13 生成模型VAE
有监督学习 vs 无监督学习

- PCA是线性降维,数据在某个维度上变化不大,就可以去除这个维度。
还有一种叫做特征学习,使用自编码器结构进行非线性降维,把输入图像通过比如神经网络映射到低维空间。
降维更多是为了可视化。
密度估计:有了密度估计,就能够产生样本。也是本章主要讲的内容。
生成模型
生成模型主要关注的就是密度估计问题。
给定训练集,产生与训练集同分布的新样本。
显示的密度估计:估计的分布的方程是能够定义出来的。可以看某个点的概率大小。 隐式的密度估计:只能生成样本,而不管模型长什么样。 生成的样本都是概率比较大的。
为什么研究生成模型

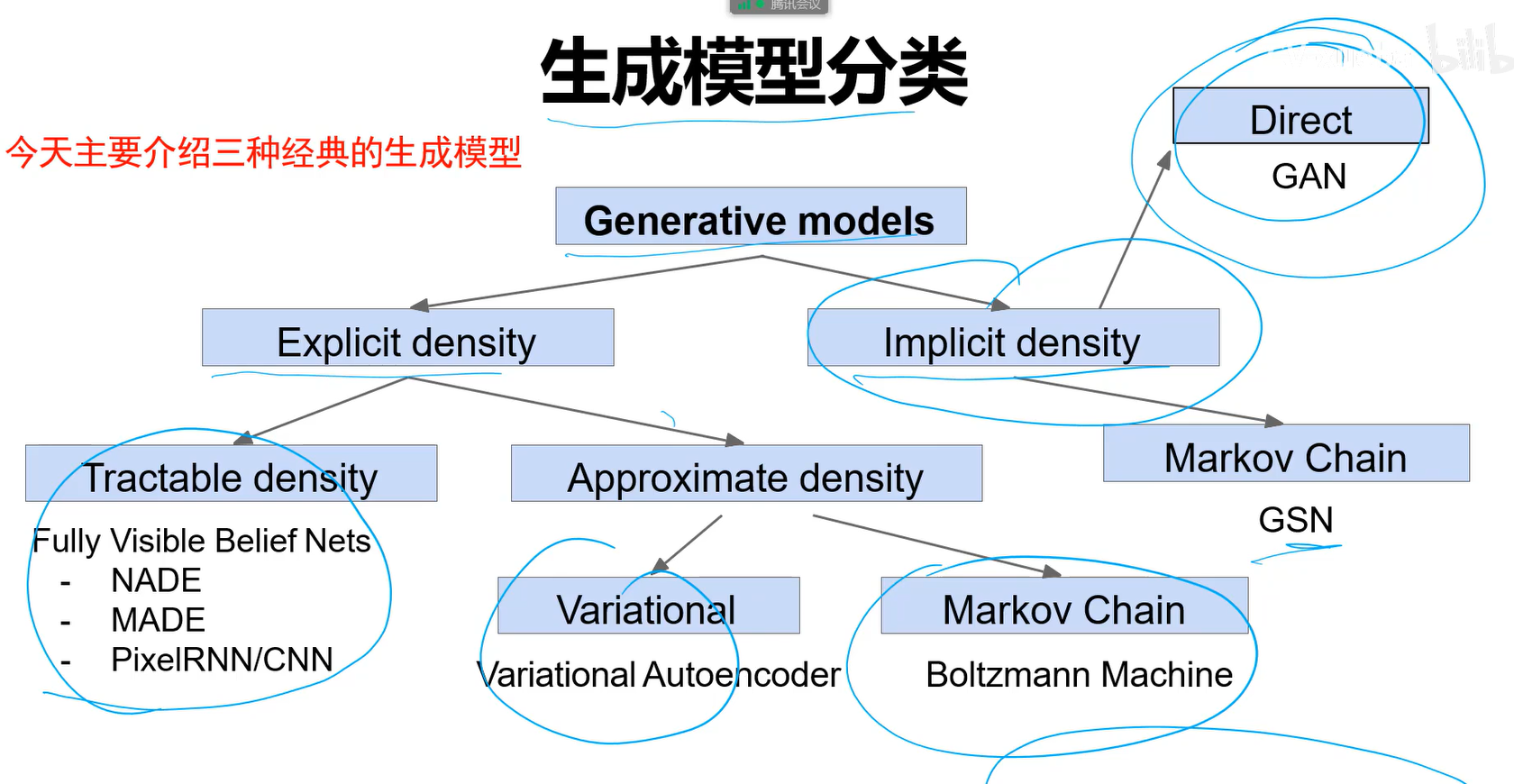
生成模型分类
PixelRNN与PixelCNN
