参考来源:
CSDN:【Pytorch 学习笔记】8.训练类别不均衡数据时,如何使用 WeightedRandomSampler(权重采样器)
当我们平时处理类别不平衡数据(Imbalanced Data)时,比如当你有一个二分类数据集,其中 90% 的样本标为阳性,10% 的样本为阴性,如果直接拿给模型训练,然后你会发现模型的预测准确率 Accuracy 永远在某个不到 90% 的值左右浮动。
当然会这样,因为首先模型学习到的基本是阳性的特征,也就只会判断阳性准一点;其次,再给个还是 90% 阳性的验证集,模型全预测成阳性都会有九成的准确率。
关于类别不平衡数据的训练
对于类别不平衡数据,在训练模型和评估模型时都会有自己的方法。在评估模型时,我们常用混淆矩阵、F1-score、PR 曲线等,而不用准确率、ROC 曲线(关于 ROC、PR 曲线的区别可以看看我的这篇文章)。
本文则讨论训练不平衡数据时采用的方法。
为了让模型学习达到更好的效果,通常我们在会让模型在学习时将样本类别变成 1:1(二分类的情况)。
重采样(过采样、欠采样)
这就涉及到样本的重采样,主要分过采样和欠采样:
**过采样(over-sampling)**对小类的数据样本进行采样来增加小类的数据样本个数;**欠采样(under-sampling)**对大类的数据样本进行采样来减少该类数据样本的个数。
给一张图,很形象地解释了 over-sampling 和 under-sampling: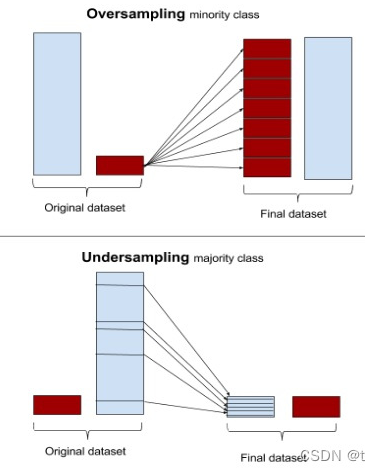
Pytorch 的权重采样器 WeightedRandomSampler
如何实现重采样呢?Pytorch 提供了权重采样器 torch.utils.data.WeightedRandomSampler。
粗略看一下文档:
非常需要解释一下这个权重采样器:
- 首先传入一个权重信息
**weights**,这个weights是所有样本(整个待采样数据集)中每个样本的权重。- 所以传入的这个向量的长度可以等于数据集的长度。
- 每个权重值则是你抽选该样本的可能性。这里的权重值大小没有要求所有加和为 1。可以预见的是,同一个类别的样本的权重值应当都设为 该类别占比的倒数。比如阳性占比20%,其权重应设为 5;对应的阴性类样本的权重应为 1/80% = 1.25。
- 第二个参数
**num_samples**表示抽选多少个。 **replacement**表示是否放回抽样,一般都要放回,不仅保证数据分布没变,还能让少的那一类被重复抽到,以保证数量与多数类平衡。- 注意这个采样器到时候需要传入
Dataloader(),它指导了**Dataloader()**怎么先对**dataset**进行采样,然后读取。且一旦传入了这个sampler,Dataloader不能再传入shuffle参数了。
但是它下面给的 Example 实在是太烂了,很难理解发生了什么。
我自己画了一张图,阐释了 WeightedRandomSampler 是怎么工作的。
WeightedRandomSampler 工作流图

