keras和tf.keras仍然是单独的项目; 但是,开发人员应该开始使用tf.keras,因为keras软件包仅支持错误修复。
引用Keras的创建者和维护者Francois Chollet:这也是多后端Keras的最后一个主要版本。展望未来,我们建议用户考虑在TensorFlow 2.0中将其Keras代码切换为tf.keras。它实现了相同的Keras 2.3.0 API(因此切换应该像更改Keras导入语句一样容易),但是它对TensorFlow用户具有许多优势,例如支持eager execution, distribution, TPU training, and generally far better integration 在低层TensorFlow和高层概念(如“层”和“模型”)之间。它也得到更好的维护。 ———————————————— 版权声明:本文为CSDN博主「客服小羊」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/cpongo1/article/details/102818620
08-23 keras入门-HelloWorlddone
keras.metrics
keras里两种model:序列模型和函数式模型
1、序列模型:序贯模型是多个网络层的线性堆叠。
2、Keras函数式模型接口是用户定义多输出模型、非循环有向模型或具有共享层的模型等复杂模型的途径。一句话,只要你的模型不是类似VGG一样一条路走到黑的模型,或者你的模型需要多于一个的输出,那么你总应该选择函数式模型。
常用层 keras.layers
1、Dense层
2、Dropout层
3、Activition层
优化算法 keras.optimizers
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
- lr:大于0的浮点数,学习率
- momentum:大于0的浮点数,动量参数
- decay:大于0的浮点数,每次更新后的学习率衰减值
-
评估指标
keras.metrics模型编译
# 对模型进行预编译,其损失函数为多类别交叉熵,优化算法为sgd,# 评估方法为多类别准确度和平均绝对误差。model.compile(loss='categorical_crossentropy',optimizer=sgd,metrics=[metrics.categorical_accuracy, metrics.mae])
在训练模型之前,我们需要通过compile来对学习过程进行配置。compile接收三个参数:
优化器optimizer:该参数可指定为已预定义的优化器名,如rmsprop、adagrad,或一个Optimizer类的对象,详情见optimizers
- 损失函数loss:该参数为模型试图最小化的目标函数,它可为预定义的损失函数名,如categorical_crossentropy、mse,也可以为一个损失函数。详情见losses
- 指标列表metrics:对分类问题,我们一般将该列表设置为metrics=[‘accuracy’]。指标可以是一个预定义指标的名字,也可以是一个用户定制的函数.指标函数应该返回单个张量,或一个完成metric_name - > metric_value映射的字典.请参考性能评估
模型训练与测试
训练:
测试:model.fit(train_data, train_label, epochs=50, batch_size=100)
evaluate(self, x, y, batch_size=32, verbose=1, sample_weight=None)
fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况。
模型总结
print(model.summary())
由模型总结我们看到神经网络每一层的输入输出大小以及需要训练的参数个数,非常明了。
keras常用方法 & 不同版本中的方法差异
比如将label转为one-hot形式:
先前版本:keras.utils.np_utils..to_categorical()
之后版本:keras.utils.to_categorical()
to_categorical(y, num_classes=None, dtype=’float32’)
参考:https://www.cnblogs.com/klausage/p/12309823.html
- 输入:将整型的类别标签转为onehot编码。y为int数组,num_classes为标签类别总数,大于max(y)(标签从0开始的)。
- 输出:如果num_classes=None,返回len(y) [max(y)+1](维度,mn表示m行n列矩阵,下同),否则为len(y) * num_classes。
import kerasohl=keras.utils.to_categorical([1,3])# ohl=keras.utils.to_categorical([[1],[3]])print(ohl)"""[[0. 1. 0. 0.][0. 0. 0. 1.]]"""ohl=keras.utils.to_categorical([1,3],num_classes=5)print(ohl)"""[[0. 1. 0. 0. 0.][0. 0. 0. 1. 0.]]"""
model.fit()
版本1.2里面是nb_epoch ,而keras2.0是epochs = 10

若有收获,就点个赞吧
0 人点赞
