https://zhuanlan.zhihu.com/p/356155277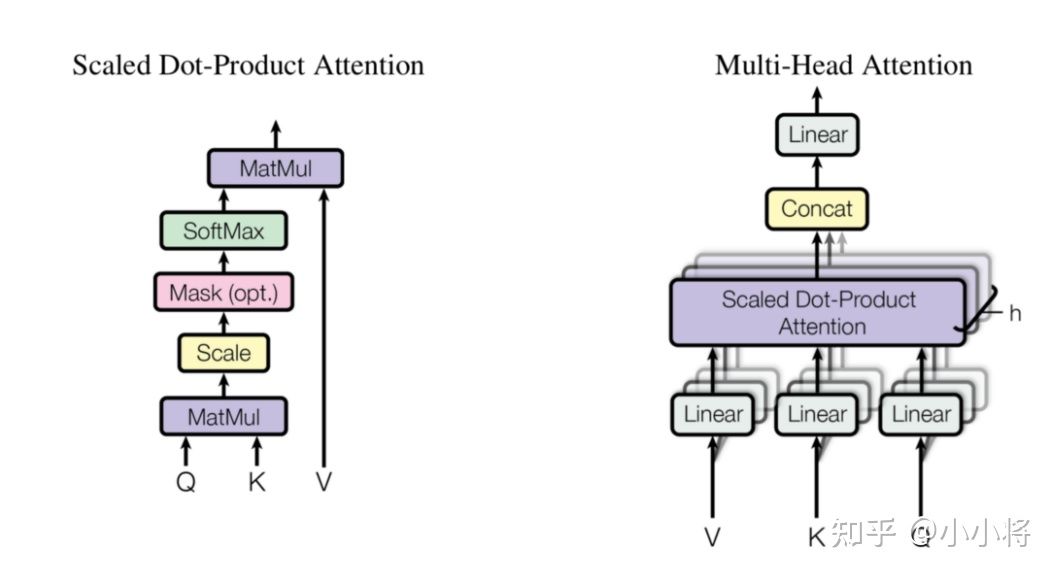
对于多头注意力
- 输入的X:(B, N(patch_num), C)
- N即类似于传统transoformer中的seqlen
(B, N, num_heads, C//num_heads)->(B, num_heads, N(patch_num), C//num_heads)
class Attention(nn.Module):def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)# 这里包含了dropoutself.proj_drop = nn.Dropout(proj_drop)def forward(self, x):B, N, C = x.shapeqkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj(x)x = self.proj_drop(x)return x
:::info
transformer encoder block:
1)就是提取图像的patch embeddings,然后和class token对应的embedding拼接在一起并加上positional embedding;
2)是MSA,多头注意力
3)是MLP,即FFN,两个fc层,先映射到高维,再映射回来
(2)和(3)共同组成了一个transformer encoder block,共有 层;
层;
4)是对class token对应的输出做layer norm,然后就可以用来图像分类。
:::
- 目前还没用到class token。
ViT
对于ViT模型来说,就类似CNN那样,不断堆积transformer encoder blocks,最后提取class token对应的特征用于图像分类,论文中也给出了模型的公式表达,其中(1)就是提取图像的patch embeddings,然后和class token对应的embedding拼接在一起并加上positional embedding;(2)是MSA,而(3)是MLP,(2)和(3)共同组成了一个transformer encoder block,共有层;(4)是对class token对应的输出做layer norm,然后就可以用来图像分类。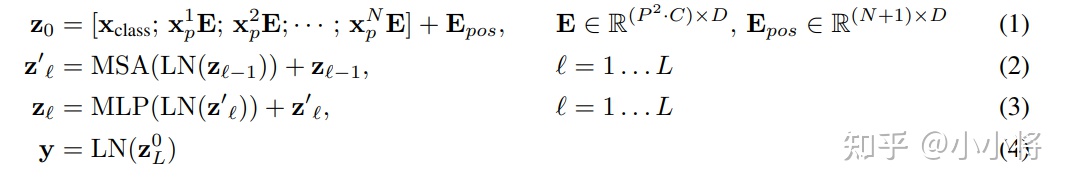
代码解析
代码详细解析Hybrid Architecture
单来说就是先用CNN对图像提取特征,从CNN提取的特征图中提取patch embeddings,CNN已经将图像降采样了,所以patch size可以为 。
。
问题
class tokens和pos_embedding的用处是什么?pos_embedding是对patch的空间位置信息进行编码。一方面是因为image切成若干patch后,丢失了空间位置信息;另一方面从NLP角度看,是因为transformer结构中没有类似RNN的循环结构来捕获“顺序序列”的能力,因此需要对空间位置信息进行显性建模。
FFN的用处?