可以看到 sampler 和 dataset 最终都为 Dataloader 服务的,从原始数据的标签一一标上对应权重传入采样器(还需要设定采样数和是否放回),原始数据则转化成 dataset。sampler 和 dataset 传入 Dataloader 后,Dataloader 就会以 dataset 为蓝本按 sampler 指定的规则采样,采好样作为生成器按 batch_size 输出。
代码复现
我自己根据流图写了个演示代码,可以观察最后输出的一个批次数据中,0、1比例都是平衡的。(下面代码也可直接看我的 [GitHub](https://github.com/aquamarineaqua/D2L-My-Note/blob/main/how%20to%20use%20WeightRandomSampler.ipynb))
生成人工数据
import pandas as pdimport numpy as npdf_y_neg = pd.DataFrame(np.random.randint(0, 1, size = 900)) # 生成 900 个 0df_y_pos = pd.DataFrame(np.random.randint(1, 2, size = 100)) # 生成 100 个 1df_y = pd.concat([df_y_neg, df_y_pos], ignore_index = True).sample(frac=1).reset_index(drop = True) # 拼起来打乱,生成标签列ydf_X = pd.DataFrame(np.random.normal(1, 0.1, size = (1000, 10))) # 生成1000个数据,10个维度df = pd.concat([df_X, df_y], axis = 1) # 拼起来组成数据集df.columns = ['x' + str(n) for n in range(10)] + ['y'] # 标上列名
计算权重
num_pos = df.loc[df['y'] == 1].shape[0]num_neg = df.loc[df['y'] == 0].shape[0]pos_weight = (num_pos + num_neg) / num_posneg_weight = (num_pos + num_neg) / num_negprint(num_pos, num_neg)print(pos_weight, neg_weight) # 算出权重

添加权重列
df['y_weight'] = df['y'].apply(lambda x : pos_weight if x==1 else neg_weight) # 添加权重列
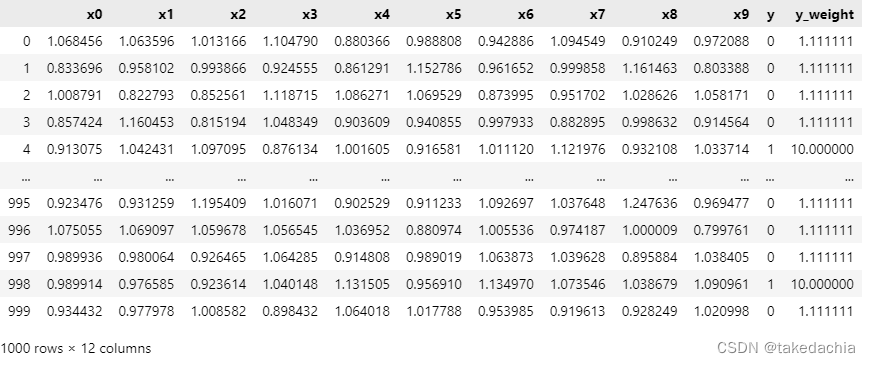
定义 WeightedRandomSampler 抽样器
import torchdata_y_w = torch.tensor(df['y_weight'].to_numpy(), dtype=torch.float) # 注意一下,DataFrame要to_numpy()转成numpy再传入tensor,不然会报错num_samples = df.shape[0] # 一共抽多少样本。可设置为与数据集同一数量,也可以自己设。# 定义抽样器,传入准备好的权重数组,抽样总数,并选择放回抽样sampler = torch.utils.data.sampler.WeightedRandomSampler(data_y_w, num_samples, replacement=True)
构建 dataset,建立 Dataloader
data_features = torch.tensor(df.iloc[:, :-1].values, dtype=torch.float) # 数据弃掉权重列,传入tensordata_features_X = data_features[:,:-1] # 取Xdata_features_y = data_features[:, -1].long() # 取y,标签转成long型# TensorDataset 可以用来对 tensor 进行打包,类似zip。形式是数据特征+标签。dataset = torch.utils.data.TensorDataset(data_features_X, data_features_y)# 建立Dataloaderbatch_size = 64data_iter = torch.utils.data.DataLoader(dataset = dataset, sampler = sampler, batch_size = batch_size)
查看数据
# 查看一个批次的数据X, y = next(iter(data_iter))print(y)

训练时的重采样
我们在训练模型时,一般在一个 epoch 下使用一次 Dataloader:
for epoch in range(num_epochs):for X, y in data_iter:......
所以每轮 epoch 的采样到的结果都不同,保证多个 epoch 下等可能地采到所有数据。

若有收获,就点个赞吧
0 人点赞