显示的密度模型
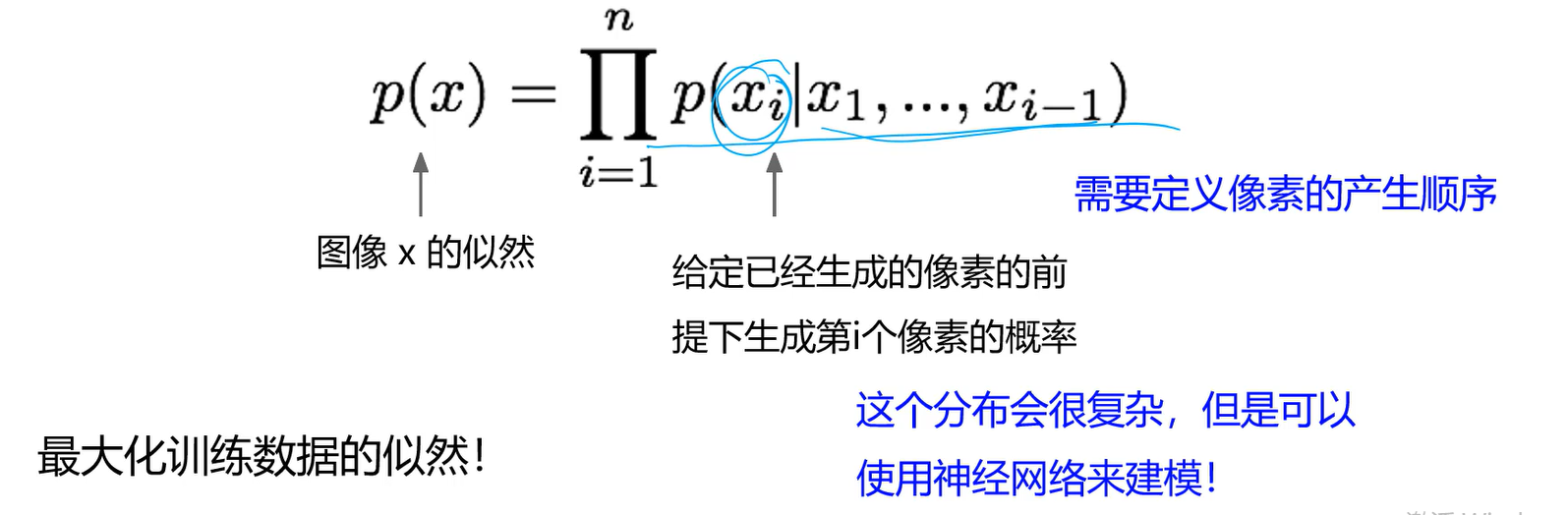
利用链式准则讲图像x的生成概率转变为每个像素生成概率的乘积。
学习过程就是最大化训练数据的似然!
似然:密度函数,找到一个模型,最能解释我现在产生的数据。即已经产生的这些数据,在这个模型下的概率应该是最高的。 最大化训练数据的似然就是极大似然估计:给我一个模型,通过让样本在模型发生的概率最大这种方式,来找模型的参数。 比如给我一堆男生的样本,只告诉我服从正态分布,不知道均值和方差。因此要找到模型的均值和方差,让模型最能解释现在拿到的男生样本。通过让模型最好地解释我的训练数据,就能求得模型参数。

训练过程也慢,测试过程也慢,因为学序列很慢,一点一点的生成,后来被改进成了PixelCNN。
PixelCNN
