PyTorch进行多标签分类
PyTorch中的实现
PyTorch提供了两个类来计算二分类交叉熵(Binary Cross Entropy),分别是BCELoss() 和BCEWithLogitsLoss()
- BCEWithLogitsLoss MultiLabelSoftMarginLoss两个损失函数是相同的。
阅读《Multil-Label Zero-Shot Learning With Structured Knowledge Graph》
- 多标签常见解决思路 多标签学习&相关论文阅读
利用神经网络,我们可以很轻松处理一个多标签问题。与单标签不同的是,将网络的softmax换成sigmoid函数,同时在输出层使用某个阈值判断标签分类结果。例如输出结果[0.1, 0.9, 0.8, 0.2, 0.85],使用阈值0.5(阈值可以自己设置,或通过学习得到),预测label即为[0,1,1,0,1]
多标签图像分类综述
在CNN-RNN结构的基础上,后续文章又加入Regional LSTM模块。该模块可以对CNN的特征进行导向处理,从而获取特征的位置信息,并计算位置信息和标签之间的相关性。在上文的结果上进一步考虑了特征、位置和标签之间潜在的依赖关系,可以有效计算图片中多个标签同时存在的可能性,并进行图片的分类。
评价指标:
- 平均准确率(AP)和平均准确率均值(mAP)
同单标签分类一样,当一张图片中的所有标记均预测正确时,准确率才可以置1,否则置零。每个类别下的标签分别进行计算后,取其平均值即可获得平均准确率,对所有平均准确率取均值即可获得平均准确率均值。平均准确率可以衡量模型在每个类别的好坏程度,而平均准确率均值则衡量的是在所有类别的好坏程度。 - 汉明距离
将预测的标签集合与实际的标签集合进行对比,按照汉明距离的相似度来衡量。汉明距离的相似度越高,即汉明损失函数越小,则模型的准确率越高。- 1-错误率
1-错误率用来计算预测结果中排序第一的标签不属于实际标签集中的概率。其思想相当于单标签分类问题中的错误率评价指标。1-错误率越小,说明预测结果越接近实际标签,模型的预测结果也就越好。
- 覆盖率(?)
覆盖率用来度量“排序好的标签列表”平均需要移动多少步数,才能覆盖真实的相关标签集合。对预测集合Y中的所有标签{y1,y2,… yi … yn}进行排序,并返回标签yi在排序表中的排名,排名越高,则相关性越差,反之,相关性越高。
- 排序损失(?)
排序损失计算的是不相关标签比相关标签的相关性还要大的概率。
数据集
- Pascal VOC数据集的主要任务是在真实场景中识别来自多个类别的目标。该数据集共有近两万张图片,共有20个类别组成。Pascal VOC官方对每张图片都进行了详细的信息标注,包括类别信息、边界框信息和语义信息,均保存在相应的xml格式文件中。通过读取xml文件中的项,我们可以获取到单张图片中包含的多个物体类别信息,从而构建多标签信息集合并进行分类训练。
- COCO(Common Objects in Context)数据集由微软公司赞助搭建。该数据集包含了91个类别,三十余万张图片以及近二百五十万个标签。与Pascal VOC相类似,COCO数据的标注信息均保存在图片对应的json格式文件中。通过读取json文件中的annotation字段,可以获取其中的category_id项,从而获取图片中的类别信息。同一json文件中包含多个category_id项,可以帮助我们构建多标签信息。COCO数据集的类别虽然远远大于Pascal VOC,而且每一类包含的图像更多,这也更有利于特定场景下的特征学习。
除了上述两个个主流数据集之外,比较常用的还包括ImageNet数据集、NUS-WIDE数据集。近年来,诸多公司、科研机构也提出了诸多全新的数据集,如ML-Images等。这些标注完善的数据,为多标签图像分类的研究提供了有力的支持,同样也为图像处理领域的发展做出了巨大贡献。
挑战
(1) 多标签图像分类的可能性随着图片中标签类别的增加呈指数级增长,在现有的硬件基础上会加剧训练的负担和时间成本,如何有效的降低信息维度是面临的最大挑战。
(2) 多标签分类往往没有考虑类别之间的相关性,如房子大概率不会出现老虎、海洋上不太可能出现汽车。对于人类来说,这些均是常识性的问题,但对于计算机却是非常复杂的过程,如何找到类别之间的相关性也能够更好的降低多标签图像分类的难度。
TODO
Pytorch多标签图像分类简明教程(没有包括训练过程的代码,因此没看)
按照Pytorch从入门到放弃(6)——实现图像多标签的训练与分类进行实现,数据集用遗传病人脸图像。
