参考来源:
博客园:【零基础】神经网络优化之 mini-batch
CSDN:mini batch 详解
1. 前言
回顾一下两种解决过拟合的方法:
**L0**、**L1**、**L2**:在向前传播、反向传播后面加个小尾巴。**dropout**:训练时随机“删除”一部分神经元。
本篇要介绍的优化方法叫 **mini-batch**,它主要解决的问题是:实际应用时的训练数据往往都太大了,一次加载到电脑里可能内存不够,其次运行速度也很慢。那自然就想到说,不如把训练数据分割成好几份,一次学习一份不就行了吗?前辈们试了试发现不仅解决了内存不足的问题,而且网络“收敛”的速度更快了。由于 **mini-batch** 这么棒棒,自然是神经网络中非常重要的一个技术,但实际实现时你会发现“真的太简单了”。
2. 什么是 mini batch
这里先解释几个名词,可以帮助大家更好的理解 mini-batch :
- 之前我们都是一次将所有图片输入到网络中学习,这种做法就叫
**batch**梯度下降。 - 与
batch对应的另一种极端方法是每次就只输入一张图片进行学习,我们叫随机梯度下降。 - 介于
batch梯度下降和随机梯度下降之间的就是我们现在要整的,叫**mini-batch**梯度下降。
我们已知在梯度下降中需要对所有样本进行处理过后然后走一步,那么如果我们的样本规模的特别大的话效率就会比较低。假如有 500 万,甚至 5000 万个样本(在我们的业务场景中,一般有几千万行,有些大数据有 10 亿行)的话走一轮迭代就会非常的耗时。这个时候的梯度下降叫做 **full-batch**(全增量更新) 。 所以为了提高效率,我们可以把样本分成等量的子集。 例如我们把 100 万样本分成 1000 份, 每份 1000 个样本, 这些子集就称为 **mini batch** 。然后我们分别用一个 for 循环遍历这 1000 个子集。 针对每一个子集做一次梯度下降。 然后更新参数 **w** 和 **b** 的值。接着到下一个子集中继续进行梯度下降。 这样在遍历完所有的 **mini batch** 之后我们相当于在梯度下降中做了 1000 次迭代。 我们将遍历一次所有样本的行为叫做一个 **epoch**,也就是一个世代。 在 **mini batch** 下的梯度下降中做的事情其实跟 **full batch** 一样,只不过我们训练的数据不再是所有的样本,而是一个个的子集。 这样在 **mini batch** 我们在一个 **epoch** 中就能进行 1000 次的梯度下降,而在 **full batch** 中只有一次。 这样就大大的提高了我们算法的运行速度。
3. mini batch 的效果
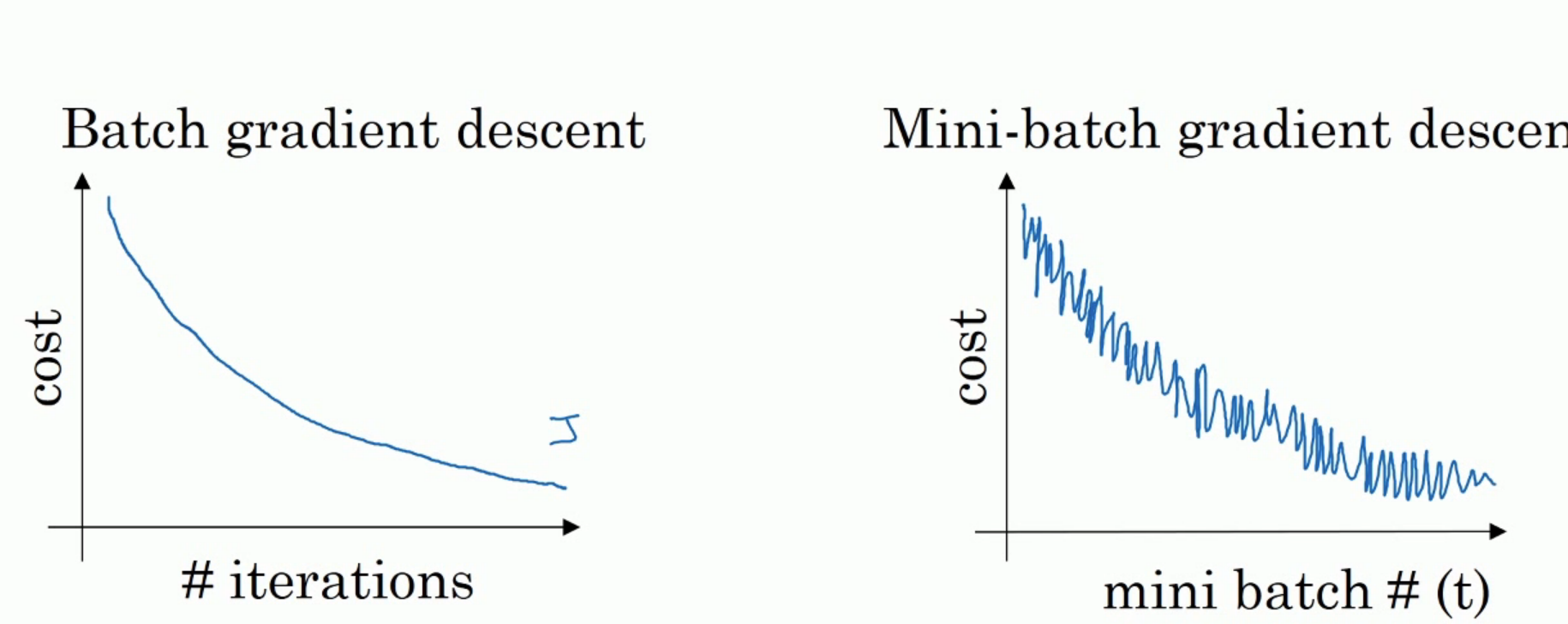