依然是从图像右上角开始产生像素。
基于已生成的像素,利用CNN来生成新的像素。
有了之前的像素之后,用256个卷积核进行卷积,看0-255那个值概率最大,然后填上。

PixelRNN与PixelCNN
- 优点:
- 似然函数可以精确计算。
- 利用似然函数的值可以有效评估模型性能。
- 缺点
- 序列产生=>慢
生成的效果也与最新的相差较远
- 序列产生=>慢
VAE 变分自编码模型
属于显式模型,概率密度函数可以显式定义,但求不出来,只能近似。
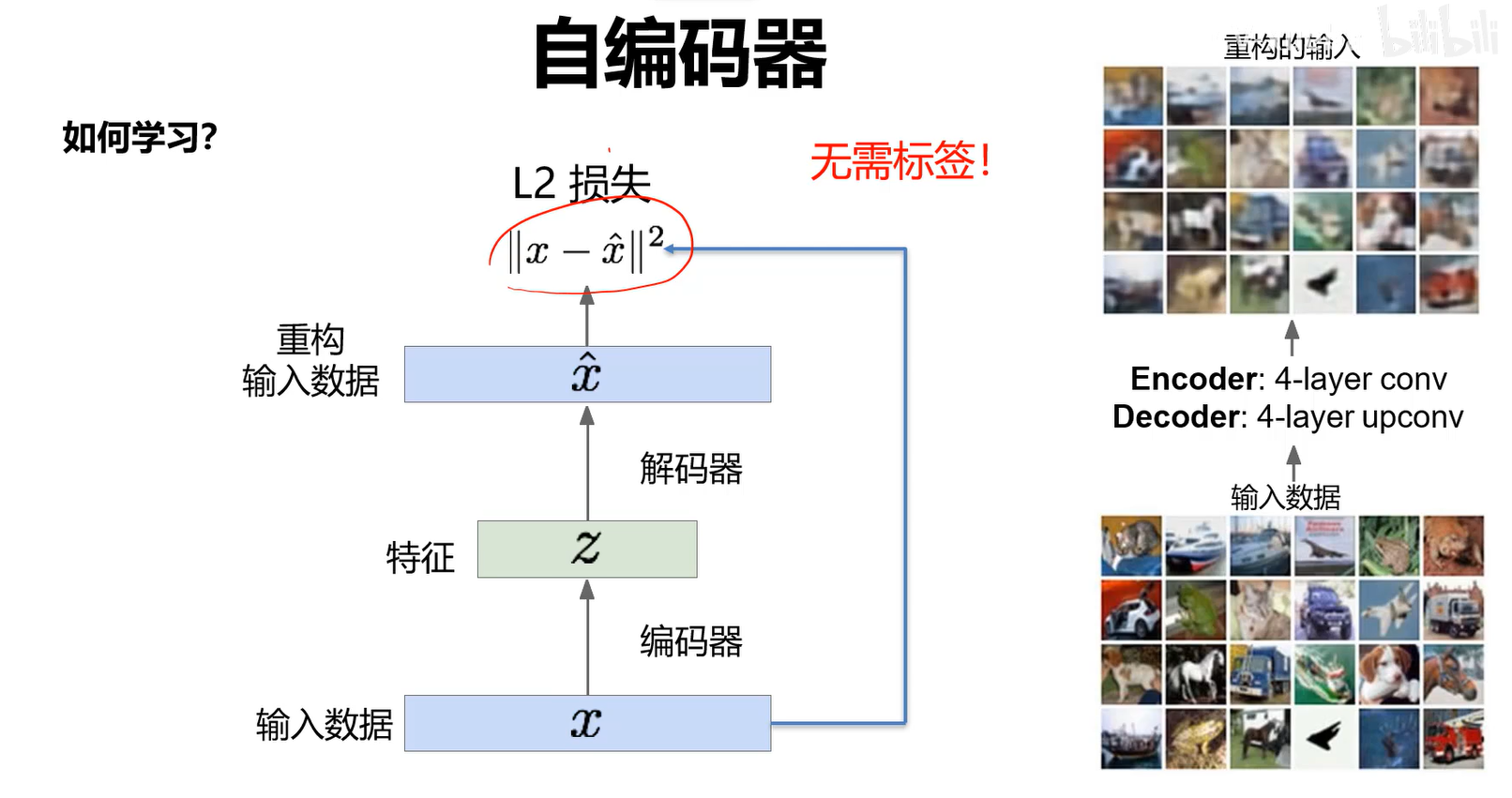
自编码器
无监督的特征学习,其目标是利用无标签数据找到一个有效地低维的特征提取器。
- 如何学习?需要一个解码器。
- 自编码利用重构损失来训练低维的特征表示。
