- TypeError: unsupported operand type(s) for +=: ‘builtin_function_or_method’ and ‘builtin_function_or_method’
- Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you
- 模型复现相关操作
- torch.Tensor()和torch.tensor()的区别
- 其他创建张量方式
- 查看张量类型x.type()与tyoe(x)
- 查看张量尺寸
- 对tensor中的每一行求乘积
- pytorch中图像的数据格式
- dim
- 使用Pytorch构建网络时,损失函数需要迁移到GPU上吗
TypeError: unsupported operand type(s) for +=: ‘builtin_function_or_method’ and ‘builtin_function_or_method’
因为python中的函数、方法等也是对象,因此,比如如下情况,float后面没写括号,这时item_tensor是一个方法,而不是转化成FloatTensor类型的张量,此时将item_tensor拿去做运算,就会出现上述错误。
item_tensor = torch.from_numpy(item).float# 正确写法item_tensor = torch.from_numpy(item).float()
Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you
参考:https://blog.csdn.net/weixin_37913042/article/details/103018611;https://www.it610.com/article/1295762151889248256.htm
开头加上下面语句即可:
from torch.multiprocessing import set_start_methodtry:set_start_method('spawn')except RuntimeError:pass
模型复现相关操作
为什么使用相同的网络结构,跑出来的效果完全不同,用的学习率,迭代次数,batch size 都是一样?固定随机数种子是非常重要的。但是如果你使用的是PyTorch等框架,还要看一下框架的种子是否固定了。还有,如果你用了cuda,别忘了cuda的随机数种子。这里还需要用到torch.backends.cudnn.deterministic.
torch.backends.cudnn.deterministic是啥?顾名思义,将这个 flag 置为True的话,每次返回的卷积算法将是确定的,即默认算法。如果配合上设置 Torch 的随机种子为固定值的话,应该可以保证每次运行网络的时候相同输入的输出是固定的,代码大致这样
def init_seeds(seed=0):torch.manual_seed(seed) # sets the seed for generating random numbers.torch.cuda.manual_seed(seed) # Sets the seed for generating random numbers for the current GPU. It’s safe to call this function if CUDA is not available; in that case, it is silently ignored.torch.cuda.manual_seed_all(seed) # Sets the seed for generating random numbers on all GPUs. It’s safe to call this function if CUDA is not available; in that case, it is silently ignored.if seed == 0:torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = False
实例:AREN代码里面的操作:
def fix_seeds(config): # 这是为了保证可以复现吗seed = config['seed']np.random.seed(seed)random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)cudnn.benchmark = False # ensure the deterministictorch.set_default_tensor_type('torch.cuda.FloatTensor')cudnn.deterministic = Truereturn config
torch.Tensor()和torch.tensor()的区别
- torch.Tensor是默认的tensor类型(全局默认dtypetorch.FlaotTensor)的简称。
torch.Tensor()是pytorch中用于创建未初始化矩阵的函数。即使该矩阵未被初始化,也是存有随机值的。
- torch.tensor根据后面的data创建Tensor,Tensor类型根据数据进行推断。
- 从下面可以看出,
torch.Tensor()的参数表示形状,torch.tensor参数表示实际数据(NumPy ndarray,list,tuple等)。这里再说一下torch.empty(),empty()返回一个包含未初始化数据的张量。使用参数可以指定张量的形状、输出张量、数据类型。 由于torch.Tensor()只能指定数据类型为torch.float,所以torch.Tensor()可以看做torch.empty()的一个特殊情况
>>> a=torch.tensor(1)>>> atensor(1)>>> a.type()'torch.LongTensor'>>> a=torch.Tensor(1)>>> atensor([0.])>>> a.type()'torch.FloatTensor'
其他创建张量方式
torch.zeros()/ones/eye()/rand() 用来创建张量时,创建的都是FloatTensor,并且传入的参数代表形状。可以是以下方式:
# 以下三种方式同义torch.zeros(1,2)torch.zeros((1,2))torch.zeros([1,2])rand = torch.rand(2, 3) # 返回一个张量,包含了从区间[0,1)的均匀分布中抽取的一组随机数,形状由可变参数sizes 定义。randn = torch.randn(2, 3) # 返回一个张量,包含了从标准正态分布(均值为0,方差为 1,即高斯白噪声)中抽取一组随机数,形状由可变参数sizes定义
查看张量类型x.type()与tyoe(x)
对于Tensor,更推荐采用x.type()来查看数据类型。是因为x.type()的输出结果为’torch.LongTensor’或’torch.FloatTensor’,可以看出两个数组的种类区别。而采用type(x),则清一色的输出结果都是torch.Tensor,无法体现类型区别。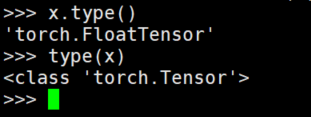
注意numpy中没有x.type()的用法,只能用type(x)
查看张量尺寸
import torchimport numpy as npa = np.array([[1,2,3],[4,5,6]])x = torch.tensor(a)print("numpy:")print("Shape of a:",a.shape)print("Type of a.shape:", type(a.shape))print("Size of a:", a.size)print("-------------")print("pytorch:")print("Shape of x:",x.shape)print("Size of x:",x.size())print("Type of x.size():",type(x.size()))numpy:Shape of a: (2, 3)Type of a.shape: <class 'tuple'>Size of a: 6-------------pytorch:Shape of x: torch.Size([2, 3])Size of x: torch.Size([2, 3])Type of x.size(): <class 'torch.Size'>
在关于pytorch的size()中,我们通过和numpy类比,可以发现,
- pytorch的size()的功能和numpy的shape属性类似,而和numpy的size属性是不一样的,numpy的size属性是求元素总数。
另外,pytorch的size()功能和属性shape一样。
还有,pytorch的torch.size()是一个元组,可以实现python中的元组的一系列操作。
import torchimport numpy as npa = np.array([[1,2,3],[4,5,6]])x = torch.tensor(a)print(x.size()[1:])# torch.Size([3])
对tensor中的每一行求乘积
x = torch.prod(x, dim=1)或x=x.prod(dim=1)pytorch中图像的数据格式
参考:https://blog.csdn.net/weixin_40490880/article/details/86488532
dim
一个加深理解的场景:比如空间注意力机制中,对特征图,在通道上进行平均池化,做法为
torch.mean(x, dim=1, keepdim=True),dim=1则说明第二维度由通道数C变成1。[batch, C, H, W]->[batch, 1, H, W]使用Pytorch构建网络时,损失函数需要迁移到GPU上吗
输入数据需要移到cuda,然后loss函数在计算的时候本身就是在GPU上,因为它包含的计算元素本身就已经在cuda上了。输出数据移到CPU才print。
- 在进行pytorch 训练时候,输入的数据tensor,以及模型需要.cuda,但是在做损失函数的时候,就不需要将Loss函数设置为cuda形式了,因为此时送入loss的数据已经是cuda类型的了,损失就会在这上面直接计算。

若有收获,就点个赞吧
0 人点赞
