参考来源:
图神经网络
The “MessagePassing” Base Class
消息传递范式
消息传递范式是一种聚合邻接节点信息来更新中心节点信息的范式,它将卷积算子推广到了不规则数据领域,实现了图与神经网络的连接。该范式包含这样三个步骤:
- 邻接节点信息变换
- 邻接节点信息聚合到中心节点
- 聚合信息变换
消息传递神经网络(MPNN)是一种框架,其前向传递有两个阶段:消息传递阶段(Message Passing)、读出阶段(Readout),这里先介绍消息传递阶段
消息传递的三个函数
三个函数分为:
各边要传递的消息的创建 ϕ、消息聚合 □ 、节点表征的更新 γ 三个步骤
对三个函数的要求:
- 要求上述三个函数均可微
- 且消息聚合具有排列不变性(函数输出结果与输入参数的排列无关,即对节点的排列不敏感)。
- 具有排列不变性的函数有和函数、均值函数和最大值函数。
消息传递的数学描述:
用 xi(k−1) ∈ RF 表示 (k−1) 层中节点 i 的节点属性,ej,i ∈ RD 表示从节点 j 到节点 i 的边的属性,消息传递可以描述为:
节点嵌入与节点表征
- 节点嵌入(Node Embedding):神经网络生成节点表征的操作,或节点表征也称节点嵌入
- 这里节点嵌入仅指代前者
- 好的节点表征可以衡量节点间的相似性,需要通过图神经网络训练得到
因为简单且强大的特性,消息传递范式现被人们广泛地使用。基于此范式,我们可以定义聚合邻接节点信息来生成中心节点表征的图神经网络。在 PyG 中,**MessagePassing** 基类是所有基于消息传递范式的图神经网络的基类,它大大地方便了我们对图神经网络的构建。
一、MessagePassing 基类初步分析
**MessagePassing** 是 **torch_geometric** 中 GNN 模型的基类,要继承这个类,需要复写三个函数:**propagate(edge_index, size=None)**、**message()**、**update()**,其中 **propagate** 在执行的过程中会调用 **message** 和 **update**。假设顶点 V1 和顶点 V2、V3、V4 ….. Vn 有边相连,**propagate** 做的事情是将 V2、V3、V4 ….. Vn 的信息加(默认 'add',也可以 'mean'、'max')到 V1 上。GCN 的实现,三个函数都是在 **MessagePassing** 的基础上实现的。
1. 属性
class MessagePassing(torch.nn.Module):def __init__(self, aggr: Optional[str] = "add", flow: str = "source_to_target", node_dim: int = -2):super(MessagePassing, self).__init__()# 此处省略n行代码self.aggr = aggrassert self.aggr in ['add', 'mean', 'max',None]self.flow = flowassert self.flow in ['source_to_target', 'target_to_source']self.node_dim = node_dimself.fuse = self.inspector.implements('message_and_aggregate')# 此处省略n行代码
init()
对象初始化方法。
MessagePassing(aggr="add",flow="source_to_target",node_dim=-2):
**aggr**:定义要使用的聚合方案,默认add。**flow**:定义消息传递的流向,从而确定给某节点传递消息的边的集合,默认s→t。- 用
i表示目标节点,j表示邻接节点 flow='source_to_target':target表入,即传递信息的边的集合为(j ,i) ∈ E。flow='target_to_source':target表出,即传递信息的边的集合为(i ,j) ∈ E。
- 用
**node_dim**:定义scatter沿着哪个轴线传播,默认-2。**fuse**:检查是否实现了message_and_aggregate()方法,不需要自己定义。
完整版:
class MessagePassing(torch.nn.Module)"""Args:aggr (string, optional): The aggregation scheme to use(:obj:`"add"`, :obj:`"mean"` or :obj:`"max"`).(default: :obj:`"add"`)flow (string, optional): The flow direction of message passing(:obj:`"source_to_target"` or :obj:`"target_to_source"`).(default: :obj:`"source_to_target"`)node_dim (int, optional): The axis along which to propagate.(default: :obj:`0`)"""def __init__(self, aggr='add', flow='source_to_target', node_dim=0):super(MessagePassing, self).__init__()# 聚合方式self.aggr = aggrassert self.aggr in ['add', 'mean', 'max']self.flow = flowassert self.flow in ['source_to_target', 'target_to_source']self.node_dim = node_dimassert self.node_dim >= 0# 存储重写message方法中的参数self.