如上图,左边是 full batch 的梯度下降效果。 可以看到每一次迭代成本函数都呈现下降趋势,这是好的现象,说明我们 w 和 b 的设定一直再减少误差。 这样一直迭代下去我们就可以找到最优解。 右边是 mini batch 的梯度下降效果,可以看到它是上下波动的,成本函数的值有时高有时低,但总体还是呈现下降的趋势。 这个也是正常的,因为我们每一次梯度下降都是在 min batch 上跑的而不是在整个数据集上。 数据的差异可能会导致这样的效果(可能某段数据效果特别好,某段数据效果不好)。但没关系,因为他整体的是呈下降趋势的。
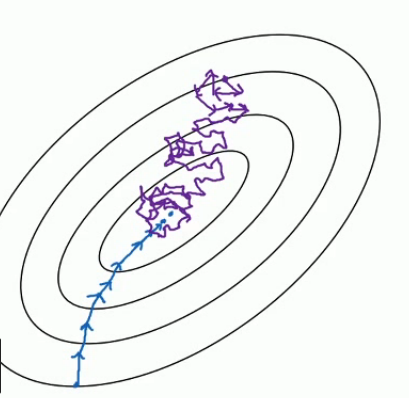
把上面的图看做是梯度下降空间。 下面的蓝色的部分是 full batch 的而上面是 mini batch 。 就像上面说的 mini batch 不是每次迭代损失函数都会减少,所以看上去好像走了很多弯路。 不过整体还是朝着最优解迭代的。 而且由于 mini batch 一个 epoch 就走了 5000 步,而 full batch 一个 epoch 只有 1 步。所以虽然 mini batch 走了弯路但还是会快很多。
4. mini-batch 大小、洗牌
既然有了 mini batch 那就会有一个 batch size 的超参数,也就是块大小。代表着每一个 mini batch 中有多少个样本。 实际上这没有什么特定标准的,但这个数值又切实影响着神经网络的训练效果,一般来说就是建议为 **2** 的 **n** 次方。 例如 64、128、512、1024,可以先随便设置一个数看看效果,效果一般再调调。一般不会超过这个范围。不能太大,因为太大了会无限接近 full batch 的行为,速度会慢。 也不能太小,太小了以后可能算法永远不会收敛。 当然如果我们的数据比较小, 但也用不着 mini batch 了。 full batch 的效果是最好的。
“洗牌”是 mini-batch 的一个附加选项,因为我们是将训练数据分割成若干份的,分割前将图片的顺序打乱就是所谓的“洗牌”了,这样每一次 mini-batch 学习的图片都不一样为网络中增加了一些随机的因素。具体原理上不知道有啥特别的,但实践中确实优化了网络。
5. mini-batch实现与对比
完整的实现代码是基于之前“深层神经网络解析”的,下载方式见文末。这里我做了个简单的实验,下图中分别是无 **mini-batch**、不带洗牌的 **mini-batch**、带洗牌的 **mini-batch** 运行效果。
无 mini-batch: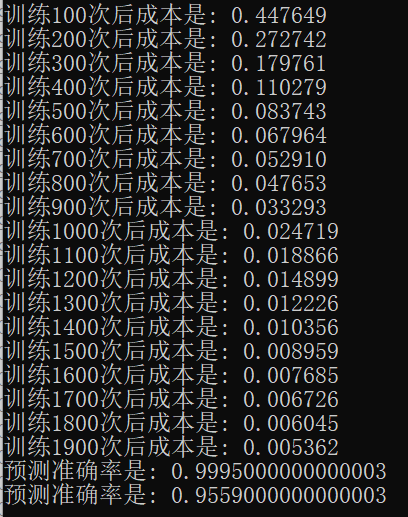
不带洗牌的 mini-batch :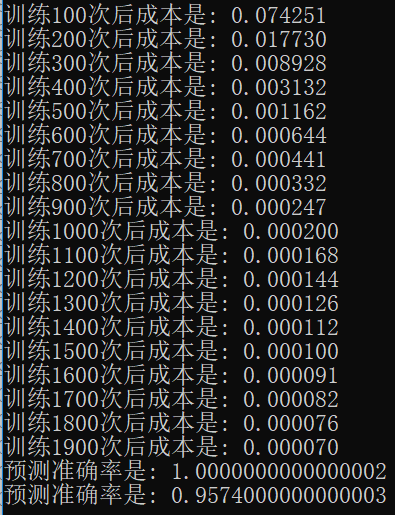
带洗牌的 mini-batch :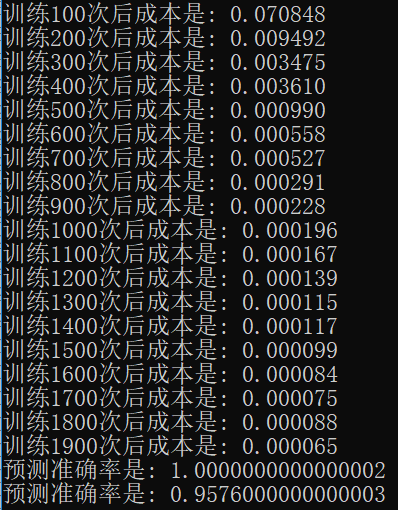
可以看到,使用 mini-batch 后网络可以迅速收敛。使用了 mini-batch 的网络仅用了 400 次就达到了普通网络 2000 次的训练效果。由于求解的问题不算很难,所以使用了洗牌的 mini-batch 与普通的 mini-batch 似乎没啥差别,不过还是能看出来效果还是好了一点的(不过会使用更长的时间来训练)。

若有收获,就点个赞吧
0 人点赞