1、GetLabel.py将csv存储的人脸数据库,转化为要求的输入形式,存到input.txt。(注意,csv文件中每一行为一个患者,一个患者对应三张图片,我们只取其中的正脸图像,判断正脸使用百度人脸识别api实现util/analyse.py)
[python3 csv的读写](https://blog.csdn.net/katyusha1/article/details/81606175?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task)`list.index(item)`返回列表中指定元素的下标(仅返回第一个元素的)
数据的一些注意事项: 这边建模需要用到NC对照数据,就只用EXCEL里的数据就好了(这批数据都做过基因检测为正常),不在表里的NC数据成分复杂,有的是携带者有的不明,暂时可以不管。 如果咱们用不到和正常人对照这块,也可以先不管NC所有的数据。
- BC结尾携带者(是否意味着BC开头的都无法使用?),事实上,图片数据中也没有BC开头的
GZ是南方医标注的,对方标注一部分后觉得数据质量较差,不建议使用GZ开头的照片。
\N代表具体不清楚,可能是选项中没有合适的,也可能是看不清,或者就是没有明显异常
在Python中 \ 是转义符,**\u**表示其后是UNICODE编码,因此\User在这里会报错,在字符串前面加个 **r(rawstring 原生字符串)**,可以避免python与正则表达式语法的冲突!因为有些属性值是`\N\N`,为了排除这些图片。使用`if a == r'\N\N'`。判断是否以某个字符串开头或结尾:`str.startswith(), str.endswith()`python3写入txt文件:f.write(str)即可,但注意,不会自动写入换行,并且只支持写入字符串。`list = [1, 0, 1]`转化为用空格隔开的字符串`'1 0 1'`:`' '.join(str(i) for i in list)`join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串:`str.join(sequence)`,连接的序列可以是字符串/集合/元组/字典,如果是字典,会将所有key连接起来。
2、Split_Train_Val.py:划分input.txt为训练集train.txt和测试集test.txt
通用方法参考:[用python将一个数据文件分为训练集和测试集](https://blog.csdn.net/Albert201605/article/details/82319437)`random.sample()`用法,多用于截取列表的指定长度的随机数,但是不会改变列表本身的排序。
lz0021患者四张图像都不是正面,已在input中将此数据删去
3、Multi-Label-Classification.py:定义了模型的损失函数为BCELoss,然后进行训练,并存储了模型参数。但并没有对模型进行评价。
4、Test.py:
pytorch模型的加载:[PyTorch加载模型和参数](https://blog.csdn.net/lscelory/article/details/81482586)1、直接加载模型和参数
# 保存和加载整个模型torch.save(model_object, 'resnet.pth')model = torch.load('resnet.pth')
2、分别加载网络的结构和参数
# 将my_resnet模型储存为my_resnet.pthtorch.save(my_resnet.state_dict(), "my_resnet.pth")# 加载resnet,模型存放在my_resnet.pthmy_resnet.load_state_dict(torch.load("my_resnet.pth"))
.pkl和.pth的区别:但其实不管pkl文件还是pth文件,都是以二进制形式存储的,没有本质上的区别,你用pickle这个库去加载pkl文件或pth文件,效果都是一样的。
pytorch,替换tensor中大于某个值的所有元素。
a = torch.rand((2, 3))# tensor([[0.2620, 0.4850, 0.5924],# [0.4152, 0.0475, 0.5491]])zero = torch.zeros_like(a)# tensor([[0., 0., 0.],# [0., 0., 0.]])one = torch.ones_like(a)# tensor([[1., 1., 1.],# [1., 1., 1.]])# a中大于0.5的用zero(0)替换,否则a替换,即不变a = torch.where(a > 0.5, zero, a))# tensor([[0.2620, 0.4850, 0.0000],# [0.4152, 0.0475, 0.0000]])# a中大于0.5的用one(1)替换,否则a替换,即不变print(torch.where(a > 0.5, one, a))# tensor([[0.2620, 0.4850, 1.0000],# [0.4152, 0.0475, 1.0000]])
