参考来源:
CSDN:系统学习 Pytorch 笔记十: 模型的保存加载、模型微调、GPU 使用及 Pytorch 常见报错
Content
- 模型的保存与加载
- 模型的 finetune
- GPU 使用
1. 模型的保存与加载
我们的建立的模型训练好了是需要保存的,以备我们后面的使用,所以究竟如何保存模型和加载模型呢? 我们下面重点来看看, 主要分为三块: 首先介绍一下序列化和反序列化,然后介绍模型保存和加载的两种方式,最后是断点的续训练技术。
1.1 序列化与反序列化
序列化就是说内存中的某一个对象保存到硬盘当中,以二进制序列的形式存储下来,这就是一个序列化的过程。 而反序列化,就是将硬盘中存储的二进制的数,反序列化到内存当中,得到一个相应的对象,这样就可以再次使用这个模型了。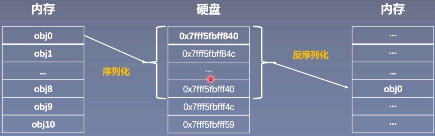
序列化和反序列化的目的就是将我们的模型长久的保存。Pytorch 中序列化和反序列化的方法:
**torch.save(obj, f)**:obj表示对象, 也就是我们保存的数据,可以是模型,张量,dict等等,f表示输出的路径。**torch.load(f, map_location)**:f表示文件的路径,map_location指定存放位置,CPU或者GPU, 这个参数挺重要,在使用GPU训练的时候再具体说。
1.2 模型保存与加载的两种方式
Pytorch 的模型保存有两种方法,
- 一种是保存整个 Module 。
- 另外一种是保存模型的参数。
- 保存与加载整个Module:
torch.save(net, path),torch.load(fpath)。 - 保存与加载模型参数:
torch.save(net.state_dict(), path),net.load_state_dict(torch.load(path))。
第一种方法比较懒,保存整个的模型架构, 比较费时占内存, 第二种方法是只保留模型上的可学习参数, 等建立一个新的网络结构,然后放上这些参数即可,所以推荐使用第二种。 下面通过代码看看具体怎么使用:
这里先建立一个网络模型:
import torch.nn as nnclass LeNet2(nn.Module):def __init__(self, classes):super(LeNet2, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 6, 5),nn.ReLU(),nn.MaxPool2d(2, 2),nn.Conv2d(6, 