__msg_params__ = inspect.signature(self.message).parameters# 存储重写aggregate方法中的参数self.__aggr_params__ = inspect.signature(self.aggregate).parameters# 将不可变映射类型转为有序字典self.__aggr_params__ = OrderedDict(self.__aggr_params__)# 丢弃第一个键值对,('inputs', <Parameter "inputs">)self.__aggr_params__.popitem(last=False)# 重新转化为MappingProxyTypeself.__aggr_params__ = MappingProxyType(self.__aggr_params__)# 存储重写update方法中的参数self.__update_params__ = inspect.signature(self.update).parametersself.__update_params__ = OrderedDict(self.__update_params__)self.__update_params__.popitem(last=False)self.__update_params__ = MappingProxyType(self.__update_params__)# 除去预定义参数msg_args = set(self.__msg_params__.keys()) - msg_special_argsaggr_args = set(self.__aggr_params__.keys()) - aggr_special_argsupdate_args = set(self.__update_params__.keys()) - update_special_args# 将其合并self.__args__ = set().union(msg_args, aggr_args, update_args)# 保证数据处理前维度统一def __set_size__(self, size, index, tensor):if not torch.is_tensor(tensor):passelif size[index] is None:size[index] = tensor.size(self.node_dim)elif size[index] != tensor.size(self.node_dim):raise ValueError((f'Encountered node tensor with size 'f'{tensor.size(self.node_dim)} in dimension {self.node_dim}, 'f'but expected size {size[index]}.'))# 将所有可能以后用的到参数均初始化def __collect__(self, edge_index, size, kwargs):# edge_index has shape [2, E],边是两个node之间的关系,所以是2,E是边个数# 消息传递流向,默认source_to_target,i=1,j=0i, j = (0, 1) if self.flow == "target_to_source" else (1, 0)# ij为字典ij = {"_i": i, "_j": j}out = {}# 依次处理message、aggregate和update中的参数并存入out字典中for arg in self.__args__:# 处理最后两个字符if arg[-2:] not in ij.keys():out[arg] = kwargs.get(arg, inspect.Parameter.empty)else:# 取出0idx = ij[arg[-2:]]# 获取字典kwargs中arg[:-2]数据,否则返回空data = kwargs.get(arg[:-2], inspect.Parameter.empty)# 判定data,如果为空,直接赋值为空,继续下一批数据if data is inspect.Parameter.empty:out[arg] = datacontinue#是tuple或者list类型,进行如下处理if isinstance(data, tuple) or isinstance(data, list):assert len(data) == 2self.__set_size__(size, 1 - idx, data[1 - idx])data = data[idx]# 不是tensor类型,进行如下处理if not torch.is_tensor(data):out[arg] = datacontinue# 保证数据处理前维度统一self.__set_size__(size, idx, data)# torch中取出相应数据,第一个参数是维度,第二个是索引out[arg] = data.index_select(self.node_dim, edge_index[idx])# size不为空则为本身,否则交换次序size[0] = size[1] if size[0] is None else size[0]size[1] = size[0] if size[1] is None else size[1]# 添加特殊消息参数out['edge_index'] = edge_indexout['edge_index_i'] = edge_index[i]out['edge_index_j'] = edge_index[j]out['size'] = sizeout['size_i'] = size[i]out['size_j'] = size[j]# 添加特殊消息参数.out['index'] = out['edge_index_i']out['dim_size'] = out['size_i']return out# 将之前传入参数数据依次赋值def __distribute__(self, params, kwargs):out = {}for key, param in params.items():data = kwargs[key]# 检验是否赋值if data is inspect.Parameter.empty:# 若所需数据空缺则报错if param.default is inspect.Parameter.empty:raise TypeError(f'Required parameter {key} is empty.')