numpy,矩阵中大于某个值的所有元素,如置0。
# 矩阵a中大于Threshold(阈值)的部分置0a[a > Threshold] = 0# 矩阵a中小鱼Threshold(阈值)的部分置0a[a < Threshold] = 0
评价指标:
hamming距离(sklearn有实现):直接统计了被误分类的label的个数(不属于这个样本的标签被预测,或者属于这个样本的标签没有被预测)
F1值(sklearn有实现):取值0~1.除了F1分数之外,F0.5分数和F2分数,在统计学中也得到了大量应用,其中,F2分数中,召回率的权重高于精确率,而F0.5分数中,精确率的权重高于召回率。 Micro-F1和Macro-F1:在第一个多标签分类任务中,可以对每个“类”,计算F1,显然我们需要把所有类的F1合并起来考虑。这里有两种合并方式: 第一种计算出所有类别总的Precision和Recall,然后计算F1。 例如依照最上面的表格来计算:Precison=5/(5+4)=0.556,Recall=5/(5+4)=0.556,然后带入F1的公式求出F1,这种方式被称为Micro-F1微平均。 第二种方式是计算出每一个类的Precison和Recall后计算F1,最后将F1平均。 例如上式A类:P=2/(2+0)=1.0,R=2/(2+2)=0.5,F1=(2_1_0.5)/1+0.5=0.667。同理求出B类C类的F1,最后求平均值,这种方式叫做Macro-F1宏平均。 分类问题的几个评价指标
多标签评价指标可以直接看:
 机器学习常用性能指标及sklearn中的模型评估
机器学习常用性能指标及sklearn中的模型评估
里面包含了多标签分类的准确率、hamming_loss、F值等的计算方法。accuracy_score(y_true, y_pred)# 下面暂未测试能否在多标签中使用,precision_score用于多标签时好像要指定precision_score(y_true, y_pred)recall_score(y_true, y_pred)fbeta_score(y_true, y_pred)fbeta_score(y_true, y_pred, beta=0.5)fbeta_score(y_true, y_pred, beta=2)
在机器学习中,性能指标(Metrics)是衡量一个模型好坏的关键,通过衡量模型输出
y_predict和y_true之间的某种”距离”得出的。
性能指标往往是我们做模型时的最终目标,如准确率,召回率,敏感度等等,但是性能指标常常因为不可微分,无法作为优化的loss函数,因此采用如cross-entropy, rmse等“距离”可微函数作为优化目标,以期待在loss函数降低的时候,能够提高性能指标。而最终目标的性能指标则作为模型训练过程中,作为验证集做决定(early stoping或model selection)的主要依据,与训练结束后评估本次训练出的模型好坏的重要标准。
在机器学习的比赛中,有部分比赛也是用metrics作为排名的依据(当然也有使用loss排名)。在二元分类中,术语“positive”和“negative”指的是分类器的预测类别(expectation),术语“true”和“false”则指的是预测是否正确(有时也称为:观察observation) T/F表示预测是否正确,P/N表示 预测的label而不是实际的label
roc_curve(y_pred,y_score,pos-label)中的第二个参数为
y_score:为模型预测样本为 Positive 的概率,类型为一维的 ndarray 或者 list
pos_label:用什么值表示 Positive ,默认为 1。 按照师兄的建议,计算【预测成功的标签占总标签的比例】:
按照师兄的建议,计算【预测成功的标签占总标签的比例】:
这样计算有个问题,就是如果标签是全0的情况,无论怎么算,这时候的
还有个问题,如果同为0也算预测成功,那么因为属性比较稀疏,准确率也不够可靠 下面的coverage的计算是根据,仅算预测1成功的覆盖率;coverage2是计算了预测为1或0的覆盖率。但如果标记全0的图片较多,准确率是否可靠?