16, 5),nn.ReLU(),nn.MaxPool2d(2, 2))self.classifier = nn.Sequential(nn.Linear(16*5*5, 120),nn.ReLU(),nn.Linear(120, 84),nn.ReLU(),nn.Linear(84, classes))def forward(self, x):x = self.features(x)x = x.view(x.size()[0], -1)x = self.classifier(x)return xdef initialize(self):for p in self.parameters():p.data.fill_(20191104)## 建立一个网络net = LeNet2(classes=2019)# "训练"print("训练前:\n ", net.features[0].weight[0, ...])net.initialize()print("训练后: \n", net.features[0].weight[0, ...])
输出结果:
"""训练前:tensor([[[-0.0878, 0.0580, 0.0778, -0.0374, 0.0409],[-0.0203, 0.0520, 0.0884, -0.0282, -0.0690],[ 0.0141, 0.1042, -0.0655, 0.0342, -0.0891],[ 0.0072, 0.0619, 0.0097, -0.0418, -0.0555],[-0.0412, -0.0589, 0.0198, 0.0978, 0.0911]],[[-0.0241, 0.0064, -0.0435, 0.0198, 0.0587],[-0.0641, 0.0750, 0.0913, -0.0312, 0.0103],[ 0.0150, -0.1111, 0.0360, 0.0774, 0.1133],[-0.1051, 0.0642, -0.0230, 0.0835, -0.0559],[-0.0572, 0.0030, -0.0091, 0.0833, 0.0311]],[[ 0.0826, -0.1022, -0.0566, -0.0596, -0.0791],[ 0.0151, -0.0224, 0.1114, 0.0691, 0.0362],[-0.0781, 0.0185, 0.0248, 0.0198, -0.0768],[ 0.0741, 0.0380, -0.1133, -0.0720, 