# 赋默认值data = param.default# 存入字典out[key] = datareturn out
2. 方法
class MessagePassing(torch.nn.Module):# 此处省略n行代码self.fuse = self.inspector.implements('message_and_aggregate')self.node_dim = node_dimdef propagate(self, edge_index: Adj, size: Size = None, **kwargs):# 此处省略n行代码# 检查edge_index是否SparseTensor类型# 检查是否实现了message_and_aggregate()方法,是就执行该方法,再执行update方法if (isinstance(edge_index, SparseTensor) and self.fuse and not self.__explain__):coll_dict = self.__collect__(self.__fused_user_args__, edge_index, size, kwargs)# message_and_aggregatemsg_aggr_kwargs = self.inspector.distribute('message_and_aggregate', coll_dict)out = self.message_and_aggregate(edge_index, **msg_aggr_kwargs)# updateupdate_kwargs = self.inspector.distribute('update', coll_dict)return self.update(out, **update_kwargs)# 上述检查不通过,依次执行message(),aggregate(),update()方法elif isinstance(edge_index, Tensor) or not self.fuse:coll_dict = self.__collect__(self.__user_args__, edge_index, size, kwargs)# messagemsg_kwargs = self.inspector.distribute('message', coll_dict)out = self.message(**msg_kwargs)# aggregateaggr_kwargs = self.inspector.distribute('aggregate', coll_dict)out = self.aggregate(out, **aggr_kwargs)# updateupdate_kwargs = self.inspector.distribute('update', coll_dict)return self.update(out, **update_kwargs)def message(self, x_j):# 按需要覆写或不写return x_jdef aggregate(self, inputs: Tensor, index: Tensor,ptr: Optional[Tensor] = None,dim_size: Optional[int] = None) -> Tensor:# 按需要覆写或不写if ptr is not None:ptr = expand_left(ptr, dim=self.node_dim, dims=inputs.dim())return segment_csr(inputs, ptr, reduce=self.aggr)else:return scatter(inputs, index, dim=self.node_dim, dim_size=dim_size, reduce=self.aggr)def update(self, inputs):# 按需要覆写或不写return inputsdef message_and_aggregate(self, adj_t, x, norm):# 按需要覆写或不写return x
propagate()
开始传递消息的起始调用,在此方法中 **message**、**update** 等方法被调用。
MessagePassing.propagate(edge_index,size=None,**kwargs):
- propagate(edge_index, size=None, **kwargs)
- 调用以传递消息,在此方法中
**message**、**aggregate**、**update**等方法被调用 - 若检测到
**message_and_aggregate**和edge_index为SparseTensor,则即使**message**和**aggregate**存在也不调用,而是调用**message_and_aggregate**。 - 可将节点属性拆分成中心节点和邻接节点,对拆分的数据有格式要求,必须为
**[num_nodes, *]**。拆分如属性xi和邻接节点属性xj,度degi、degj。 size=None默认邻接矩阵对称,若是非对称的邻接矩阵(如二部图)则要传递参数size=(N,M)。kwargs: 图其他属性或额外的数据。
- 调用以传递消息,在此方法中