下面的coverage的计算是根据,仅算预测1成功的覆盖率;coverage2是计算了预测为1或0的覆盖率。但如果标记全0的图片较多,准确率是否可靠?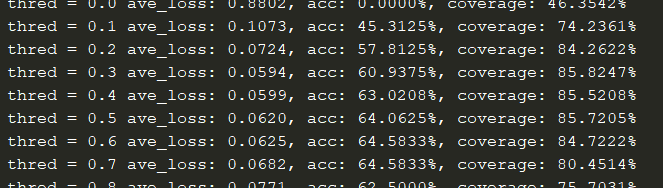
dipin是二分类(最后一个类别标签单独拿出来算准确率):这是改良了数据集后的结果。去掉了一些结尾为\n即全0但不是nc开头的图片(即医生说这部分图像不容易标注)。可以看出,阈值取0.5或0.5皆可。

- arrange和range
使用arrange需要引入numpy,arrange支持小数步长。 - 统计numpy数组中每个值出现的个数:
sum(data==4) any() 函数用于判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。
元素除了是 0、空、FALSE 外都算 TRUE。any(iterable)
all(x)如果all(x)参数x对象的所有元素不为0、’’、False或者x为空对象,则返回True,否则返回False
- python中的
type(),dtype(),astype()区别type():返回数据结构类型(list、dict、numpy.ndarray 等)dtype():返回数据元素的数据类型(int、float等)
备注:1)由于 list、dict 等可以包含不同的数据类型,因此不可调用dtype()函数
2)np.array 中要求所有元素属于同一数据类型,因此可调用dtype()函数astype():改变np.array中所有数据元素的数据类型。
备注:能用dtype() 才能用 astype() ndarray索引和切片(注意如果为python list,要先通过
np.array(list)转化为numpy array
numpy知识点复习和总结大全
Python列表的索引和切片操作在ndarray上仍然适用。但是要注意ndarray的切片返回的是数组的视图而非副本,如果你想要获得副本,这需要显式的调用copy()方法。
在numpy里,所有维度的索引可以写在一个中括号内,并且用逗号隔开(分别写在多个中括号也是可以的,这种写法和Python列表索引的写法相同)。# 选取除最后一列的其他元素array[:,:-1]
ndarray还有着特殊的索引方式,分布是布尔型索引 和花式索引。
布尔型索引就是在中括号内放入布尔型数组,数组会根据布尔型数组的真值来选择数据# 在索引里加入布尔表达式,可以生成与原数组形状相同的布尔型数组array > 3array[array > 3]
花式索引 就是把一个指定顺序的整数顺序的列表或者ndarray数组放入中括号内,就可以按照特定顺序选取子集例如我想选第0列和第2列的全部元素,那么就可以向下面那样进行索引。
array[:,[0,2]]# 或者我想先选取第2列再选取第0列,只须修改列表里元素的顺序即可。array[:,[2,0]]
numpy索引的方法有很多,但是各种索引方式之间的效率和空间是不一样的。例如我们现在有一个比较大的数组,我们打算每隔10个行选取1行,则可以有以下两种方式。 ```python arr1 = np.random.random_sample([10000, 1000]) arr1_id = id(arr1) range_arr = np.arange(0, 100000, 10)
%timeit arr1[::10] %timeit arr1[range_arr]
- lower()方法是Python字符串方法。它将字符串中的所有大写字母转换为小写字母,并返回一个新字符串。- list添加元素:```pythonlst.append(elem) # 向尾部插入lst.insert(index, elem) # 向指定位置插入new_list = list1 + list2 # 用符号+连接两个list,此时会创建一个新list
- 判断数组中是否含有某值或全为某值 ```python import numpy as np
a = [1, 1, 2]
先转化为numpy.ndarray
arr = np.array(a)
是否全部为1,False
print((arr == 1).all())
也可以
np.all(arr == 1)
是否含有1,True
print((arr == 1).any())
- python set集合运算:```pythonx & y # 交集x | y # 并集x - y # 差集
pytorch对网络的fine-tune大概分为三种:pytorch实现不同网络层分配不同的学习率
1、预训练模型的参数比较适合我们的数据集,我们只需要对新添加的网络层进行训练即可;这时候可以通过pytorch将预训练模型的梯度冻结,训练过程中不在向预训练模型传递梯度信息,梯度只在新添加的网络层有效。pre_model = ResNet.resnet50(True, './pretrained_model/')'''首先,我们必须冻结预训练过的层,因此在训练期间它们不会进行反向传播。然后,我们重新定义最后的全连接层,即使用我们的图像来训练的图层。'''for param in pre_model.parameters():param.requires_grad = False # 冻结预训练模型的各层,不对原模型进行反向传播训练