0.0230],[ 0.0582, 0.0326, -0.0382, 0.0488, -0.0289]]],grad_fn=<SelectBackward>)训练后:tensor([[[20191104., 20191104., 20191104., 20191104., 20191104.],[20191104., 20191104., 20191104., 20191104., 20191104.],[20191104., 20191104., 20191104., 20191104., 20191104.],[20191104., 20191104., 20191104., 20191104., 20191104.],[20191104., 20191104., 20191104., 20191104., 20191104.]],[[20191104., 20191104., 20191104., 20191104., 20191104.],[20191104., 20191104., 20191104., 20191104., 20191104.],[20191104., 20191104., 20191104., 20191104., 20191104.],[20191104., 20191104., 20191104., 20191104., 20191104.],[20191104., 20191104., 20191104., 20191104., 20191104.]],[[20191104., 20191104., 20191104., 20191104., 20191104.],[20191104., 20191104., 20191104., 20191104., 20191104.],[20191104., 20191104., 20191104., 20191104., 20191104.],[20191104., 20191104., 20191104., 20191104., 20191104.],[20191104., 20191104., 20191104., 20191104., 20191104.]]],grad_fn=<SelectBackward>)"""
下面就是保存整个模型和保存模型参数的方法: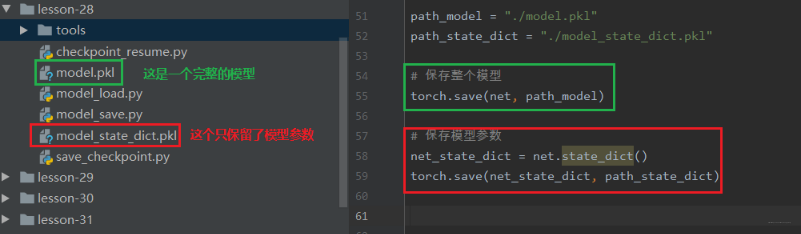
通过上面,我们已经把模型保存到硬盘里面了,那么如果要用的时候,应该怎么导入呢? 如果我们保存的是整个模型的话, 那么导入的时候就非常简单, 只需要:
path_model = "./model.pkl"net_load = torch.load(path_model)
并且我们可以直接打印出整个模型的结构: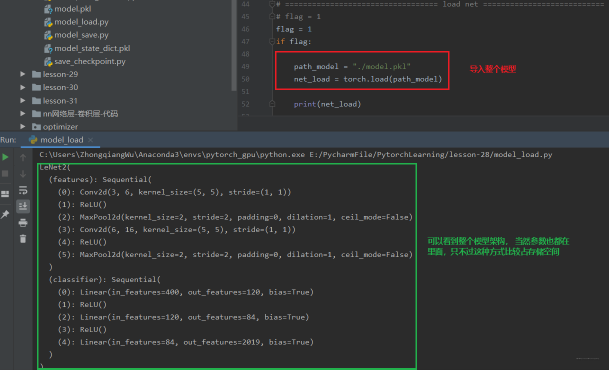
下面看看只保留模型参数的话应该怎么再次使用: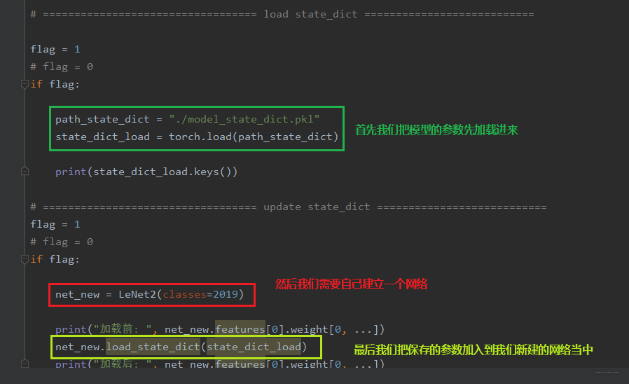
上面就是两种模型加载与保存的方式了,使用起来也是非常简单的,推荐使用第二种。
1.3 模型断点续训练
断点续训练技术就是当我们的模型训练的时间非常长,而训练到了中途出现了一些意外情况,比如断电了,当再次来电的时候,我们肯定是希望模型在中途的那个地方继续往下训练,这就需要我们在模型的训练过程中保存一些断点,这样发生意外之后,我们的模型可以从断点处继续训练而不是从头开始。 所以模型训练过程中设置 checkpoint/检查点 也是非常重要的。
那么就有一个问题了, 这个 checkpoint 里面需要保留哪些参数呢? 我们可以再次回忆模型训练的五个步骤: **数据 -> 模型 -> 损失函数 -> 优化器 -> 迭代训练**。 在这五个步骤中,我们知道数据,损失函数这些是没法变得, 而在迭代训练过程中,我们模型里面的可学习参数, 优化器里的一些缓存是会变的, 所以我们需要保留这些东西。所以我们的 checkpoint 里面需要保存模型的数据,优化器的数据,还有迭代到了第几次。
下面通过人民币二分类的实验,模拟一个训练过程中的意外中断和恢复,看看怎么使用这个断点续训练: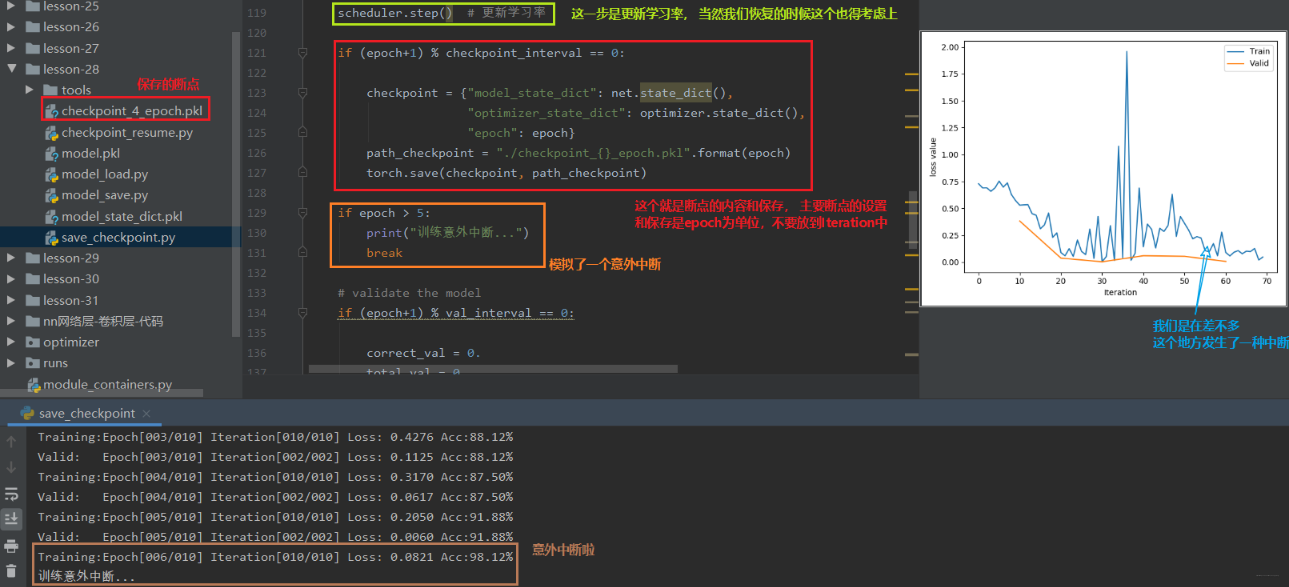
我们上面发生了一个意外中断,但是我们设置了断点并且进行保存,那么我们下面就进行恢复, 从断点处进行训练,也就是上面的第 6 个 epoch 开始,我们看看怎么恢复断点训练: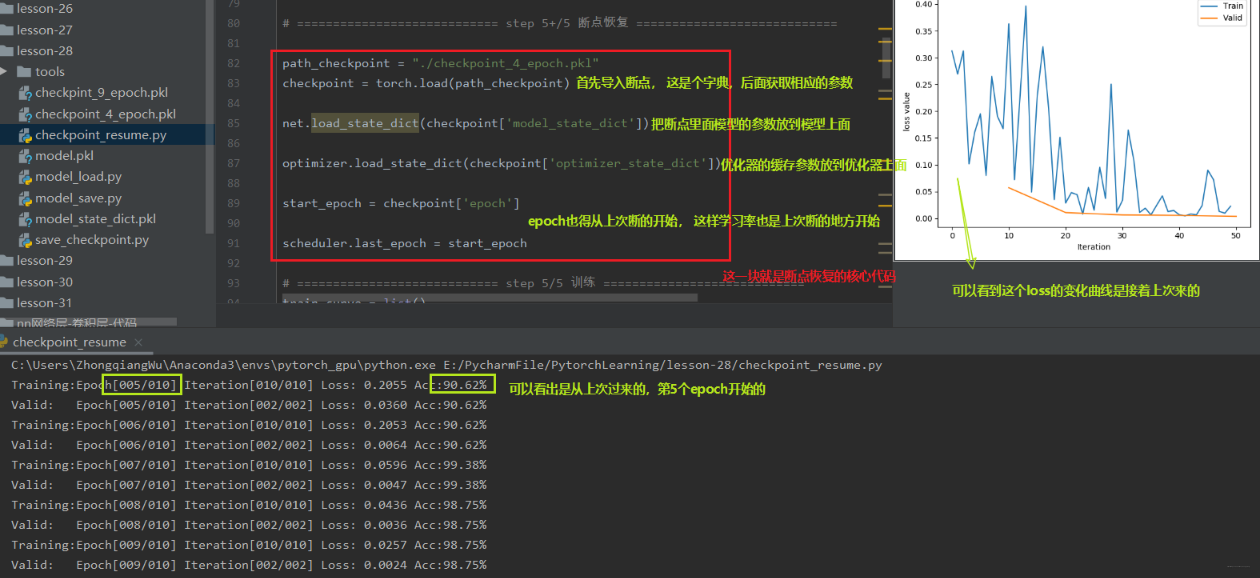
所以在模型的训练过程当中, 以一定的间隔去保存我们的模型,保存断点,在断点里面不仅要保存模型的参数,还要保存优化器的参数。这样才可以在意外中断之后恢复训练。
2. 模型的 finetune
在说模型的 finetune 之前,得先知道一个概念,就是迁移学习。
迁移学习: 机器学习分支, 研究源域的知识如何应用到目标域,将源任务中学习到的知识运用到目标任务当中,用来提升目标任务里模型的性能。