- 希望输出图像和输入图像越接近越好。这样证明特征里面尽量包含了本质信息。
编码器:
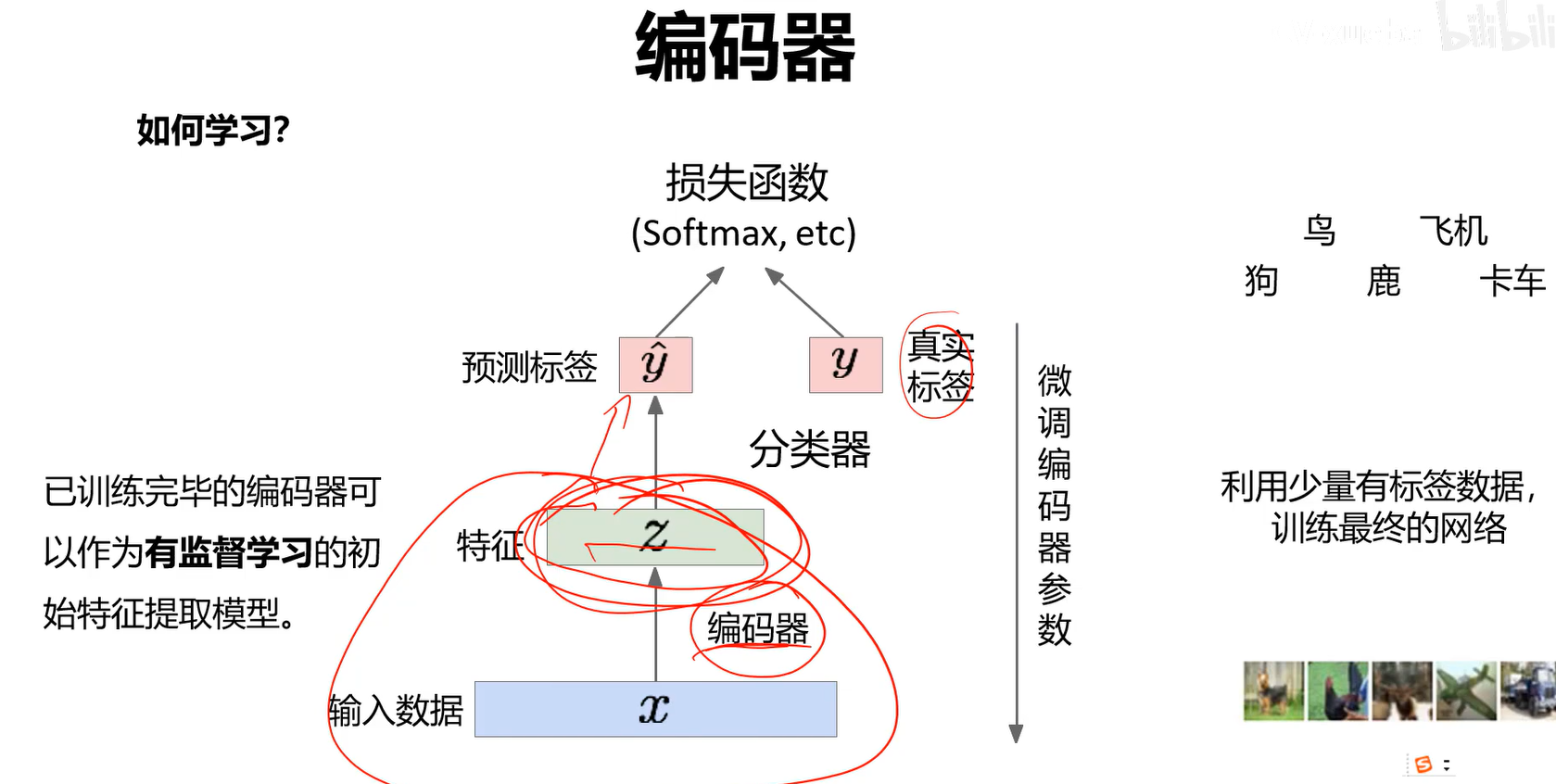
已训练完毕的编码器可以作为有监督学习的初始特征提取模型。
这种思路用的还是比较少的,因为少样本的情况下,在VGG基础上fine-tune效果更好。 另一个原因是,特征保留的时候并非奔着分类去的,即不是找对分类最有效的特征。
解码器
可以做图像生成。
给我码空间,在码空间采样一个编码,用这个编码就能生成图像了。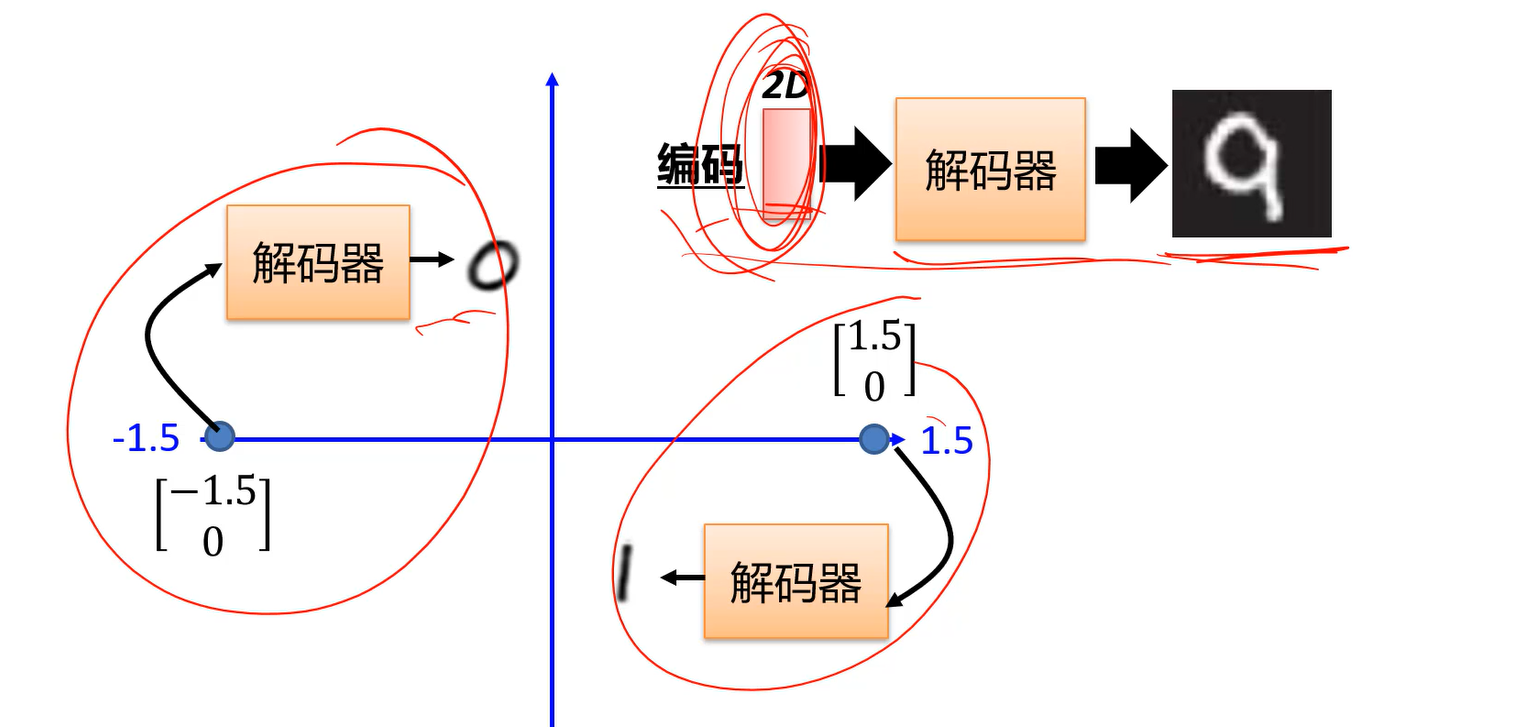
Why VAE?
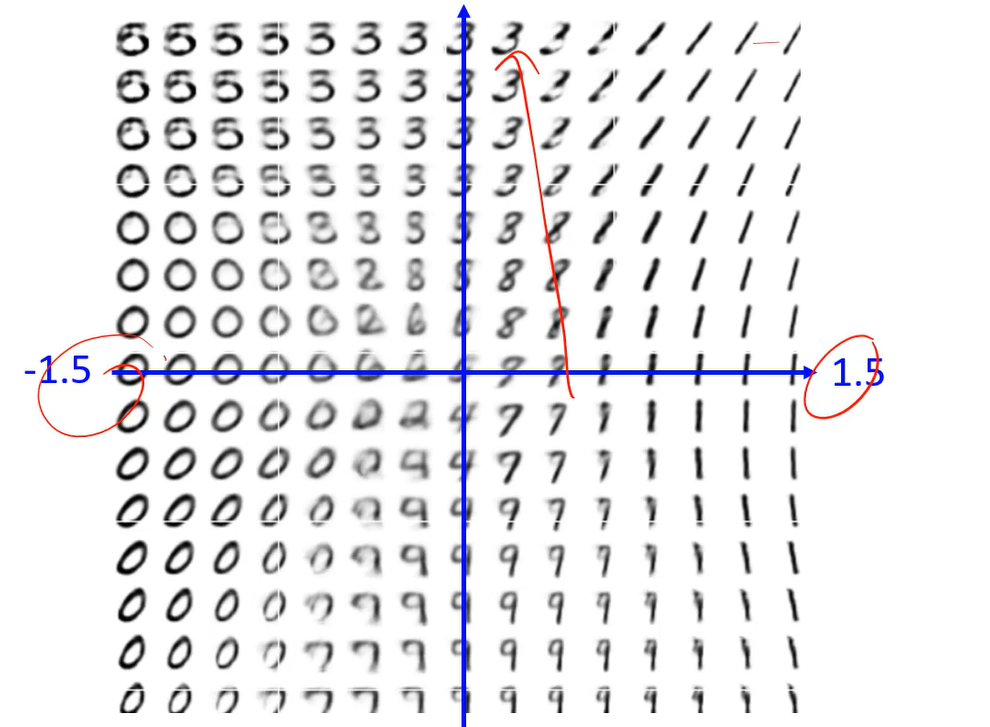
【半月】学到的z,再生成出来还是半月;【满月】学到的z,再生成出来还是满月;无法取两个z当中的一点生成个比如【四分之三月】。