2、预训练模型的数据集和我们的数据集比较相近,并且我们数据集的规模也不算小,此时我们一般会给预训练模型和我们新添加的网络层分配不同大小的学习率(预训练模型的学习率会相对较小)。这样我们就能让预训练模型更适合我们的数据集。
3、当我们的数据集和预训练模型的数据集差别较大并且我们的数据集规模较大的时候,我们可以将预训练模型的参数当做我们模型的初始化参数,然后进行端到端的训练即可optimizer.step()和scheduler.step()
optimizer.step()通常用在每个mini-batch之中,而scheduler.step()通常用在epoch里面,但是不绝对,可以根据具体的需求来做。只有用了optimizer.step(),模型才会更新,而scheduler.step()是对lr进行调整。通常我们有optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum = 0.9)scheduler = lr_scheduler.StepLR(optimizer, step_size = 100, gamma = 0.1)model = net.train(model, loss_function, optimizer, scheduler, num_epochs = 100)
在scheduler的step_size表示scheduler.step()每调用step_size次,对应的学习率就会按照策略调整一次。所以如果scheduler.step()是放在mini-batch里面,那么step_size指的是经过这么多次迭代,学习率改变一次。
- pytorch加载预训练模型中的部分参数
- .named_parameters()和.parameters()
model.parameters:返回模型所有参数的迭代器
named_parameters: 返回一个iterator,每次它会提供包含参数名的元组。 python中的函数:
可变参数的使用方法是在参数列表前加(函数定义时),参数会以元组的形式存储在 args
我们还可以通过在前面增加**的方式来保存为字典参数(函数定义时),这时函数调用时就需要用arg1=value1,arg2=value2的形式。
传入实参的时候,加上号,可以将列表中的元素拆成一个个的元素。(函数调用时)def PrintNum(**args, **kwargs):print('args:{}'.format(args))print('kwargs:{}'.foramt(kwargs))PrintNum(*[1,2,3],x=1,y=2)>> args:(1, 2, 3)>> kwargs:{'x': 1, 'y': 2}PrintNum(1, 2, 3) 和 PrintNum(*[1,2,3])等价>> args:(1, 2, 3)PrintNUm([1,2,3])>> args:[1, 2, 3]
举一个采用**kwargs传递参数的使用场景: ```python import mysql.connector
db_conf = { user=’xx’, password=’yy’, host=’xxx.xxx.xxx.xxx’, database=’zz’ }
cnx = mysql.connector.connect(**db_conf)
- 函数传引用:<br />在python中,参数是没有类型的,可以传递任何类型的对象作为参数,但是不同类型的参数在函数中的修改,表现也是不一样的。- 不可变对象 : 数值、字符串、元组等- 可变对象 : 列表、字典等```pythonnum = 1list1 = [1]def change_data(num,list1):num*2list1.extend([2,3])num #num的值没有改变,因为num是不可变类型>> 1list1 #list1的值发生改变,因为list1是列表,是可变对象>> [1,2,3]
变量的作用域,除非是全局变量(global),否则函数里变量改变不影响函数外面变量的值。注意与上面对比。
num = 1list1 = [1]def change_data(num,list1):num = 2 #这里num是函数内部的局部变量list1 = [1,2,3]#这里list1是函数内部的局部变量,所以list1改变不改变外部变量的值num>> 1list1>> [1]
个人总结,在函数里面改变变量与改变变量的值的不同。改变变量(比如赋值),不影响外面变量的值;如果改变了变量的值,比如list.append()等在变量上面作的改变,会影响外面变量的值。
python 全局变量
在函数内部修改全局变量的值,要先用global声明全局变量,若不用global声明就改值,对全局变量不起作用,只是作为局部变量使用。
在函数内部可直接引用全局变量的值,而不必声明。temp = 0def get_temp():global temptemp = 33def print_temp():print(temp)get_temp()print_temp()
列表、字典 在函数中不用加global,也可以用作全局变量
t = [1,2,3]def add_t():t.append(4)
zip()函数:函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