所以,当我们某个任务的数据比较少的时候,没法训练一个好的模型时, 就可以采用迁移学习的思路,把类似任务训练好的模型给迁移过来,由于这种模型已经在原来的任务上训练的差不多了,迁移到新任务上之后,只需要微调一些参数,往往就能比较好的应用于新的任务, 当然我们需要在原来模型的基础上修改输出部分,毕竟任务不同,输出可能不同。 这个技术非常实用。 但是一定要注意,类似任务上模型迁移(不要试图将一个 NLP 的模型迁移到 CV 里面去)
模型微调的步骤:
- 获取预训练模型参数(源任务当中学习到的知识)
- 加载模型(
load_state_dict)将学习到的知识放到新的模型 - 修改输出层, 以适应新的任务
模型微调的训练方法:
- 固定预训练的参数(
requires_grad=False; lr=0) Features Extractor较小学习率(params_group)
好了,下面就通过一个例子,看看如何使用模型的finetune:
下面使用训练好的 ResNet-18 进行二分类: 让模型分出蚂蚁和蜜蜂:
训练集 120 张, 验证集 70 张,所以我们可以看到这里的数据太少了,如果我们新建立模型进行训练预测,估计没法训练。所以看看迁移技术, 我们用训练好的 ResNet-18 来完成这个任务。
首先我们看看 ResNet-18 的结构,看看我们需要在哪里进行改动: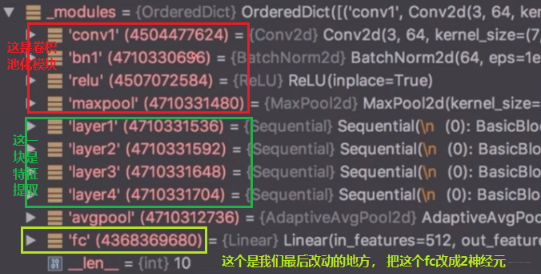
下面看看具体应该怎么使用: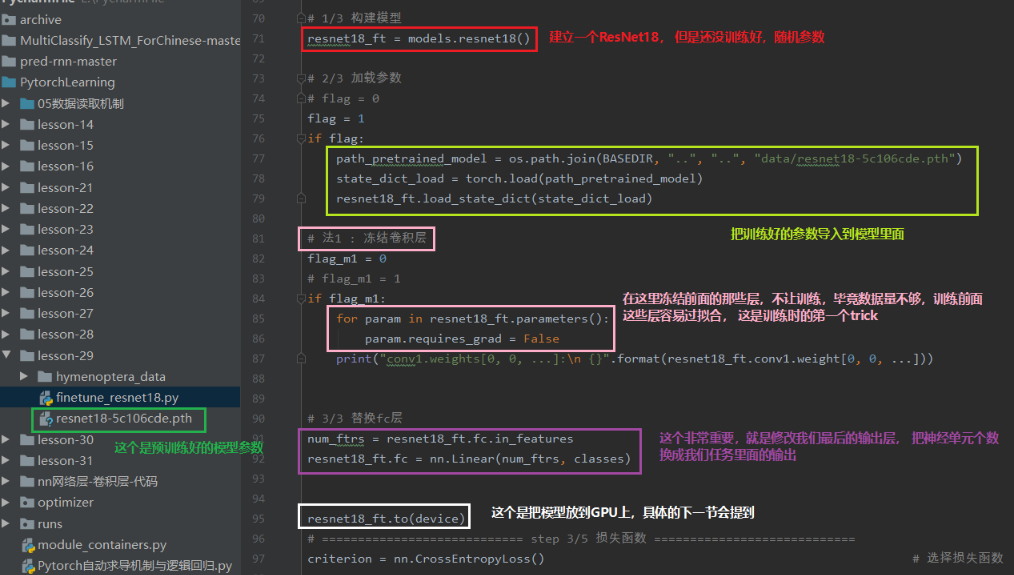
当然,训练时的 trick(技巧) 还有第二个,就是不冻结前面的层,而是修改前面的参数学习率,因为我们的优化器里面有参数组的概念,我们可以把网络的前面和后面分成不同的参数组,使用不同的学习率进行训练,当前面的学习率为 0 的时候,就是和冻结前面的层一样的效果了,但是这种写法比较灵活。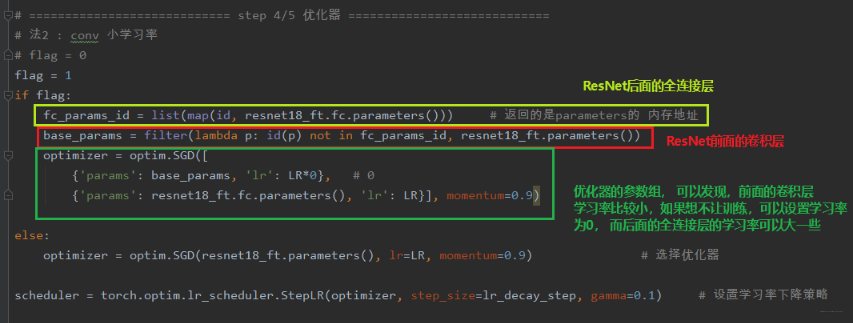
通过模型的迁移,可以发现这个任务就会完成的比较好。
3. GPU的使用
3.1 CPU VS GPU
CPU(Central Processing Unit, 中央处理器): 主要包括控制器和运算器
GPU(Graphics Processing Unit, 图形处理器): 处理统一的, 无依赖的大规模数据运算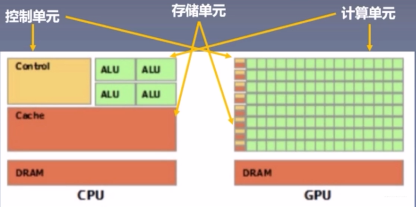
3.2 数据迁移至GPU
首先, 这个数据主要有两种: Tensor和Module
- CPU -> GPU:
data.to("cpu") - GPU -> CPU:
data.to("cuda")
