参考来源:
CSDN:机器学习之过拟合解决——早停法
过拟合解决——早停法
一、早停法简介(Early Stopping)
当我们训练深度学习神经网络的时候通常希望能获得最好的泛化性能(**generalization performance**,即可以很好地拟合数据)。但是所有的标准深度学习神经网络结构如全连接多层感知机都很容易过拟合:当网络在训练集上表现越来越好,错误率越来越低的时候,实际上在某一刻,它在测试集的表现已经开始变差。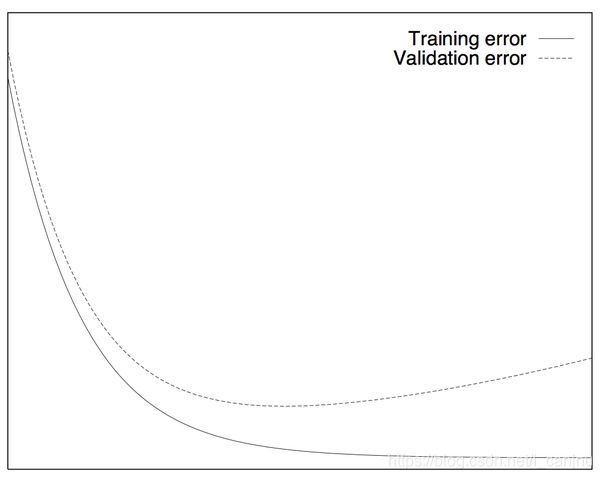
图 1、理想中的训练集误差和验证集的误差
模型的泛化能力通常使用模型在验证数据集/**validation set** 上的表现来评估。随着网络的优化,我们期望的理想中的泛化错误如图 1 所示。即当模型在训练集上的误差降低的时候,其在验证集上的误差表现不会变差。反之,当模型在训练集上表现很好,在验证集上表现很差的时候,我们认为模型出现了过拟合/overfitting 的情况。
解决过拟合问题有两个方向:降低参数空间的维度或者降低每个维度上的有效规模(effective size)。降低参数数量的方法包括**greedy constructive learning**、剪枝和权重共享等。降低每个参数维度的有效规模的方法主要是正则化,如权重衰变(**weight decay**) 和 早停法(**early stopping**) 等。
早停法是一种被广泛使用的方法,在很多案例上都比正则化的方法要好。图 1 是我们经常看到论文中出现的图,也是使用早停法出现的一个结果。其基本含义是在训练中计算模型在验证集上的表现,当模型在验证集上的表现开始下降的时候,停止训练,这样就能避免继续训练导致过拟合的问题。其主要步骤如下:
- 将原始的训练数据集划分成训练集和验证集。
- 只在训练集上进行训练,并每个一个周期计算模型在验证集上的误差,例如,每
15次epoch(mini batch训练中的一个周期)。 - 当模型在验证集上的误差比上一次训练结果差的时候停止训练。
- 使用上一次迭代结果中的参数作为模型的最终参数。
然而,在现实中,模型在验证集上的误差不会像上图那样平滑,而是像下图一样:

图 2、真实的验证集误差变化曲线
也就是说,模型在验证集上的表现可能咱短暂的变差之后有可能继续变好。上图在训练集迭代到 400 次的时候出现了 16 个局部最低。其中有4个最低值是它们所在位置出现的时候的最低点。其中全局最优大约出现在第 205 次迭代中。首次出现最低点是第 45 次迭代。相比较第 45 次迭代停止,到第 400 次迭代停止的时候找出的最低误差比第 45 次提高了 1.1% ,但是训练时间大约是前者的 7 倍。
但是,并不是所有的误差曲线都像上图一样,有可能在出现第一次最低点之后,后面再也没有比当前最低点更低的情况了。所以我们看到,早停法主要是训练时间和泛化错误之间的权衡。尽管如此,也有某些停止标准也可以帮助我们寻找更好的权衡。
二、如何使用早停法
我们需要一个停止的标准来实施早停法,因此,我们希望它可以产生最低的泛化错误,同时也可以有最好的性价比,即给定泛化错误下的最小训练时间 。
2.1、停止标准简介
早停标准有很多种,也很灵活,大约有三种。在给出早停法的具体标准之前,我们先确定一下符号。假的我们使用 **E** 作为训练函数的误差函数,那么 **Etr(t)** 是训练数据上的误差,**Eva(t)** 是训练数据上的误差,**Ete(t)** 是测试集上的误差。实际情况下我们并不能知道泛化误差,因此我们使用验证集误差来估计它。
第一类停止标准
假设 **Eopt(t)** 是在迭代次数为 **t** 时取得最好的验证集误差:
我们定义一个新变量叫泛化损失(**generalization loss**),它描述的是在当前迭代周期 t 中,泛化误差相比较目前的最低的误差的一个增长率:
较高的泛化损失显然是停止训练的一个候选标准,因为它直接表明了过拟合。这就是第一类的停止标准,即当泛化损失超过一定阈值的时候,停止训练。我们用 GLα 来定义,即当 GLα 大于一定值 α 的时候,停止训练。
第二类停止标准
然而,当训练的速度很快的时候,我们可能希望模型继续训练。因为如果训练错误依然下降很快,那么泛化损失有很大概率被修复。我们通常会假设过拟合只会在训练错误降低很慢的时候出现。在这里,我们定义一个 **k** 周期,以及基于周期的一个新变量度量进展(**measure progress**):

它表达的含义是,当前的指定迭代周期内的平均训练错误比该期间最小的训练错误大多少。注意,当训练过程不稳定的时候,这个 **measure progress** 结果可能很大,其中训练错误会变大而不是变小。实际中,很多算法都由于选择了不适当的较大的步长而导致这样的抖动。除非全局都不稳定,否则在较长的训练之后,**measure progress** 结果趋向于 0(其实这个就是度量训练集错误在某段时间内的平均下降情况)。由此,我们引入了第二个停止标准,即泛化损失和进展的商 PQ**α** 大于指定值的时候停止,即 。
。
第三类停止标准
第三类停止标准则完全依赖于泛化错误的变化,即当泛化错误在连续 **s** 个周期内增长的时候停止(**UP**)。
当验证集错误在连续 **s** 个周期内出现增长的时候,我们假设这样的现象表明了过拟合,它与错误增长了多大独立。这个停止标准可以度量局部的变化,因此可以用在剪枝算法中,即在训练阶段,允许误差可以比前面最小值高很多时候保留。
2.2 停止标准选择规则
一般情况下,“较慢”的标准会相对而言在平均水平上表现略好,可以提高泛化能力。然而,这些标准需要较长的训练时间。其实,总体而言,这些标准在系统性的区别很小。主要选择规则包括:
- 除非较小的提升也有很大价值,否则选择较快的停止标准。
- 为了最大可能找到一个好的方案,使用
**GL**标准。 - 为了最大化平均解决方案的质量,如果网络只是过拟合了一点点,可以使用
**PQ**标准,否则使用**UP**标准

若有收获,就点个赞吧
0 人点赞