>>>a = [1,2,3]>>> b = [4,5,6]>>> c = [4,5,6,7,8]>>> zipped = zip(a,b) # 打包为元组的列表[(1, 4), (2, 5), (3, 6)]>>> zip(a,c) # 元素个数与最短的列表一致[(1, 4), (2, 5), (3, 6)]>>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式[(1, 2, 3), (4, 5, 6)]
zip 方法在 Python 2 和 Python 3 中的不同:在 Python 3.x 中为了减少内存,zip() 返回的是一个对象。如需展示列表,需手动 list() 转换。
- argparse详解
基本用法 - 如果在python的类中定义了
__call__方法,那么实例对象也将变成一种可调用对象。 - list之间用加号,代表列表合并,产生的是个新的对象
list之前加星号,代表将列表解压,即看成一个个元素。
比如vgg创建特征层时layer = []conv2d = nn.Conv2d(in_channels, 64, kernel_size=3, padding=1)layers += [conv2d, nn.ReLU(inplace=True)]return nn.Sequential(*layers)
os.path.basename()
返回path最后的文件名。如果path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素。- python txt文件读取写入字典的方法
```python
1.使用json转换
js = json.dumps(dic) file = open(‘test.txt’, ‘w’) file.write(js) file.close()
file = open(‘test.txt’, ‘r’) js = file.read() dic = json.loads(js) print(dic) file.close()
2.使用str转换
fw = open(“test.txt”,’w+’) fw.write(str(dic)) #把字典转化为str fw.close()
fr = open(“test.txt”,’r+’) dic = eval(fr.read()) #读取的str转换为字典 print(dic) fr.close()
- 注意,字典中如果含有ndarray类型,是不能序列化的,要转成列表。- pytorch查看模型每层的输出```python# pip install torchsummaryfrom torchsummary import summarysummary(model, (3, 227, 227)) # 第二个参数即输入的维度
# 结果如下 -1代表batch_size----------------------------------------------------------------Layer (type) Output Shape Param #================================================================Conv2d-1 [-1, 64, 56, 56] 23,296ReLU-2 [-1, 64, 56, 56] 0MaxPool2d-3 [-1, 64, 27, 27] 0Conv2d-4 [-1, 192, 27, 27] 307,392ReLU-5 [-1, 192, 27, 27] 0MaxPool2d-6 [-1, 192, 13, 13] 0Conv2d-7 [-1, 384, 13, 13] 663,936ReLU-8 [-1, 384, 13, 13] 0Conv2d-9 [-1, 256, 13, 13] 884,992ReLU-10 [-1, 256, 13, 13] 0Conv2d-11 [-1, 256, 13, 13] 590,080ReLU-12 [-1, 256, 13, 13] 0MaxPool2d-13 [-1, 256, 6, 6] 0AdaptiveAvgPool2d-14 [-1, 256, 6, 6] 0Dropout-15 [-1, 9216] 0Linear-16 [-1, 4096] 37,752,832ReLU-17 [-1, 4096] 0Dropout-18 [-1, 4096] 0Linear-19 [-1, 9] 36,873Dropout-20 [-1, 9216] 0Linear-21 [-1, 4096] 37,752,832ReLU-22 [-1, 4096] 0Dropout-23 [-1, 4096] 0Linear-24 [-1, 1] 4,097================================================================Total params: 78,016,330Trainable params: 78,016,330Non-trainable params: 0----------------------------------------------------------------Input size (MB): 0.59Forward/backward pass size (MB): 8.58Params size (MB): 297.61Estimated Total Size (MB): 306.78
torch.flatten(input, start_dim=0, end_dim=-1)