因为当中的那个点没有数据,没有训练过,因此不会产生。
- 采样过程:
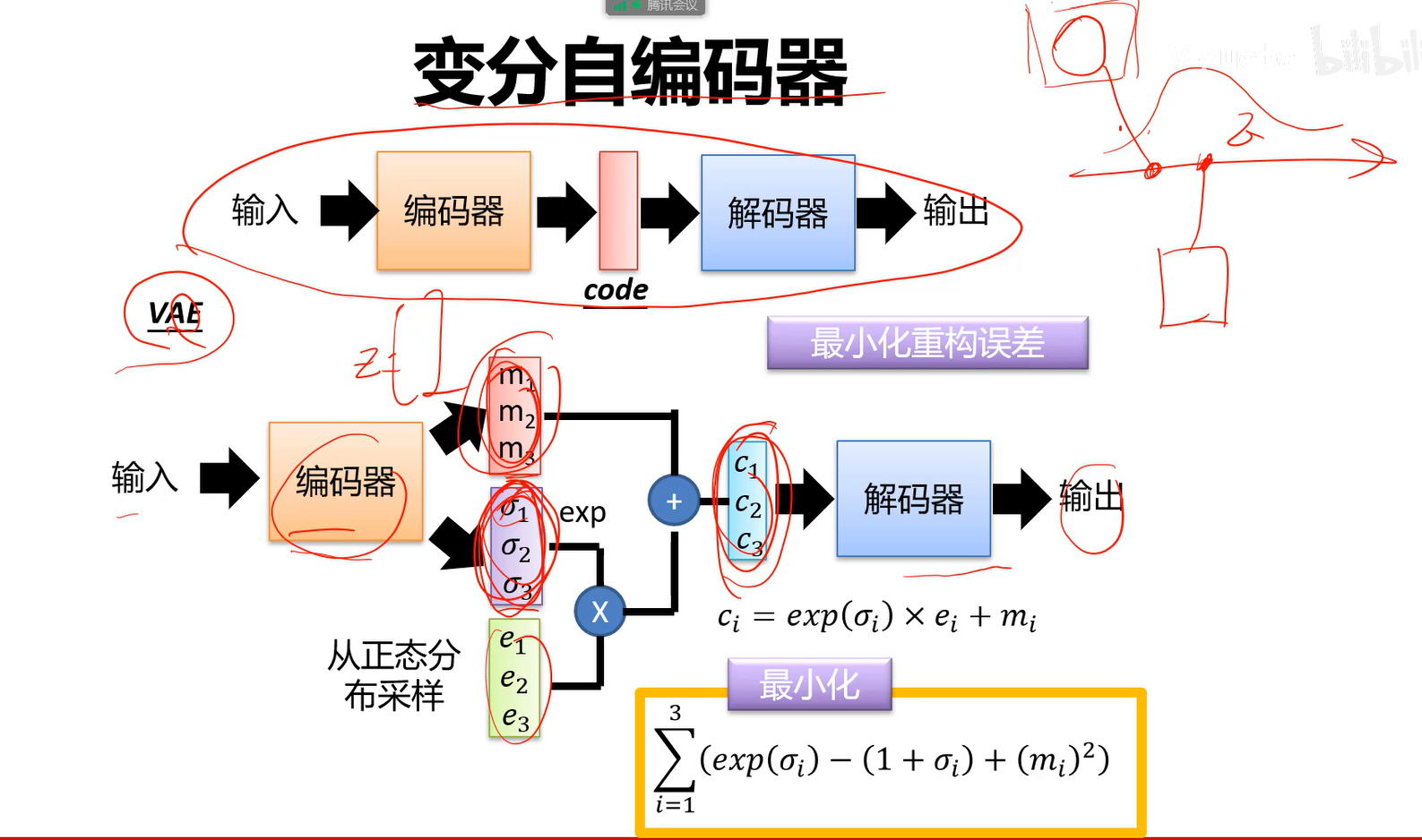
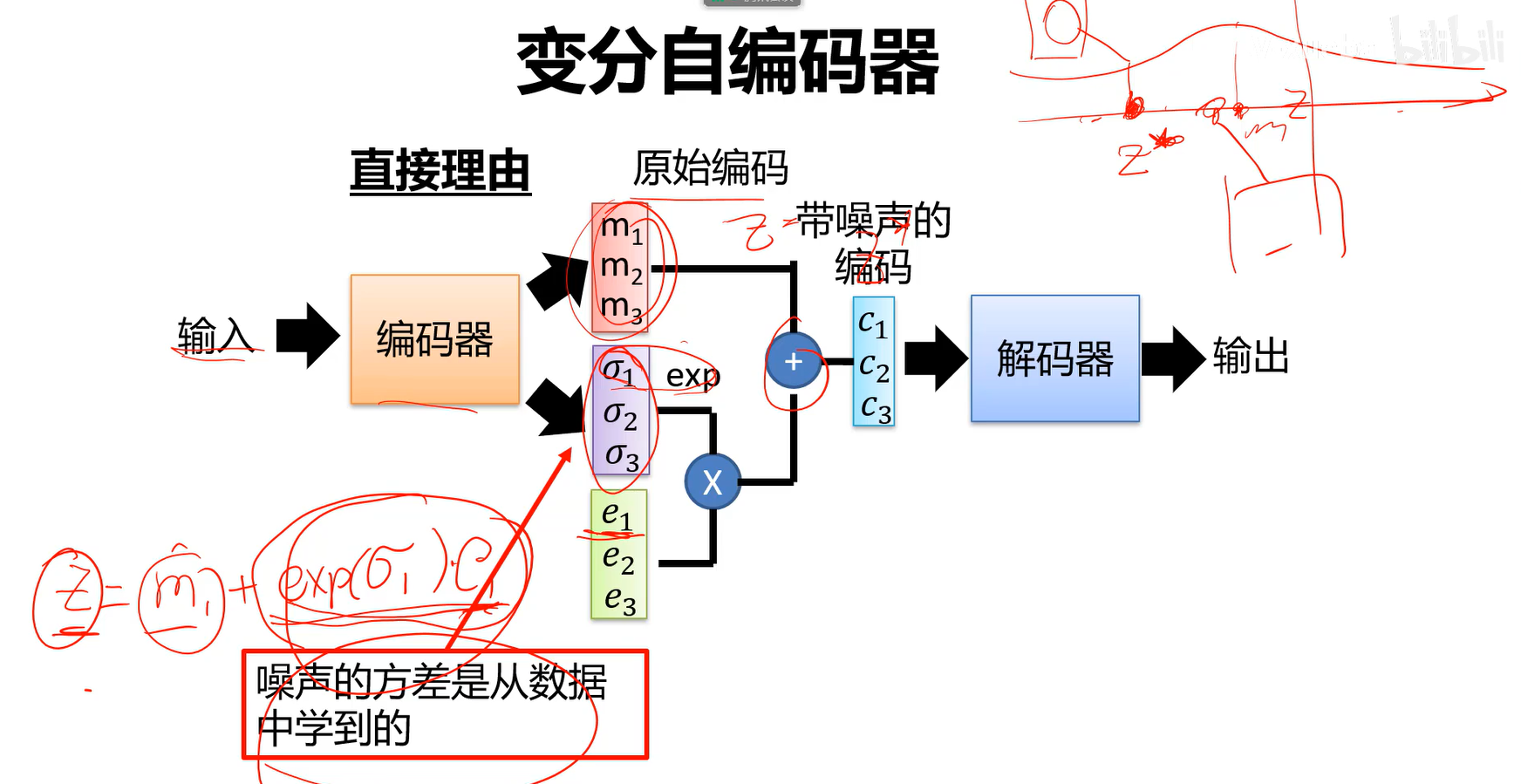
不再直接输出编码z,而是输出一个分布,m是均值,$\sigma$是标准差。采样的时候, (公式即均值+方差*噪声)因为数据会分布在方差范围内,因此相当于在方差范围内采样一个值,相当于原始的样本加上一个噪声得到z。
(公式即均值+方差*噪声)因为数据会分布在方差范围内,因此相当于在方差范围内采样一个值,相当于原始的样本加上一个噪声得到z。
并没有使用真正的z(这里指m),z(这里指m)只是一个中心,预测了一个分布,用这个预测出的分布来随机采样值进行生成。
