参考来源:
简书:小白都看得懂的监督学习与无监督学习
简书:我的机器学习笔记(一) - 监督学习vs 无监督学习
前言
机器学习分为:监督学习,无监督学习,半监督学习(也可以用hinton所说的强化学习)等。
在这里,主要理解一下监督学习和无监督学习。
机器学习:
首先呢,学习可以称为一个举一反三的过程,举个栗子:我们在学生时代经常参加的考试,考试的题目在上考场前我们未必做过,但是在考试之前我们通常都会刷很多的题目,通过刷题目学会了解题方法,因此考场上面对陌生问题也可以算出答案。
机器学习的思路也类似:我们可以利用一些训练数据(已经做过的题),使机器能够利用它们(解题方法)分析未知数据(考场的题目)。就像考试前老师给我们预测考试会考什么一样。
简单的一句话:机器学习就是让机器从大量的数据集中学习,进而得到一个更加符合现实规律的模型,通过对模型的使用使得机器比以往表现的更好。
监督学习(supervised learning)
定义:根据已有的数据集,知道输入和输出结果之间的关系。根据这种已知的关系,训练得到一个最优的模型。也就是说,在监督学习中训练数据既有特征(feature)又有标签(label),通过训练,让机器可以自己找到特征和标签之间的联系,在面对只有特征没有标签的数据时,可以判断出标签。
通俗一点,可以把机器学习理解为我们教机器如何做事情。
监督学习的分类:回归(Regression)、分类(Classification)
回归(Regression)
回归问题是针对于连续型变量的。
举个栗子:预测房屋价格
假设想要预测房屋价格,绘制了下面这样的数据集。水平轴上,不同房屋的尺寸是平方英尺,在竖直轴上,是不同房子的价格,单位时(千万$)。给定数据,假设一个人有一栋房子,750平方英尺,他要卖掉这栋房子,想知道能卖多少钱。
这个时候,监督学习中的回归算法就能派上用场了,我们可以根据数据集来画直线或者二阶函数等来拟合数据。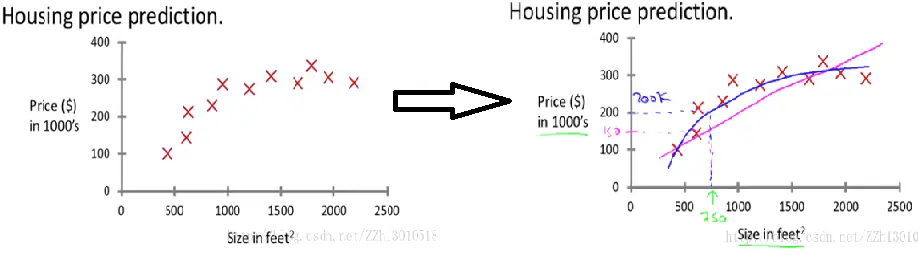
通过图像,我们可以看出直线拟合出来的150k,曲线拟合出来是200k,所以要不断训练学习,找到最合适的模型得到拟合数据(房价)。
回归通俗一点就是,对已经存在的点(训练数据)进行分析,拟合出适当的函数模型y=f(x),这里y就是数据的标签,而对于一个新的自变量x,通过这个函数模型得到标签y。
分类(Classification)
和回归最大的区别在于,分类是针对离散型的,输出的结果是有限的。
举个栗子:估计肿瘤性质
假设某人发现了一个乳腺瘤,在乳腺上有个z肿块,恶性瘤是危险的、有害的;良性瘤是无害的。
假设在数据集中,水平轴是瘤的尺寸,竖直轴是1或0,也可以是Y或N。在已知肿瘤样例中,恶性的标为1,良性的标为0。那么,如下,蓝色的样例便是良性的,红色的是恶性的。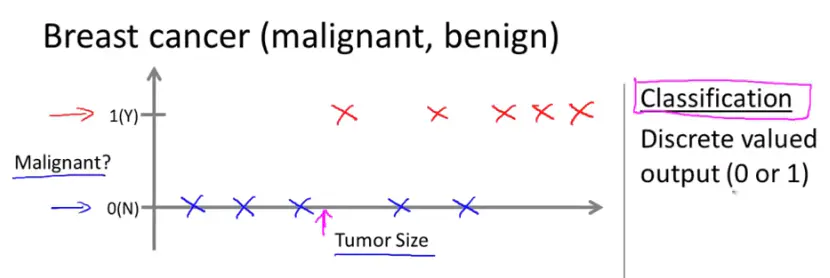
这个时候,机器学习的任务就是估计该肿瘤的性质,是恶性的还是良性的。