完整版:
def propagate(self, edge_index, size=None, **kwargs):#初始调用以开始传播消息"""Args:edge_index (Tensor): The indices of a general (sparse) assignmentmatrix with shape :obj:`[N, M]` (can be directed orundirected).size (list or tuple, optional): The size :obj:`[N, M]` of theassignment matrix. If set to :obj:`None`, the size will beautomatically inferred and assumed to be quadratic.(default: :obj:`None`)**kwargs: Any additional data which is needed to construct andaggregate messages, and to update node embeddings."""#保证最后size长度为2且类型为listsize = [None, None] if size is None else sizesize = [size, size] if isinstance(size, int) else sizesize = size.tolist() if torch.is_tensor(size) else sizesize = list(size) if isinstance(size, tuple) else sizeassert isinstance(size, list) # assert 断言,等价于if not expression: raise AssertionErrorassert len(size) == 2# 准备好一切可能用到的参数kwargs = self.__collect__(edge_index, size, kwargs)# 依据需要参数数据从kwargs中获取msg_kwargs = self.__distribute__(self.__msg_params__, kwargs)# 双星号表示转化为字典输入out = self.message(**msg_kwargs)aggr_kwargs = self.__distribute__(self.__aggr_params__, kwargs)out = self.aggregate(out, **aggr_kwargs)update_kwargs = self.__distribute__(self.__update_params__, kwargs)out = self.update(out, **update_kwargs)return out
message()
首先确定要给节点 i 传递消息的边的集合(运行 flow="source_to_target" 或者 flow="target_to_source"),接着为各条边创建要传递给节点 i 的消息,即实现 ϕ 函数。
MessagePassing.message(...):
**message**(写入需要的参数…)- 实现 ϕ 函数,创建各边要传递的邻接节点消息。
- 可以接收传递给
**propagate**方法的任何参数,只要在其中进行定义。如**def message(self,x_j)**而非**def message(self,x_j=x_j)**。
完整版:
def message(self, x_j): # pragma: no coverr"""Constructs messages to node :math:`i` in analogy to:math:`\phi_{\mathbf{\Theta}}` for each edge in:math:`(j,i) \in \mathcal{E}` if :obj:`flow="source_to_target"` and:math:`(i,j) \in \mathcal{E}` if :obj:`flow="target_to_source"`.Can take any argument which was initially passed to :meth:`propagate`.In addition, tensors passed to :meth:`propagate` can be mapped to therespective nodes :math:`i` and :math:`j` by appending :obj:`_i` or:obj:`_j` to the variable name, *.e.g.* :obj:`x_i` and :obj:`x_j`."""return x_j
aggregate()
即将从源节点传递过来的消息聚合在目标节点上,常用加和(sum)、平均(mean)以及取最大(max)的方式。
MessagePassing.aggregate(...):
**aggregate**(inputs, …)- 实现消息聚合。
- 关于
scatter(src,index,dim=-1,out,dim_size,reduce='sum'):按照dim的操作方向, 将src的元素加到index指示的位置去。参考torch_scatter.scatter或torch_scatter.scatter区别scatter_。 **propagate**调用时,传入给inputs的是message的输出。
完整版:
def aggregate(self, inputs, index, dim_size): # pragma: no coverr"""Aggregates messages from neighbors as:math:`\square_{j \in \mathcal{N}(i)}`.By default, delegates call to scatter functions that support"add", "mean" and "max" operations specified in :meth:`__init__` bythe :obj:`aggr` argument."""# 专门开一个博客讲(https://www.yuque.com/yuque-qsztn/va7nxh/cmntz0)#一句话————按传入方式聚合节点信息return scatter_(self.aggr, inputs, index, self.node_dim, dim_size)
message_and_aggregate()
即融合邻接节点信息变换和邻接节点信息聚合,如果在此方法里定义这项操作可以使得程序运行更加高效。
MessagePassing.message_and_aggregate(...):
**message_and_aggregate**(写入需要的参数…)- 一些场景里 ϕ 和聚合可以融合在一起操作,就可以在该方法里定义这两项操作,使程序运行更加高效。
update()
为每个节点更新节点表征,即实现函数。此方法以 **aggregate** 方法的输出为第一个参数,并接收所有传递给 **propagate()** 方法的参数。
MessagePassing.update(aggr_out, ...):
**update**(inputs, …)- 节点表征的更新,可以接收传递给
**propagate**方法的任何参数。 **propagate**调用时inputs输入的是**aggregate**的输出。
- 节点表征的更新,可以接收传递给
完整版:
def update(self, inputs): # pragma: no coverr"""Updates node embeddings in analogy to:math:`\gamma_{\mathbf{\Theta}}` for each node:math:`i \in \mathcal{V}`.Takes in the output of aggregation as first argument and any argumentwhich was initially passed to :meth:`propagate`."""return inputs
以上内容来源于The “MessagePassing” Base Class。
二、MessagePassing子类实例
“我们以继承 MessagePassing 基类的 GCNConv 类为例,学习如何通过继承 MessagePassing 基类来实现一个简单的图神经网络”——这部分的内容可参见网站中的消息传递图神经网络.md:https://github.com/datawhalechina/team-learning-nlp/tree/master/GNN/Markdown 版本
数学定义

或
A^=A+I 加入了自循环的邻接矩阵,D^ 是由 A^ 计算的度矩阵。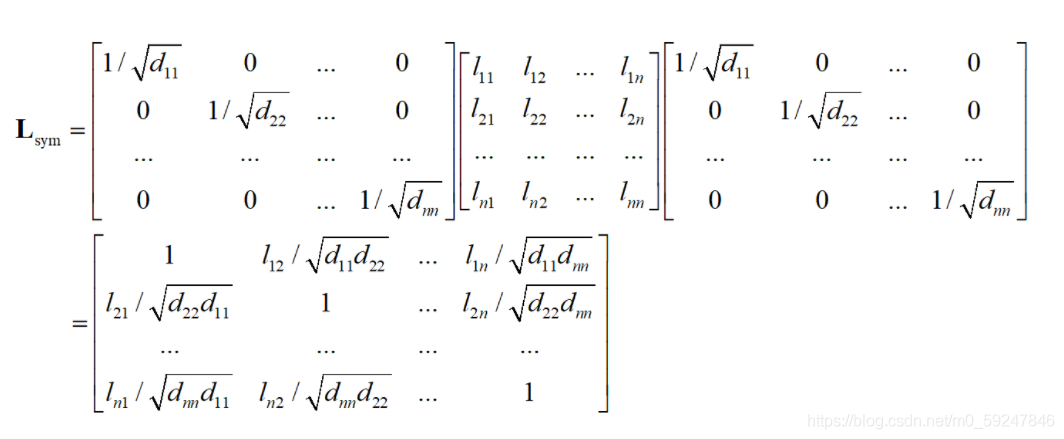
矩阵 A 行表出,列表入。左矩阵 D 对对应的出节点×,右矩阵 D 对对应的入节点 x。
代码实现
import torchfrom torch_geometric.nn import MessagePassingfrom torch_geometric.utils import add_self_loops, degreeclass GCNConv(MessagePassing):def __init__(self, in_channels, out_channels):super(GCNConv, self).__init__(aggr='add', flow='source_to_target')# "Add" aggregation (Step 5).# flow='source_to_target' 表示消息从源节点传播到目标节点# 线性变换层 Θself.lin = torch.nn.Linear(in_channels, out_channels)def forward(self, x, edge_index):# x 形状 [N, in_channels]# edge_index 形状 [2, E]# Step 1:向邻接矩阵添加自环边.# edge_index形状为 [2,E+N]edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))# Step 2: 调用`torch.nn.Linear`实例对节点表征进行线性变换.x = self.lin(x) # 节点属性做线性变换# Step 3: 计算归一化系数.row, col = edge_index # row从节点0开始一直顺序排 e.g.[0,0,0,1,1…]deg = degree(col, x.size(0), dtype=x.dtype) # 计算度矩阵deg_inv_sqrt = deg.pow(-0.5)norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]# 若要将edge_index改写为SparseTensor# adjmat = SparseTensor(row=edge_index[0], col=edge_index[1], value=torch.ones(edge_index.shape[1]))# Step 4-5: 归一化邻接节点的节点表征.将相邻节点表征相加("求和 "聚合).