Q:为何要取exp
A:因为标准差一定是正数,加了指数次方来保证是个正数。
Q:如果只有重构误差会如何?
A:如果只有重构误差,那么上图的第二个分支就不会被考虑,因为给我一张图,训练一个z,z再产生一张图,这就是AE做的事情。
- 因此又加了约束,最小化如下损失:

最小化前两项就要求 接近于0(
接近于0( ,采样的方差就接近于1);后一项相当于L2正则化,希望产生的z编码尽量分散,不要某个值特别大或特别小。
,采样的方差就接近于1);后一项相当于L2正则化,希望产生的z编码尽量分散,不要某个值特别大或特别小。
为什么希望方差趋近于1,下面会介绍。
- 有了上述知识,再谈为何VAE好用:
由于噪声的存在,满月指向的点附近好几个点都学过生成满月,由于正态分布,半月指向的点及附近的点也都学过生成半月。
因此会存在中间的点既学过生成半月也学过生成满月,如果从这个点采样,它既要满足满月的条件也要满足半月的条件才可能生成一个既不是满月又不是半月这样的月亮。没有VAE,这个地方无法学习,有了VAE,加了噪声学习后就变成可能。
这就是为何使用VAE,为何生成z分布然后从z分布中采样来生成图的原因。
VAE推导:(以及为何要使用第二个损失)
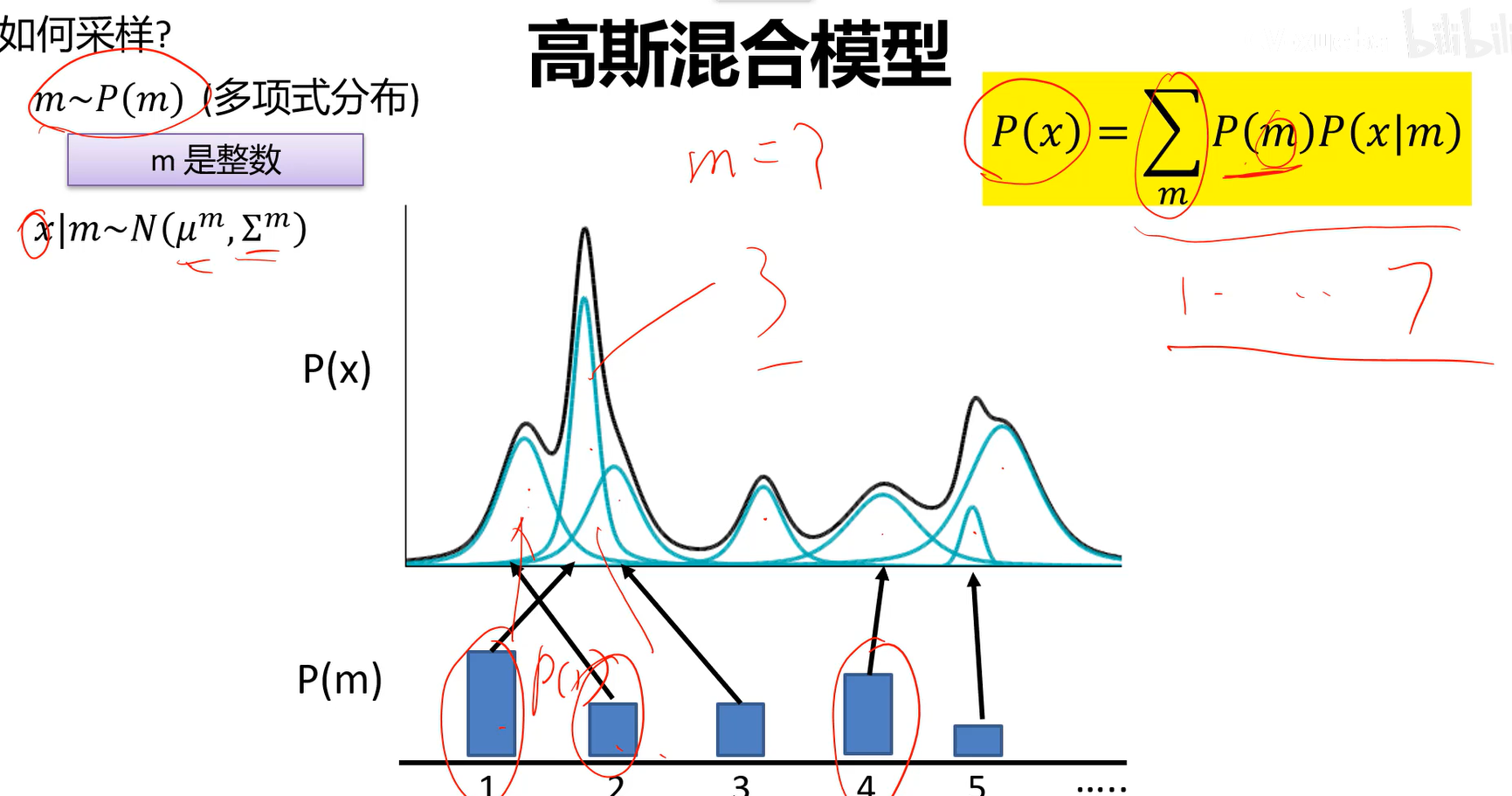
- 高斯混合模型:有时候样本并不符合正态分布。P(X)即图中黑线所示的分布,并不符合高斯分布,可以看成是很多高斯模型累加求和的结果。
- 采样过程:先从这个m个高斯组件里随便选一个高斯组件,再从这个高斯组件产生当前的样本。
P(m)为第m个高斯分布,P(x|m)代表从第m个高斯分布中采样x。