**to** 函数: 转换数据类型/设备
1. tensor.to(*args, **kwargs)
x = torch.ones((3,3))x = x.to(torch.float64) # 转换数据类型x = torch.ones((3,3))x = x.to("cuda") # 设备转移
2. module.to(*args, **kwargs)
linear = nn.Linear(2,2)linear.to(torch.double) # 这样模型里面的可学习参数的数据类型变成float64gpu1 = torch.device("cuda")linear.to(gpu1) # 把模型从CPU迁移到GPU
上面两个方法的区别: 张量不执行 **inplace**, 所以上面看到需要等号重新赋值,而模型执行 **inplace**, 所以不用等号重新赋值。下面从代码中学习上面的两个方法: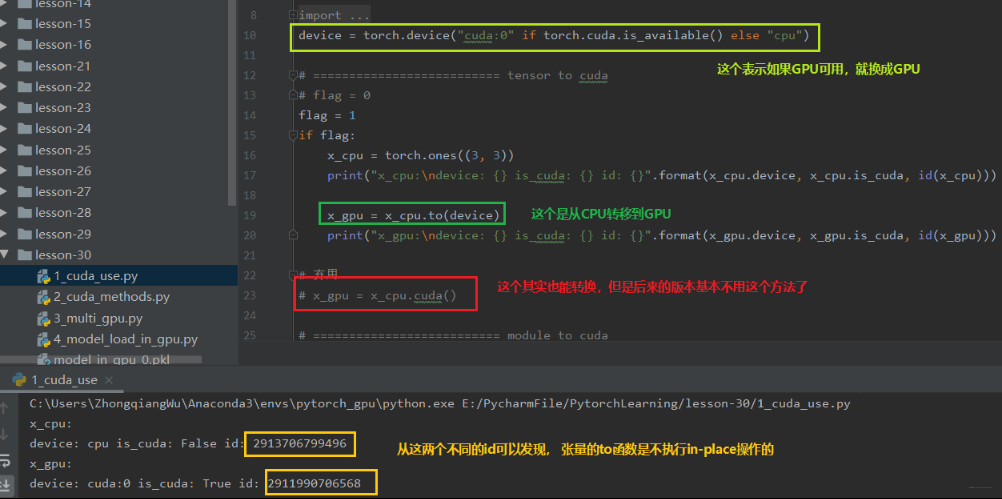
下面看一下 Module 的 to 函数: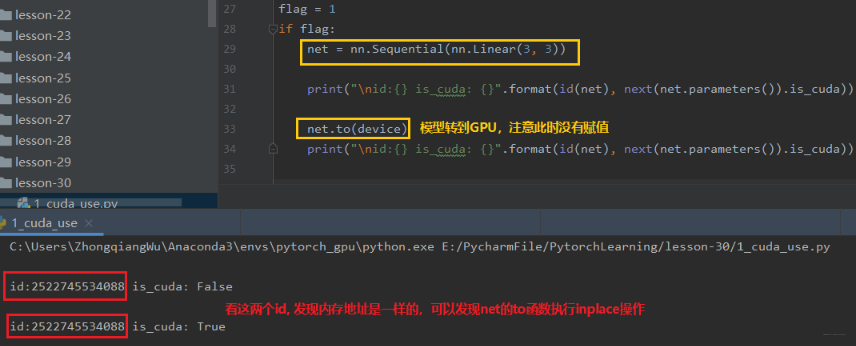
如果模型在GPU上, 那么数据也必须在GPU上才能正常运行。也就是说数据和模型必须在相同的设备上。
torch.cuda 常用的方法:
torch.cuda.device_count():计算当前可见可用的 GPU 数。torch.cuda.get_device_name():获取 GPU 名称。torch.cuda.manual_seed():为当前 GPU 设置随机种子。torch.cuda.manual_seed_all():为所有可见可用 GPU 设置随机种子。torch.cuda.set_device():设置主 GPU(默认GPU )为哪一个物理GPU(不推荐)。
推荐的方式是设置系统的环境变量:**os.environ.setdefault("CUDA_VISIBLE_DEVICES", "2,3")** 通过这个方法合理的分配 GPU ,使得多个人使用的时候不冲突。 但是这里要注意一下, 这里的 2,3 指的是物理 GPU 的 2,3 。但是在逻辑 GPU 上, 这里表示的 0,1 。 这里看一个对应关系吧: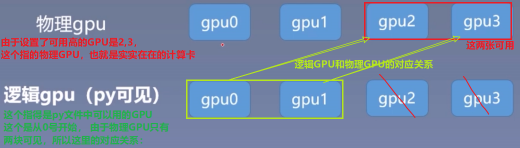
那么假设我这个地方设置的物理 GPU 的可见顺序是 0,3,2 呢? 物理 GPU 与逻辑 GPU 如何对应?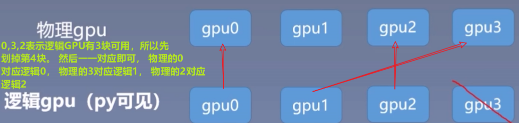