input: 一个 tensor,即要被“推平”的 tensor。
start_dim: “推平”的起始维度。
end_dim: “推平”的结束维度。
首先如果按照 start_dim 和 end_dim 的默认值,那么这个函数会把 input 推平成一个 shape 为 [n]的tensor,其中 nn 即 input 中元素个数。
当 start_dim = 1 而 end_dim = −1 时,它把第 1 个维度到最后一个维度全部推平合并了。而当 start_dim = 0 而 end_dim = 1 时,它把第 0 个维度到第 1 个维度全部推平合并了。- pytorch网络结构和损失的可视化可以用tensorboard
TOREAD: https://zhuanlan.zhihu.com/p/60753993 torch.cat()C = torch.cat( (A,B), 0) #按维数0拼接(竖着拼)C = torch.cat( (A,B), 1) #按维数1拼接(横着拼)
pytorch张量相加的四种方法:
x = torch.rand(5, 3)y = torch.rand(5, 3)#第一种print(x + y)#第二种print(torch.add(x, y))#第三种result = torch.empty(5, 3)torch.add(x, y, out=result)print(result)#第四种y.add_(x)print(y)
查看预训练模型的参数:
path = 'I:/迅雷下载/alexnet-owt-4df8aa71.pth'pretrained_dict = torch.load(path)for k, v in pretrained_dict.items(): # k 参数名 v 对应参数值print(k)
加载预训练模型的部分参数
statedict的数据类型是OrderedDict,可以按照dict的操作方法操作。
只要构建一个字典,使得字典的keys和我们自己创建的网络相同,我们在从各种预训练网络把想要的参数对着新的keys填进去就可以有一个新的statedict了,这样我们就可以load这个新的state_dict,这是最普适的方法适用于所有的网络变化。 ```python net = Net()我的电脑没有GPU,他的参数是GPU训练的cudatensor,于是要下面这样转换一下
dict_trained = torch.load(“mobilenet_sgd_rmsprop_69.526.tar”,map_location=lambda storage, loc: storage)[“state_dict”] dict_new = net.state_dict().copy()
new_list = list (net.state_dict().keys() ) trained_list = list (dict_trained.keys() ) for i in range(65): dict_new[ new_list[i] ] = dict_trained[ trained_list[i]]
- 冻结模型参数```python# we want to freeze the fc2 layer this time: only train fc1 and fc3net.fc2.weight.requires_grad = Falsenet.fc2.bias.requires_grad = False# passing only those parameters that explicitly requires gradoptimizer = optim.Adam(filter(lambda p: p.requires_grad, net.parameters()), lr=0.1)# then do the normal execution of loss calculation and backward propagation# unfreezing the fc2 layer for extra tuning if needednet.fc2.weight.requires_grad = Truenet.fc2.bias.requires_grad = True# add the unfrozen fc2 weight to the current optimizeroptimizer.add_param_group({'params': net.fc2.parameters()})
# 以restnet为例 This freezes layers 1-6 in the total 10 layers of Resnet50.model_ft = models.resnet50(pretrained=True)ct = 0for child in model_ft.children():ct += 1if ct < 7:for param in child.parameters():param.requires_grad = False
- python中map, filter, reduce的使用,可以替代for循环,更清晰。
Map:对每个项应用相同的步骤集,存储结果
Filter:应用验证条件,存储计算结果为 True 的项
Reduce:返回一个从元素传递到元素的值