那么分类就派上了用场,在这个例子中就是向模型输入人的各种数据的训练样本(这里是肿瘤的尺寸,当然现实生活里会用更多的数据,如年龄等),产生“输入一个人的数据,判断是否患有癌症”的结果,结果必定是离散的,只有“是”或“否”。
所以简单来说分类就是,要通过分析输入的特征向量,对于一个新的向量得到其标签。
无监督学习(unsupervised learning)
定义:我们不知道数据集中数据、特征之间的关系,而是要根据聚类或一定的模型得到数据之间的关系。
可以这么说,比起监督学习,无监督学习更像是自学,让机器学会自己做事情,是没有标签(label)的。
接刚刚上面机器学习解释时用到的例子来更好理解一下二者的区别:
对于平时的考试来说,监督学习相当于我们做了很多题目都知道它的标准答案,所以在学习的过程中,我们可以通过对照答案,来分析问题找出方法,下一次在面对没有答案的问题时,往往也可以正确地解决。 而无监督学习,是我们不知道任何的答案,也不知道自己做得对不对,但是做题的过程中,就算不知道答案,我们还是可以大致的将语文,数学,英语这些题目分开,因为这些问题内在还是具有一定的联系。
如下图所示,在无监督学习中,我们只是给定了一组数据,我们的目标是发现这组数据中的特殊结构。例如我们使用无监督学习算法会将这组数据分成两个不同的簇,,这样的算法就叫聚类算法。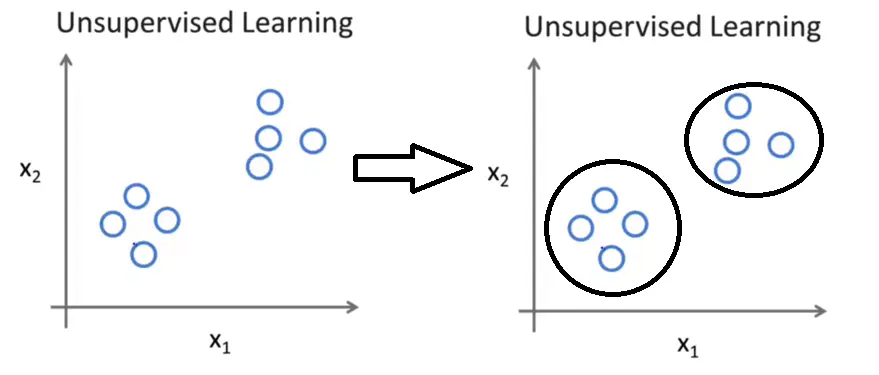
无监督学习的应用:
- Google新闻按照内容结构的不同分成财经,娱乐,体育等不同的标签,这就是无监督学习中的聚类。
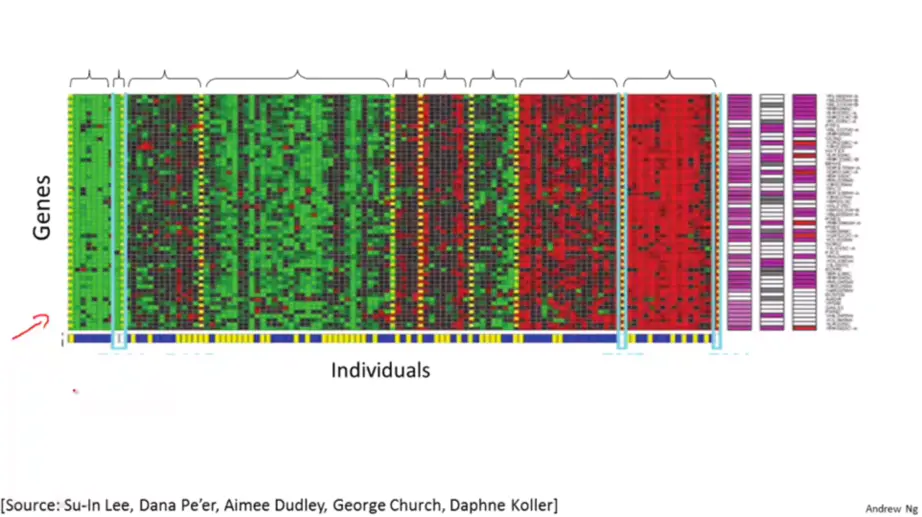
- 根据给定基因把人群分类。如图是DNA数据,对于一组不同的人我们测量他们DNA中对于一个特定基因的表达程度。然后根据测量结果可以用聚类算法将他们分成不同的类型。这就是一种无监督学习, 因为我们只是给定了一些数据,而并不知道哪些是第一种类型的人,哪些是第二种类型的人等等。
鸡尾酒派对效应
详见课程:
https://www.coursera.org/learn/machine-learning/lecture/olRZo/unsupervised-learning
/https://www.coursera.org/lecture/machine-learning/unsupervised-learning-olRZo
其他
这里又举了其他几个例子,有组织计算机集群,社交网络分析,市场划分,天文数据分析等。具体可以看一下视频:
https://www.coursera.org/learn/machine-learning/lecture/olRZo/unsupervised-learning
/https://www.coursera.org/lecture/machine-learning/unsupervised-learning-olRZo

若有收获,就点个赞吧
0 人点赞