# 调用propagate传递信息return self.propagate(edge_index, x=x, norm=norm, deg=deg.view((-1, 1))) # 若一个数据可以被拆分成属于中心节点的部分和属于邻接节点的部分,其形状必须是 [num_nodes, *],所以需要将deg的形状进行变换# return self.propagate(edge_index, x=x, norm=norm)# return self.propagate(adjmat, x=x, norm=norm, deg=deg.view((-1, 1)))# 覆写消息构建函数 Φdef message(self, x_j, norm, deg_i):# x_j 是邻接节点矩阵,形状为 [E+N, out_channels]# 这里flow = 'source_to_target',因此x_j行排序如row# deg_i 是col排序的点的度# Step 4: 通过`norm`对邻接节点表征`x_j`进行归一化处理.return norm.view(-1, 1) * x_j # 将每个邻接节点正则化,返回形状同 x_j# 不需要覆写aggregate和update# 这里未实现message_and_aggregate# 也可以覆写aggregate,举个例子def aggregate(self, inputs, index, ptr, dim_size):return super().aggregate(inputs, index, ptr=ptr, dim_size=dim_size)# index是中心节点,根据flow在此其排序同col# dim_size = 节点数# 覆写函数时,传入的参数不要写 y=y 这种格式# 调用网络from torch_geometric.datasets import Planetoiddataset = Planetoid(root='dataset', name='Cora')data = dataset[0]net = GCNConv(data.num_features, 64) # 类属性的定义h_nodes = net(data.x, data.edge_index) # 调用forward,输入参数print(h_nodes.shape)
**GCNConv** 继承了 **MessagePassing** 并以”求和”作为领域节点信息聚合方式。该层的所有逻辑都发生在其 **forward()** 方法中。
关于稀疏矩阵:torch的稀疏矩阵或torch的稀疏矩阵
degree用于计算节点出/入度:顺序即为节点序号[0,1,…,2707]。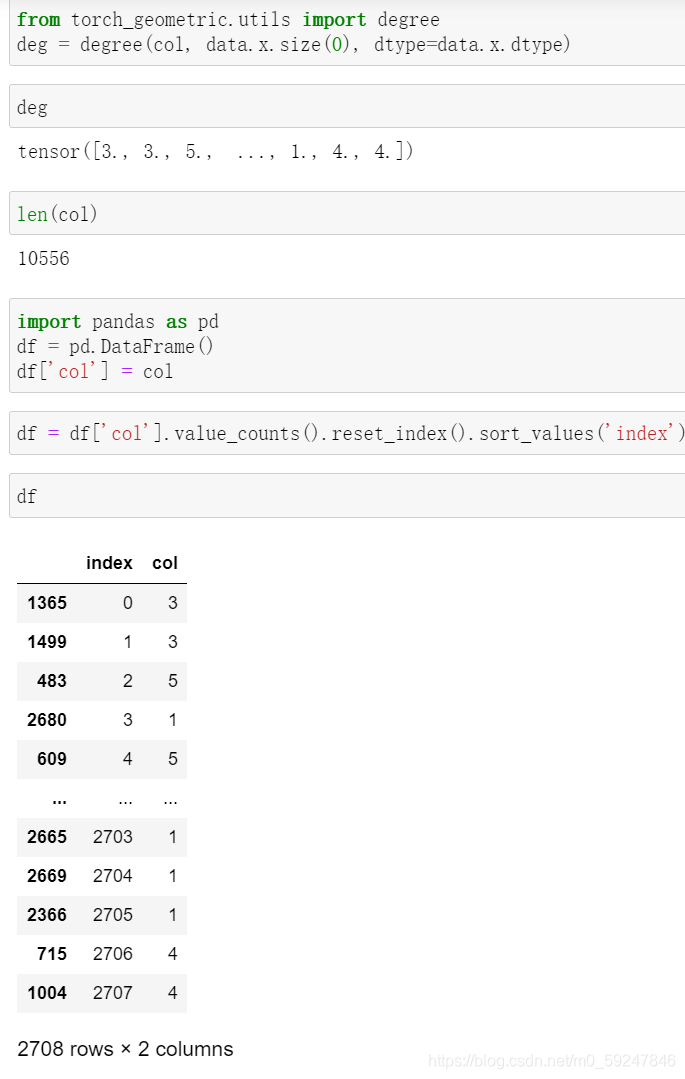
无注释代码:
class GCNConv(MessagePassing):def __init__(self, in_channels, out_channels):super(GCNConv, self).__init__(aggr='add', flow='source_to_target')self.lin = torch.nn.Linear(in_channels, out_channels)def forward(self, x, edge_index):edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))x = self.lin(x)row, col = edge_indexdeg = degree(col, x.size(0), dtype=x.dtype)deg_inv_sqrt = deg.pow(-0.5)norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]return self.propagate(edge_index, x=x, norm=norm, deg=deg.view((-1, 1)))def message(self, x_j, norm):return norm.view(-1, 1) * x_jdef aggregate(self, inputs, index, ptr, dim_size):return super().aggregate(inputs, index, ptr=ptr, dim_size=dim_size)from torch_geometric.datasets import Planetoiddataset = Planetoid(root='dataset', name='Cora')data = dataset[0]net = GCNConv(data.num_features, 64) # 类属性的定义h_nodes = net(data.x, data.edge_index) # 调用forward,输入参数print(h_nodes.shape)
三、message、aggregate、message_and_aggregate、update 方法的覆写
1. message 方法的覆写
我们希望 meassge 方法还能接收中心节点的度,所以对前面 GCNConv 的 message 方法进行改造得到新的 GCNConv 类,如下:
(1)在 **def forward(self, x, edge_index):** 中将
return self.propagate(edge_index, x=x, norm=norm)
更改为:
return self.propagate(edge_index, x=x, norm=norm, deg=deg.view((-1, 1)))
(2)在 **def message(self, x_j, norm):** 中将
return norm.view(-1, 1) * x_j
更改为:
return norm.view(-1, 1) * x_j * deg_i
2. aggregate 方法的覆写
(1)在 **class GCNConv(MessagePassing):** 中添加
