Graph Attention Networks
参考来源:
知乎:向往的GAT(图注意力模型)
GAT 图注意力网络 Graph Attention Network
知乎:GAT 基本原理+代码实现
GAT和所有的 attention mechanism 一样,GAT的计算也分为两步走:
- 计算注意力系数(attention coefficient)
- 加权求和(aggregate)
1. 计算注意力系数(attention coefficient)
对于顶点  ,逐个计算它的邻居们(
,逐个计算它的邻居们(  )和它自己之间的相似系数:
)和它自己之间的相似系数:
解读一下这个公式:首先一个共享参数  的线性映射对于顶点的特征进行了增维,当然这是一种常见的特征增强(feature augment)方法;
的线性映射对于顶点的特征进行了增维,当然这是一种常见的特征增强(feature augment)方法; 对于顶点
对于顶点  的变换后的特征进行了拼接(concatenate);最后
的变换后的特征进行了拼接(concatenate);最后  把拼接后的高维特征映射到一个实数上,作者是通过单层前馈神经网络 (single-layer feedforward neural network) 实现的。
把拼接后的高维特征映射到一个实数上,作者是通过单层前馈神经网络 (single-layer feedforward neural network) 实现的。
显然学习顶点  之间的相关性,就是通过可学习的参数
之间的相关性,就是通过可学习的参数  和映射
和映射  完成的。
完成的。
有了相关系数,离注意力系数就差归一化了!其实就是用个 softmax :
要注意这里作者用了个  ,至于原因嘛,估计是试出来的,毕竟深度玄学。
,至于原因嘛,估计是试出来的,毕竟深度玄学。
上面的步骤可以参考图2进行理解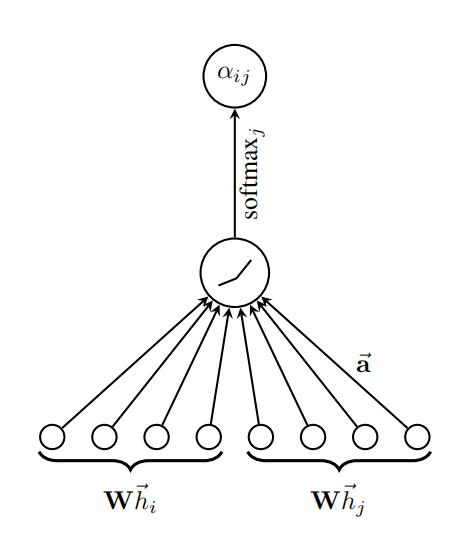 图2 第一步运算示意图
图2 第一步运算示意图
2. 加权求和(aggregate)
完成第一步,已经成功一大半了。第二步很简单,根据计算好的注意力系数,把特征加权求和(aggregate)一下。
 就是GAT输出的对于每个顶点
就是GAT输出的对于每个顶点  的新特征(融合了邻域信息),
的新特征(融合了邻域信息),  是激活函数。
是激活函数。
GAT 也可以采用 Multi-Head Attention,即多个 Attention,如下图所示: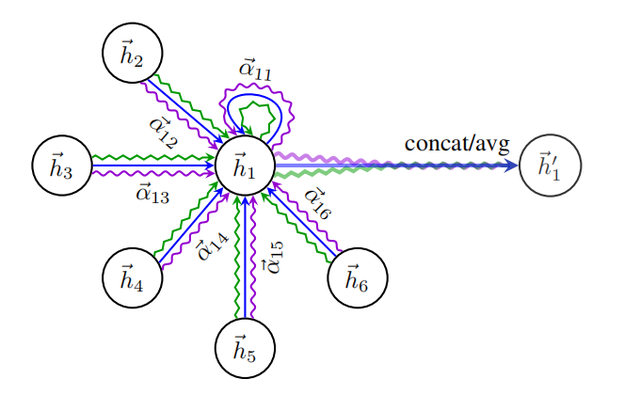 图3 第二步运算示意图
图3 第二步运算示意图
如果有 K 个 Attention,则需要把 K 个 Attention 生成的向量拼接在一起,如下:
但是如果是最后一层,则 K 个 Attention 的输出不进行拼接,而是求平均。
上面的步骤可以参考图3进行理解。
取出节点在 GAT 第一层隐藏层向量,用 T-SNE 算法进行降维可视化,得到的结果如下,可以看到不同类别的节点可以比较好的区分。
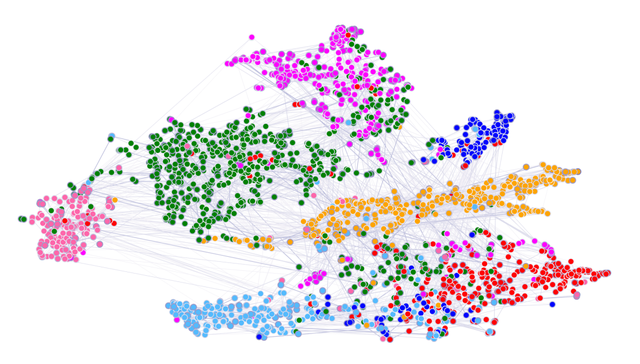
GAT 节点向量降维可视化

若有收获,就点个赞吧
0 人点赞
