参考来源:
博客园:PyTorch笔记之 scatter() 函数
Pytorch 文档:https://pytorch.org/docs/stable/generated/torch.Tensor.scatter_.html
CSDN:pytorch之torch.gather方法
Pytorch 文档:https://pytorch.org/docs/stable/generated/torch.gather.html
scatter() 和 gather() 函数是互为反操作。
torch.tensor.scatter() 和 torch.tensor.scatter_() 函数
**scatter()** 和 **scatter_()** 的作用是一样的,只不过 scatter() 不会直接修改原来的 Tensor,而 scatter_() 会。
PyTorch 中,一般函数加下划线代表直接在原来的 Tensor 上修改。
**Tensor.scatter_(dim, index, src, reduce=None) → Tensor** 的主要参数有 3 个:
**dim**:沿着哪个维度进行索引。**index**:用来scatter的元素索引。**src**:用来scatter的源元素,可以是一个标量或一个张量。reduce:要应用的归约运算,可以是'add'(加)或'multiply'(乘)。( reduction operation to apply, can be either ‘add’ or ‘multiply’.)这个
scatter可以理解成放置元素或者修改元素。
简单说就是通过一个张量 src 来修改另一个张量 x,哪个元素需要修改、用 **src** 中的哪个元素来修改,由 **dim** 和 **index** 决定。
官方文档给出了 3 维张量 的具体操作说明,如下所示(**reduce = None**):
self[index[i][j][k]][j][k] = src[i][j][k] # if dim == 0self[i][index[i][j][k]][k] = src[i][j][k] # if dim == 1self[i][j][index[i][j][k]] = src[i][j][k] # if dim == 2
reduce = 'add'self[index[i][j][k]][j][k] += src[i][j][k] # if dim == 0self[i][index[i][j][k]][k] += src[i][j][k] # if dim == 1self[i][j][index[i][j][k]] += src[i][j][k] # if dim == 2reduce = 'multiply'self[index[i][j][k]][j][k] *= src[i][j][k] # if dim == 0self[i][index[i][j][k]][k] *= src[i][j][k] # if dim == 1self[i][j][index[i][j][k]] *= src[i][j][k] # if dim == 2
例子:
import torchsrc = torch.rand(2, 5)index = torch.tensor([[0, 1, 2, 0, 0], [2, 0, 0, 1, 2]])dim = 0x = torch.zeros(3, 5)y = x.scatter(dim, index, src)print('dim:\t', dim)print('index:\n', index)print('src:\n', src)print('x:\n', x)print("'x.scatter(dim, index, src)':\n", y)
结果:
dim: 0index:tensor([[0, 1, 2, 0, 0],[2, 0, 0, 1, 2]])src:tensor([[0.4963, 0.7682, 0.0885, 0.1320, 0.3074],[0.6341, 0.4901, 0.8964, 0.4556, 0.6323]])x:tensor([[0., 0., 0., 0., 0.],[0., 0., 0., 0., 0.],[0., 0., 0., 0., 0.]])'x.scatter_(dim, index, src)':tensor([[0.4963, 0.4901, 0.8964, 0.1320, 0.3074],[0.0000, 0.7682, 0.0000, 0.4556, 0.0000],[0.6341, 0.0000, 0.0885, 0.0000, 0.6323]])
具体地说,我们的 index 是 torch.tensor([[0, 1, 2, 0, 0], [2, 0, 0, 1, 2]]),一个二维张量,下面用图简单说明 **self[index[i][j]][j]=src[i][j]**:
我们是 2维 张量,一开始进行 self[index[0][0]][0],其中 index[0][0] 的值是0,所以执行 self[0][0]=src[0][0]=0.1940 。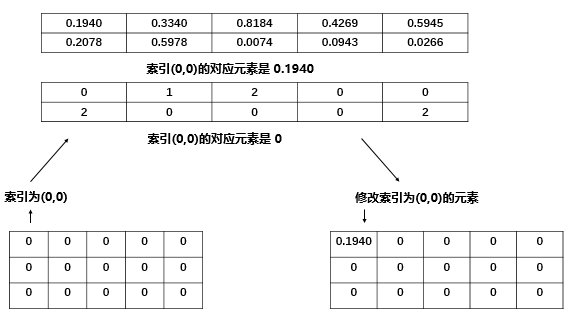
再比如 self[index[1][0]][0],其中 index[1][0] 的值是2,所以执行 self[2][0] = src[1][0] = 0.2078 。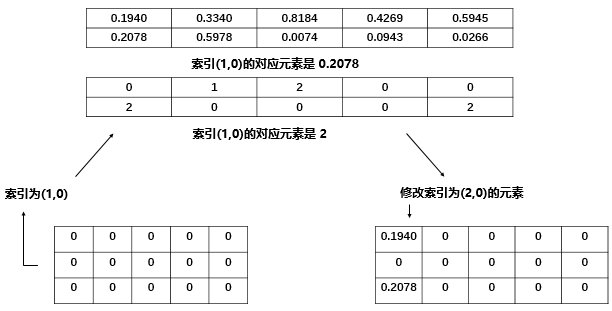
**src** 除了可以是张量外,也可以是一个标量。
例子:
import torchsrc = 7index = torch.tensor([[0, 1, 2, 0, 0], [2, 0, 0, 1, 2]])dim = 0x = torch.zeros(3, 5)y = x.scatter(dim, index, src)print('dim:\t', dim)print('index:\n', index)print('src:\t', src)print('x:\n', x)print("'x.scatter(dim, index, src)':\n", y)
结果:
dim: 0index:tensor([[0, 1, 2, 0, 0],[2, 0, 0, 1, 2]])src: 7x:tensor([[0., 0., 0., 0., 0.],[0., 0., 0., 0., 0.],[0., 0., 0., 0., 0.]])'x.scatter_(dim, index, src)':tensor([[7., 7., 7., 7., 7.],[0., 7., 0., 7., 0.],[7., 0., 7., 0., 7.]])