python中,三种技术作为函数存在,这意味着要编写map(function, my_list)
lambda表达式仅限于返回单个表达式,因此如果使用map、filter或reduce时需要对每个项执行多个操作,应该先定义函数,然后再包含它。
lambda 表达式是所有三个函数中的第一个参数,iterable 是第二个参数
reduce()的 lambda 表达式需要两个参数:累加器(传递给每个元素的值)和单个元素本身 如果载入模型中,所有参数都需要更新,然而要求一些参数和另一些参数的更新速度(学习率)不一样,最好知道这些参数的名称都有什么
# 载入预训练模型参数后...for name, value in model.named_parameters():print(name)# 或print(model.state_dict().keys())# 假设要求encode、viewer的学习率为1e-6, decoder的学习率为1e-4,那么在将参数传入优化器时:ignored_params = list(map(id, model.decoder.parameters()))base_params = filter(lambda p: id(p) not in ignored_params, model.parameters())optimizer = torch.optim.Adam([{'params':base_params,'lr':1e-6},{'params':model.decoder.parameters()}],lr=1e-4, momentum=0.9)
在传入optimizer时,和一般的传参方法torch.optim.Adam(model.parameters(), lr=xxx) 不同,参数部分用了一个list, list的每个元素有params和lr两个键值。如果没有 lr则应用Adam的lr属性。Adam的属性除了lr, 其他都是参数所共有的(比如momentum)。
- 预训练模型引用及修改(增减网络层,修改某层参数等)
1、仅全连接层类别数不同 ```pythoncoding=UTF-8
import torchvision.models as models
调用模型
model = models.resnet50(pretrained=True)
提取fc层中固定的参数
fc_features = model.fc.in_features
修改类别为9
model.fc = nn.Linear(fc_features, 9)
- 2、添加层后,加载部分参数<br />有的时候我们往往要修改网络中的层次结构,这时只能用参数覆盖的方法,即自己先定义一个类似的网络,再将预训练中的参数提取到自己的网络中来。这里以resnet预训练模型举例。```pythonmodel = ...model_dict = model.state_dict()# 1. filter out unnecessary keyspretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}# 2. overwrite entries in the existing state dictmodel_dict.update(pretrained_dict)# 3. load the new state dictmodel.load_state_dict(model_dict)
pytorch单机多卡训练(数据并行训练)
# 0.判断GPU是否可用device = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)# 1.将模型送入多GPUif torch.cuda.device_count() > 1:print(“Let’s use”, torch.cuda.device_count(), “GPUs!”)model = nn.DataParallel(model)model.to(device)# 2.将训练数据送入多GPUfor data in rand_loader:input = data.to(device)output = model(input)
pytorch Module.named_parameters()、Module.named_children()、与Module.named_modules()的区别
named_parameters()输出模型中每一个参数的名称(字符串)与这个参数(torch.nn.parameter.Parameter类);而named_modules()与named_children()则输出的是每一块模型的名称(字符串)与这个模型(Conv2d、Linear、Sequence或者是’__main.Net’类)。
其中modules与children又有区别:
modules会迭代式地找到每一个模型(例如或者是sequential的内部)
children则只会找到直接的子模型,不包含自己()或是孙子模型(sequential内部的)。
torch.nn.Conv2d、torch.nn.BatchNorm2d等等,都是torch.nn.Module类的子类- 在使用预训练模型的时候需要注意,我们在训练新数据时,需要把预训练模型中有的层设置小的learning rate,而自己增加的层设置稍微大一点的Lr。尽可能的保持原有分类性能并增加对新数据的泛化性能。

若有收获,就点个赞吧
0 人点赞