这个到底干啥用呢? 在逻辑 GPU 中,我们有个主 GPU 的概念,通常指的是 GPU0 。 而这个主 GPU 的概念,在多 GPU 并行运算中就有用了。
3.3 多GPU并行运算
多 GPU 并且运算, 简单的说就是我又很多块 GPU ,比如 4 块, 而这里面有个主 GPU , 当拿到样本数据之后,比如主 GPU 拿到了16 个样本, 那么它会经过 16/4=4 的运算,把数据分成 4 份, 自己留一份,然后把那 3 份分发到另外 3 块 GPU 上进行运算, 等其他的 GPU 运算完了之后, 主 GPU 再把结果收回来负责整合。 这时候看到主 GPU 的作用了吧。多 GPU 并行运算可以大大节省时间。所以, 多 GPU 并行运算的三步:分发 -> 并行计算 -> 收回结果整合。
Pytorch 中的多 GPU 并行运算机制如何实现呢?**torch.nn.DataParallel**:包装模型,实现分发并行机制。
主要参数:
module:需要包装分发的模型。device_ids:可分发的 gpu ,默认分发到所有的可见可用 GPU,通常这个参数不管它,而是在环境变量中管这个。output_device:结果输出设备, 通常是输出到主 GPU 。
下面从代码中看看多 GPU 并行怎么使用: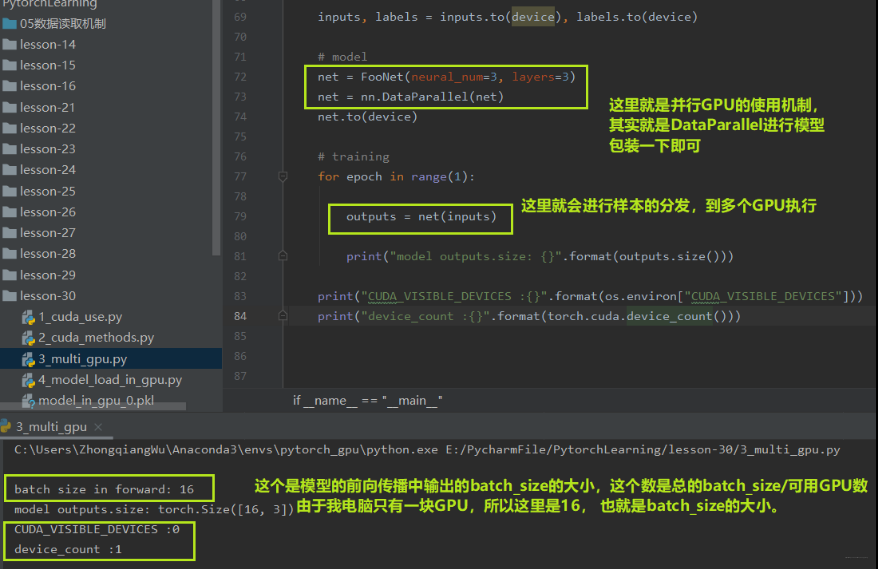
由于这里没有多 GPU ,所以可以看看在多 GPU 服务器上的一个运行结果:
下面这个代码是多 GPU 的时候,查看每一块 GPU 的缓存,并且排序作为逻辑 GPU 使用, 排在最前面的一般设置为我们的主 GPU :
def get_gpu_memory():import platformif 'Windows' != platform.system():import osos.system('nvidia-smi -q -d Memory | grep -A4 GPU | grep Free > tmp.txt')memory_gpu = [int(x.split()[2]) for x in open('tmp.txt', 'r').readlines()]os.system('rm tmp.txt')else:memory_gpu = Falseprint("显存计算功能暂不支持windows操作系统")return memory_gpugpu_memory = get_gpu_memory()if not gpu_memory:print("\ngpu free memory: {}".format(gpu_memory))gpu_list = np.argsort(gpu_memory)[::-1]gpu_list_str = ','.join(map(str, gpu_list))os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