scatter() 一般可以用来对标签进行 one-hot 编码,这就是一个典型的用标量来修改张量的一个例子。
例子:
import torchclass_num = 10batch_size = 4label = torch.LongTensor(batch_size, 1).random_() % class_numy = torch.zeros(batch_size, class_num).scatter(1, label, 1)print('label:\n', label)print("'torch.zeros(batch_size, class_num).scatter(1, label, 1)':\n", y)
结果:
label:tensor([[5],[0],[9],[7]])'torch.zeros(batch_size, class_num).scatter(1, label, 1)':tensor([[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],[0., 0., 0., 0., 0., 0., 0., 1., 0., 0.]])
torch.gather() 函数
首先,先给出 torch.gather 函数的函数定义:
**torch.gather(input, dim, index, out=None) → Tensor**
官方给出的解释是这样的: 沿给定轴 dim,将输入索引张量 index 指定位置的值进行聚合。
官方文档给出了 3 维张量 的具体操作说明,如下所示:
out[i][j][k] = tensor[index[i][j][k]][j][k] # dim=0out[i][j][k] = tensor[i][index[i][j][k]][k] # dim=1out[i][j][k] = tensor[i][j][index[i][j][k]] # dim=3
!!!特别注意一下,**index** 的类型必须是 **LongTensor** 类型的。
刚开始看上去有点难以理解,但经过研究之后发现原来这个想表述的很简单,先给出几个代码例子让大家自行体会一下。
import torcha = torch.Tensor([[1, 2], [3, 4]])index = torch.LongTensor([[0, 0], [1, 0]])b = torch.gather(input=a, dim=1, index=index)print('a:\n', a)print('index:\n', index)print("'torch.gather(input=a, dim=1, index=index)':\n", b)"""output:a:tensor([[1., 2.],[3., 4.]])index:tensor([[0, 0],[1, 0]])'torch.gather(input=a, dim=1, index=index)':tensor([[1., 1.],[4., 3.]])"""
import torcha = torch.Tensor([[1, 2], [3, 4]])index = torch.LongTensor([[1, 0], [1, 0]])b = torch.gather(input=a, dim=1, index=index)print('a:\n', a)print('index:\n', index)print("'torch.gather(input=a, dim=1, index=index)':\n", b)"""output:a:tensor([[1., 2.],[3., 4.]])index:tensor([[1, 0],[1, 0]])'torch.gather(input=a, dim=1, index=index)':tensor([[2., 1.],[4., 3.]])"""
import torcha = torch.Tensor([[1, 2], [3, 4]])index = torch.LongTensor([[1, 1], [1, 0]])b = torch.gather(input=a, dim=1, index=index)print('a:\n', a)print('index:\n', index)print("'torch.gather(input=a, dim=1, index=index)':\n", b)"""output:a:tensor([[1., 2.],[3., 4.]])index:tensor([[1, 1],[1, 0]])'torch.gather(input=a, dim=1, index=index)':tensor([[2., 2.],[4., 3.]])"""
很容易就会发现 **torch.gather(input, dim, index, out=None)** 中的 dim 表示的就是第几维度,在这个二维例子中,如果 **dim=0**,那么它表示的就是你接下来的操作是对于第一维度进行的,也就是行;如果 **dim=1**,那么它表示的就是你接下来的操作是对于第二维度进行的,也就是列。**index** 的大小和 **input** 的大小是一样的,他表示的是你所选择的维度上的操作,比如这个例子中
a = torch.Tensor([[1,2],[3,4]])、b = torch.gather(a,1,torch.LongTensor([[0,0],[1,0]])),其中, dim=1,表示的是在第二维度上操作。index = torch.LongTensor([[0,0],[1,0]]),[0,0] 就是第一行对应元素的下标,也就是对应的是[1,1]; [1,0] 就是第二行对应元素的下标,也就是对应的是 [4,3]。

若有收获,就点个赞吧
0 人点赞