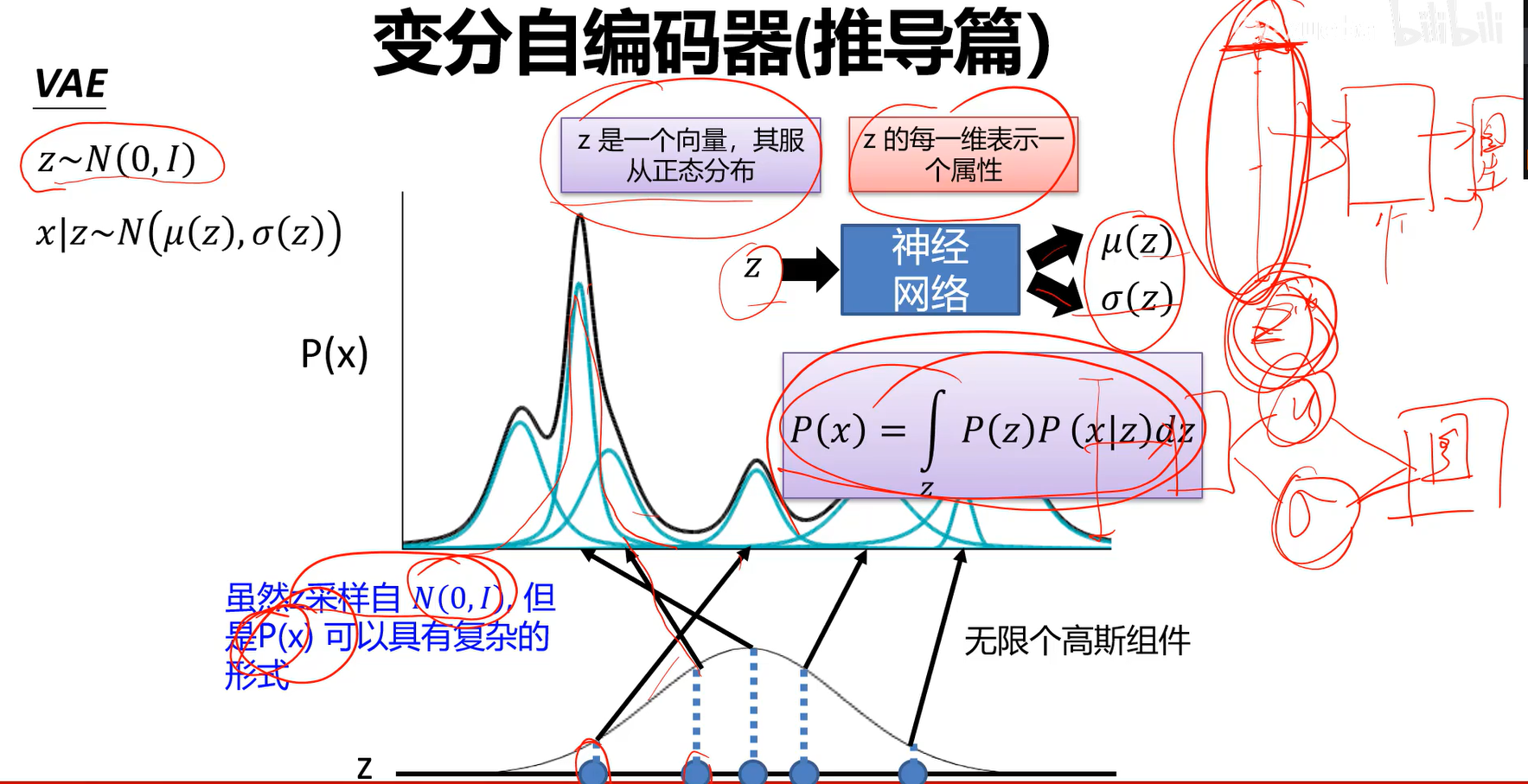
高斯混合模型只能解决有限高斯的混合问题。 高斯混合在我们这个任务里还不太够,到底要多少个高斯模型,太多了也不好弄,最好是用无限高斯,这件事情就可以交给神经网络来做。神经网络会去学习,给我一个z,学习出一个均值一个方差。
这里面的z我们通常选择0均值,1方差的。 这样的话,将来从z中采样一个z 出来,用z经过解码器产生图片,如果z是一个很复杂的分布,z*都不好采样,更不用说生成了。因此我们希望z尽可能地简单。
以下省略后续推导过程,较复杂。
- 下面为VAE真正应用的时候。
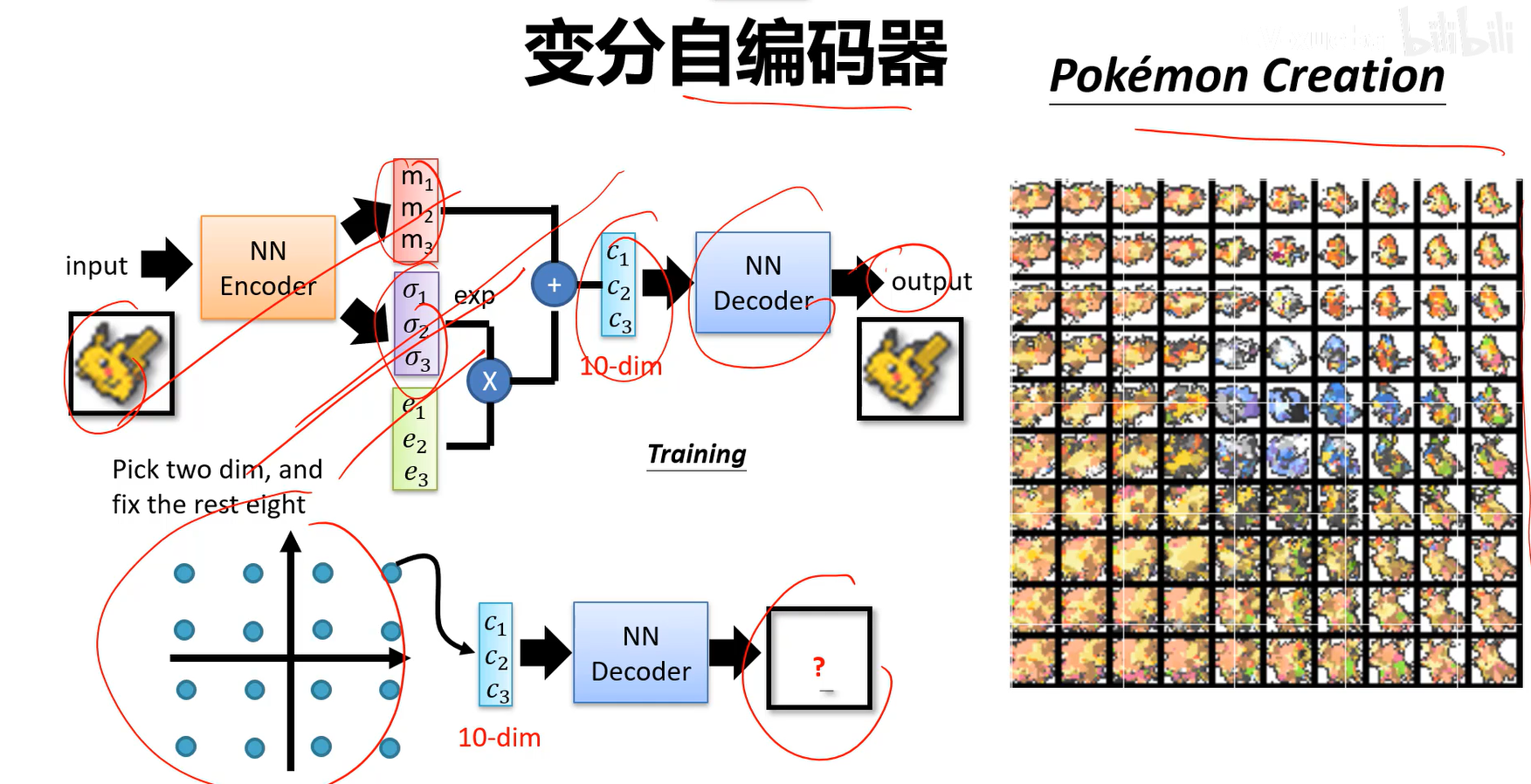

- 总结:


若有收获,就点个赞吧
0 人点赞