def aggregate(self, inputs, index, ptr, dim_size):print('self.aggr:', self.aggr)print("`aggregate` is called")return super().aggregate(inputs, index, ptr=ptr, dim_size=dim_size)
3. message_and_aggregate 方法的覆写
(1)在原代码 **def forward(self, x, edge_index):** 中,增加下面这条代码,放置在 “Step 4-5”下面
adjmat = SparseTensor(row=edge_index[0], col=edge_index[1], value=torch.ones(edge_index.shape[1]))
(2)并更改下面这条代码
return self.propagate(edge_index, x=x, norm=norm)
更改为:
return self.propagate(adjmat, x=x, norm=norm, deg=deg.view((-1, 1)))
从代码的区别中,我们可以看到, 此处传的不再是 **edge_idex**,而是 SparseTensor 类型的 Adjancency Matrix。
(3)在 **class GCNConv(MessagePassing):** 中添加
def message_and_aggregate(self, adj_t, x, norm):print('`message_and_aggregate` is called')# 没有实现真实的消息传递与消息聚合的操作
4. update 方法的覆写
(1)在 class GCNConv(MessagePassing): 中添加
def update(self, inputs, deg):print(deg)return inputs
以上就是 **MessagePassing** 基类的运行流程。
四、MessagePassing 基类的运行流程——总结
首先导入必要的包,其次创建一个类,继承 MessagePassing 基类,然后初始化,定义 forward() 方法用于模型的表示,接着定义 massage() 方法、aggregate() 方法、message_and_aggregate() 方法、update() 方法。
参考资料:
https://github.com/datawhalechina/team-learning-nlp/tree/master/GNN/Markdown版本
https://pytorch-geometric.readthedocs.io/en/latest/notes/create_gnn.html
https://pytorch-geometric.readthedocs.io/en/latest/modules/nn.html
https://pytorch-geometric.readthedocs.io/en/latest/notes/create_gnn.html
https://pytorch-geometric.readthedocs.io/en/latest/notes/create_gnn.html
作业
- 请总结
MessagePassing基类的运行流程。
- 首先创建每条边上要传递的邻接节点的信息
- 其次对中心节点接收到的消息进行聚合
- 最后更新节点表征
- 请复现一个一层的图神经网络的构造,总结通过继承
MessagePassing基类来构造自己的图神经网络类的规范。
GNN规范:- 属性如神经网络层、继承
**flow**、**aggr**等属性。 - 定义
**forward**方法,传入节点矩阵**x**与边**edge_index**。- 添加自环边。
- 节点属性变换。
- 建立度矩阵,计算正则公式。
- (上述两步也可在 message 中完成)。
- 调用
**propagate**,传入参数**edge_index**、方法**message**、**aggregate**、**update**要用到的参数如**norm**、**x**、**deg**等。 - 返回最终update后的节点表征。
- 覆写有关函数。
**message**传入邻接节点信息**x_j**,正则化公式**norm**。
- 属性如神经网络层、继承
复现一个一层图神经网络
class GCNConv(MessagePassing):def __init__(self, in_channels, out_channels):super(GCNConv, self).__init__(aggr='add', flow='source_to_target')self.lin = torch.nn.Linear(in_channels, out_channels)def forward(self, x, edge_index):edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))x = self.lin(x)row, col = edge_indexdeg = degree(col, x.size(0), dtype=x.dtype)deg_inv_sqrt = deg.pow(-0.5)norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]return self.propagate(edge_index, x=x, norm=norm, deg=deg.view((-1, 1)))def message(self, x_j, norm):return norm.view(-1, 1) * x_jdef update(self,aggr_output):return F.relu(aggr_output)

若有收获,就点个赞吧
0 人点赞
