【CV中的Attention机制】Non-Local Network的理解与实现
- 普通的滤波都是3×3的卷积核,然后在整个图片上进行移动,处理的是3×3局部的信息。Non-Local Means操作则是结合了一个比较大的搜索范围,并进行加权。
- 在Non-Local NN这篇文章中的Local也与以上有一定关系,主要是针对感受野来说的,一般的卷积的感受野都是3×3或5×5的大小,而使用Non-Local可以让感受野很大,而不是局限于一个局部领域。
- 与之前介绍的CBAM模块,SE模块,BAM模块,SK模块类似,Non-Local也是一个易于集成的模块,针对一个feature map进行信息的refine, 也是一种比较好的attention机制的实现。不过相比前几种attention模块,Non-Local中的attention拥有更多地理论支撑,稍微有点晦涩难懂。
通用公式表示

- f 函数式计算i和j的相似度
- g 函数计算feature map在j位置的表示
- x是输入信号,cv中使用的一般是feature map
- i 代表的是输出位置,如空间、时间或者时空的索引,他的响应应该对j进行枚举然后计算得到的
- 最终的y是通过响应因子C(x) 进行标准化处理以后得到的
理解:与Non local mean相比,就很容易理解,i 代表的是当前位置的响应,j 代表全局响应,通过加权得到一个非局部的响应值。
优点
- 提出的non-local operations通过计算任意两个位置之间的交互直接捕捉远程依赖,而不用局限于相邻点,其相当于构造了一个和特征图谱尺寸一样大的卷积核, 从而可以维持更多信息。
non-local可以作为一个组件,和其它网络结构结合,经过作者实验,证明了其可以应用于图像分类、目标检测、目标分割、姿态识别等视觉任务中,并且效果有不同程度的提升。
细节
g函数:可以看做一个线性转化(Linear Embedding)公式如下:

 是需要学习的权重矩阵,可以通过空间上的1×1卷积实现(实现起来比较简单)。
是需要学习的权重矩阵,可以通过空间上的1×1卷积实现(实现起来比较简单)。
- f函数:这是一个用于计算i和j相似度的函数,作者提出了四个具体的函数可以用作f函数。
- Embedded Gaussian:

- Gaussian function:

- Dot product:
- Concatenation:
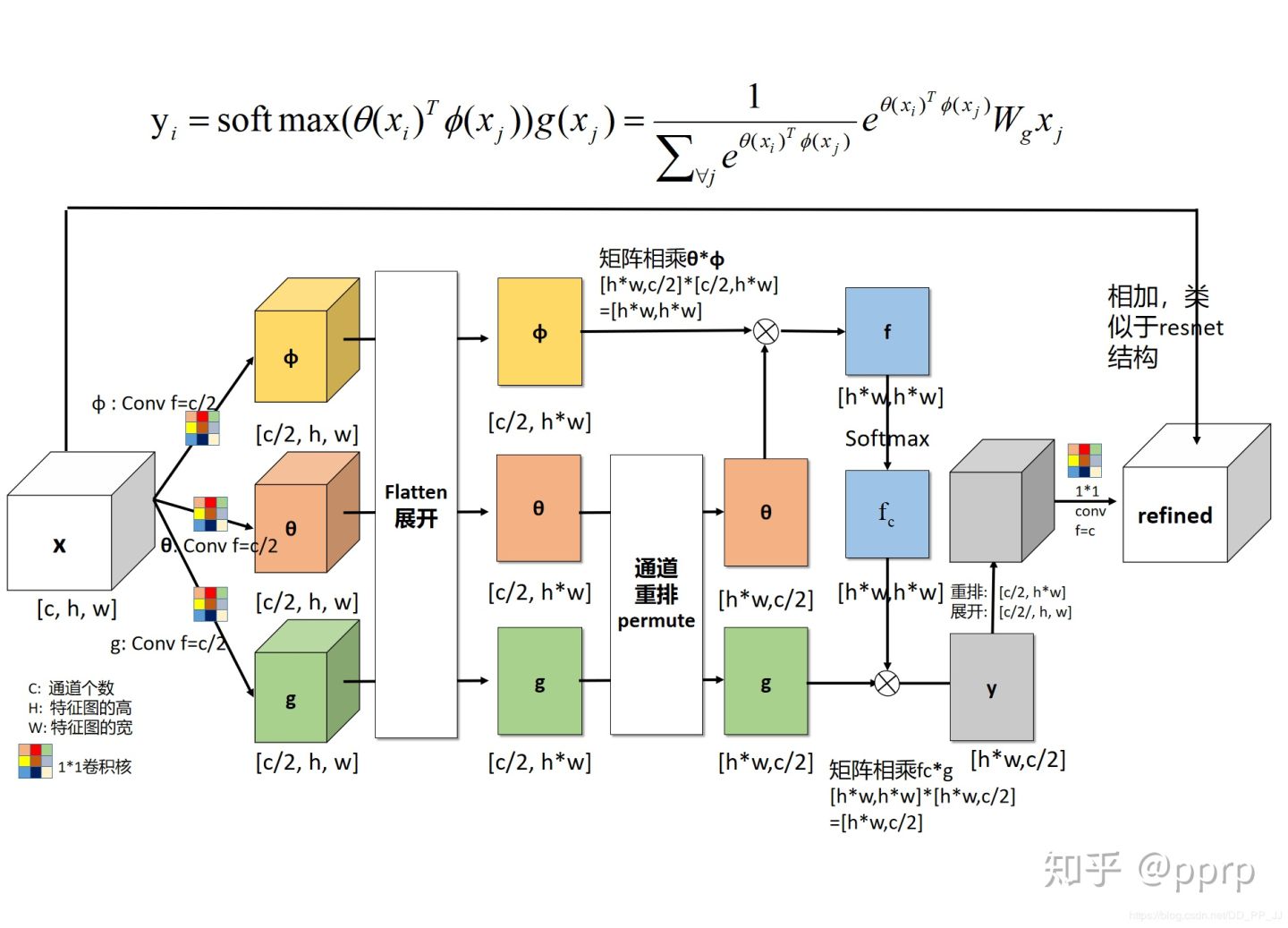 :::info
看着有点类似于self attention
:::
:::info
看着有点类似于self attention
:::
- x代表feature map, [公式]代表的是当前关注位置的信息; [公式]代表的是全局信息。
- θ代表的是
 ,实际操作是用一个1×1卷积进行学习的。
,实际操作是用一个1×1卷积进行学习的。 - φ代表的是
 ,实际操作是用一个1×1卷积进行学习的。
,实际操作是用一个1×1卷积进行学习的。 - g函数意义同上。
- C(x)代表的是归一化操作,在embedding gaussian中使用的是Sigmoid实现的。
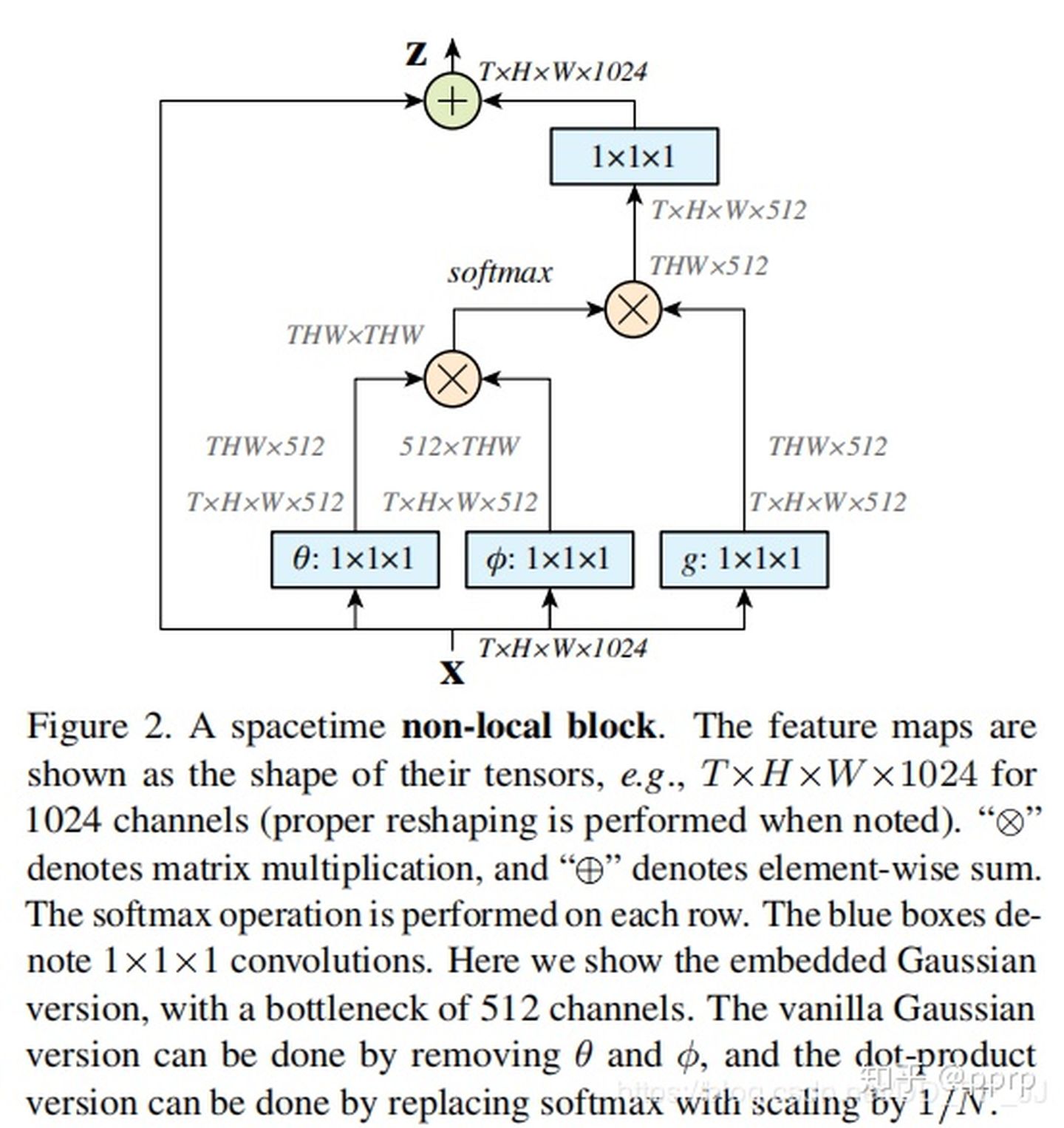
评价
- Non local NN从传统方法Non local means中获得灵感,然后接着在神经网络中应用了这个思想,直接融合了全局的信息,而不仅仅是通过堆叠多个卷积层获得较为全局的信息。这样可以为后边的层带来更为丰富的语义信息。

若有收获,就点个赞吧
0 人点赞