在 GPU 模型加载当中常见的两个问题:
这个报错是我们的模型是以 cuda 的形式进行保存的,也就是在 GPU 上训练完保存的,保存完了之后我们想在一个没有 GPU 的机器上使用这个模型,就会报上面的错误。 所以解决办法就是:**torch.load(path_state_dict, map_location="cpu")**,这样既可以在 CPU 设备上加载 GPU 上保存的模型了。
这个报错信息是出现在我们用多 GPU 并行运算的机制训练好了某个模型并保存,然后想再建立一个普通的模型使用保存好的这些参数,就会报这个错误。 这是因为我们在多 GPU 并行运算的时候,我们的模型 net 先进行一个并行的一个包装,这个包装使得每一层的参数名称前面会加了一个 module 。 这时候,如果我们想把这些参数移到我们普通的 net 里面去,发现找不到这种 module. 开头的这些参数,即匹配不上,因为我们普通的 net 里面的参数是没有前面的 module 的。这时候我们就需要重新创建一个字典,把名字改了之后再导入。
我们首先先在多 GPU 的环境下,建立一个网络,并且进行包装,放到多 GPU 环境上训练保存: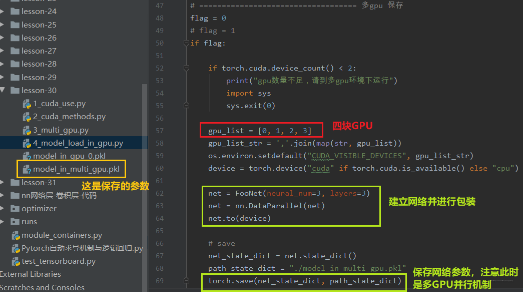
下面主要是看看加载的时候是怎么报错的: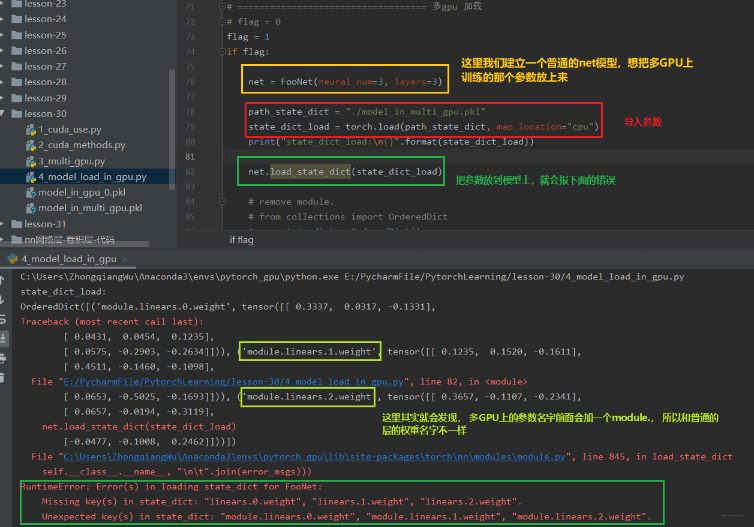
那么怎么解决这种情况呢? 下面这几行代码就可以搞定了:
from collections import OrderedDictnew_state_dict = OrderedDict()for k, v in state_dict_load.items():namekey = k[7:] if k.startswith('module.') else knew_state_dict[namekey] = vprint("new_state_dict:\n{}".format(new_state_dict))net.load_state_dict(new_state_dict)
下面看看效果: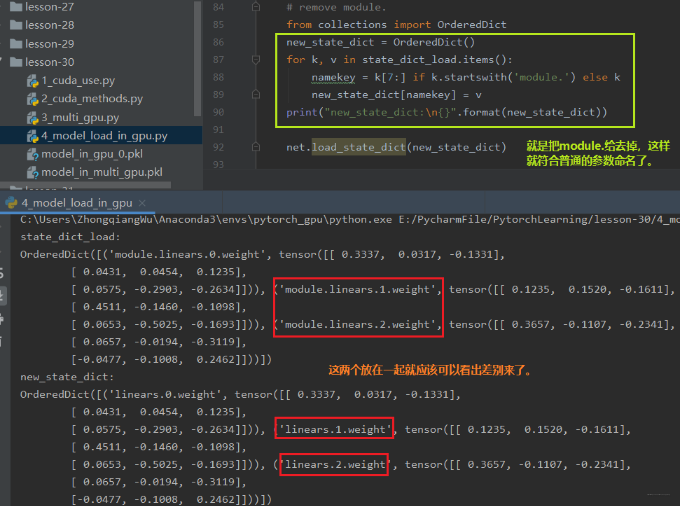

若有收获,就点个赞吧
0 人点赞
