[Sklearn应用] Preprocessing data(一) 标准化(Standardization) 与 正则化/归一化(Normalization) :::info 标准化针对的是把整列(特征)作为处理对象,而正则化把行(样本)作为处理对象,而且他们处理的公式方法也不同。 :::
标准化

- 标准化之后,每一列数据变成均值0,方差1的分布,但和并不一定为1。
标准化的作用:
- 使不同量纲的特征处于同一数值量级,减少方差大的特征的影响,使模型更准确。
- 加快学习算法的收敛速度。
比如sklearn.preprocessing下面的几个方法,就是对每一列计算的。 标准化:缩放到均值为0,方差为1(Standardization——StandardScaler())
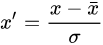 minmax归一化:缩放到0和1之间(Standardization——MinMaxScaler())
minmax归一化:缩放到0和1之间(Standardization——MinMaxScaler())
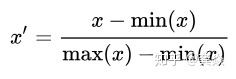 mean归一化:
mean归一化:

附,对图像进行标准化:
正则化之后,比如pytorch中的
F.normalize(x, p=2, dim=-1),对于二维的tensor,每一行的和都为1。 :::info 比如零样本学习中,预测时,计算映射到语义空间的图像嵌入和某个类别语义嵌入之间的相似度时,就可以用图像嵌入除以2范数,语义嵌入也除以2范数,然后将得到的两者做内积,即得到了两者的余弦距离。 :::img_fea = F.normalize(img_fea, p=2, dim=-1)att_fea = F.normalize(att_fea, p=2, dim=-1)


若有收获,就点个赞吧
0 人点赞
