第六周
24. 正则化之 weight decay(权值衰减)
Content
- 正则化与偏差-方差分解
- pytorch 中的 L2 正则项——weight decay
24.1 正则化与偏差-方差分解
1. 正则化
Regularization:减小方差的策略
误差可分解为:偏差,方差与噪声之和。即误差 = 偏差 + 方差 + 噪声之和
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界


Regularization:减小方差的策略
损失函数:衡量模型输出与真实标签的差异
损失函数(Loss Function):
代价函数(Cost Function):
目标函数(Objective Function):
2. L1、L2 正则化
目标函数(Objective Function):
L1 Regularization Term:
L2 Regularization Term:
24.2 pytorch 中的 L2 正则项——weight decay
L2 Regularization = weight decay(权值衰减)
目标函数(Objective Function):
未加正则项之前,更新公式:
加入正则项之后,更新公式:

注:在优化器中实现正则化
torch.optim.SGD(weight_decay=1e-2)
25. 正则化之 Dropout
Content
- Dropout 概念
- Dropout 注意事项
25.1 Dropout 概念
Dropout:随机失活,有一定概率使得神经元权重置零
随机:dropout probability
失活:weight = 0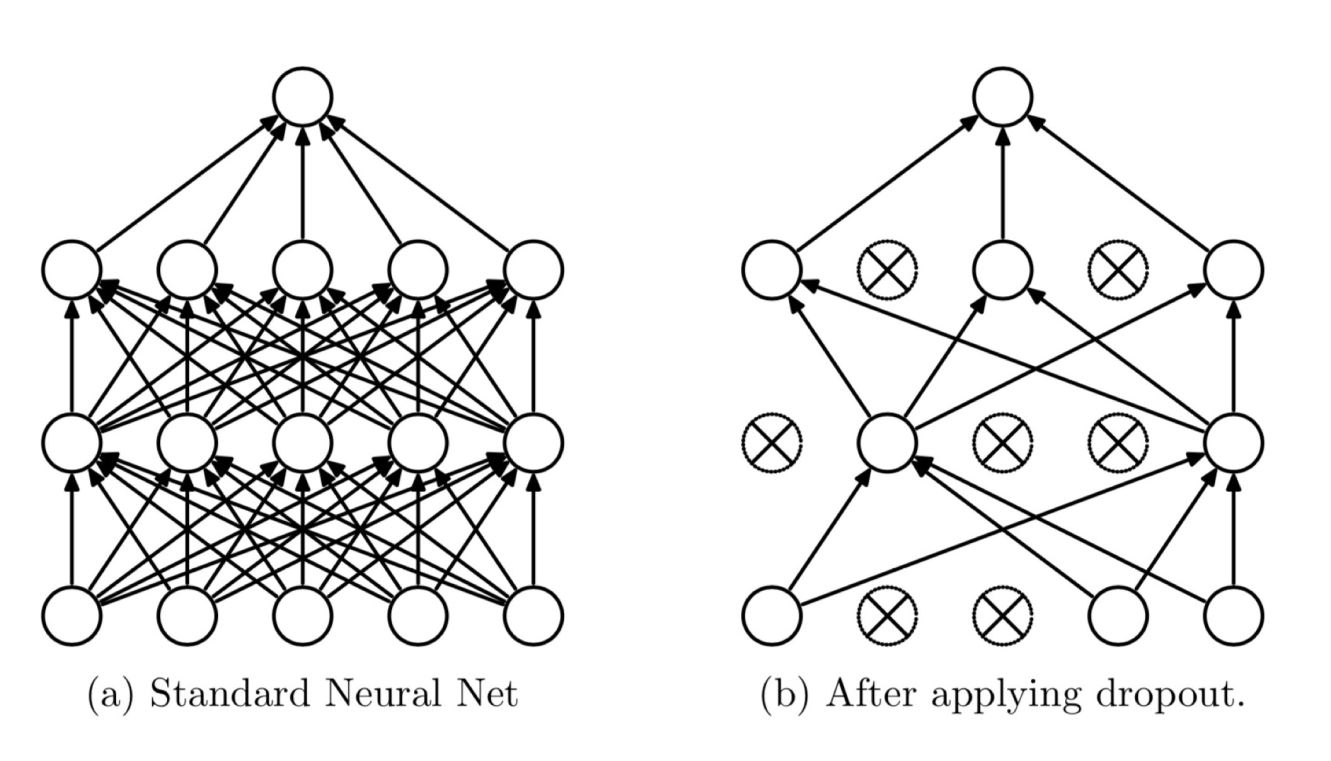
《Dropout: A simple way to prevent neural networks from overfitting》
nn.Dropout
功能:Dropout 层
参数:
- p:被舍弃概率,失活概率
torch.nn.Dropout(p=0.5, # 失活概率inplace=False)
实现细节:
训练时权重均乘以 ,即除以
25.2 Dropout 注意事项
数据尺度变化:
- 模型训练时,由于部分神经元失活,使得参数尺度发生了变化
- 模型测试时,对应的,所有权重需要乘以 保持尺度一致
- 在pytorch中,在模型训练时所有权重乘以 ,模型测试时便不需要乘以 ,降低了测试的复杂度
# 模型进入测试模式module_name.eval()# 模型进入恢复训练模式module_name.train()

若有收获,就点个赞吧
0 人点赞