FN 相当于将每个位置的Attention结果映射到一个更大维度的特征空间,然后使用GeLU引入非线性进行筛选,最后恢复回原始维度。
关于self-attention的理解?
关于self-attention的理解: 向量的内积可以理解为相似度,q的一行代表了其中的一个patch,k同理,二者相乘,代表了序列中两两patch之间的相似度.这其实类似与信息检索之中的query,key匹配过程,这个相似度就可以作为权重.而v初始化为q,k一样的形状,也可以看作代表了输入的每个patch的特征,为了让该特征具有更好的表征能力,每一个patch的特征都应该由其余所有patch(包括该patch自己加权而来,这里的权重即为q*k^T)
应用到C2F框架中的实现
query: (B, num_heads, N, C//num_heads)
- 3122048为ND,N=312,D=2048
- 其中D可以分为:16128或8256,即num_heads=16, dim_head=128
自注意力模块的输入是[b, 50, 128],输出的也是[b, 50, 128]
先对输入的x(x.shape=[b,50,128])做一个layerNormalization层归一化,然后再放到上面的Attention模块中做自注意力。
整个transformer流程
- 第一个就是,先对输入做layerNormalization,然后放到attention得到attention的结果,然后结果和做layerNormalization之前的输入相加做一个残差链接;
- 第二个就是,x->LayerNormalization->FeedForward线性层->y,然后这个y和输入的x相加,做残差连接。
Residual(PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout))),Residual(PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout)))
一个图片224x224,分成了49个32x32的patch;
- 对这么多的patch做embedding,成49个128向量;
- 再拼接一个cls_tokens,变成50个128向量;
- 再加上pos_embedding,还是50个128向量;
- 这些向量输入到transformer中进行自注意力的特征提取;
- 输出的是50个128向量,然后对这个50个求均值,变成一个128向量;
- 然后线性层把128维变成2维从而完成二分类任务的transformer模型。
- 因为要和属性去回归,目前head数量设为1,
- 如果head数量设为16,那么要在head的维度平均一下(或者取最大),才能继续去回归
- 要和属性去回归,则需要知道每张图像的att,原始代码中已知。
输入要是
[bs, 2048, 14, 14]的固定特征,输出应为[bs, 312, 2048]的自注意力后的特征,用来mixup。- 因此要写一个,加载模型,makedataset,
- 考虑到直接存为numpy后,在加载这些特征时,可能无法全部加载到内存,因此考虑在读batch时从硬盘加载。
- 或者每次直接用resnet提,但不训练resnet,只训练attention mask,最后存储
[bs, 312, 2048]。
- 因此要写一个,加载模型,makedataset,
先读取coarse模型,保存为
[bs,2048,14,14]的数据,然后读取这个,训练好attention mask后,送入fine分支去mixup,同时打印回归损失以及fine分支上的分类损失和精度。- 而attention mask训练的好坏只能用回归损失这个指标来评估。
- 存储为
[bs, 312, 2048]后,mixup后,avg pooling后送去分类,- mixup可能要占显存,会爆显存嘛?
06-24 已完成部分:
- part_mix_up_tool.py中的
Data_loader_Mixup_Feature。- 目前实现了大体的feature map的mixup流程,但还没实现如何部件之间的mixup。
- 目前仍是两个fea_map之间的mixup,而不是部件之间的mixup,即想要实现的是
312,2048每一个维度之间的mixup。- 本来两个样本mixup只产生一个样本,现在两个样本mixup,可以产生多个样本。
- tool.py中的
save_fea_map和make_fea_map_dataset- save_fea_map实现了测试集的保存,但速度很慢,大概10min?不知道是不是no_grad的问题

若有收获,就点个赞吧
0 人点赞
