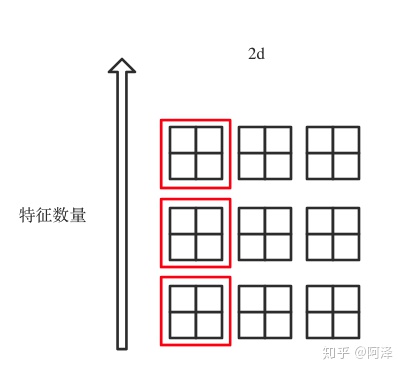
LN
我们知道 BN 是在针对特征的每个维度求当前 batch 的均值和方差,此时便会出现两个问题:
- 当 batch 较小时不具备统计意义,而加大的 batch 又收到硬件的影响;
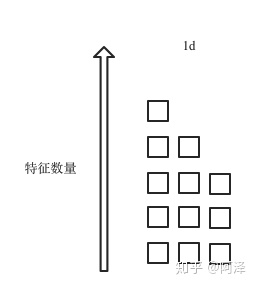
- BN 适用于 DNN、CNN 之类固定深度的神经网络,而对于 RNN 这类 sequence 长度不一致的神经网络来说,会出现 sequence 长度不同的情况,如下图所示:
- 解决的方法很简单,直接竖着来,针对样本进行规范化,如下图所示,
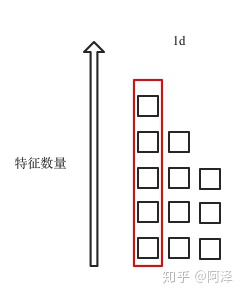
值得注意的是:
 也由共享参数变为逐神经元的参数(RNN 有 n 个神经元,则有 2n 个参数)。
也由共享参数变为逐神经元的参数(RNN 有 n 个神经元,则有 2n 个参数)。

若有收获,就点个赞吧
0 人点赞
