参考来源:
CSDN:系统学习 Pytorch 笔记四:模型创建 Module、模型容器 Containers 及 AlexNet 网络搭建
1. Pytorch 模型的创建
在学习 Pytorch 的模型创建之前,我们依然是回顾一下模型创建到底是以什么样的逻辑存在的, 上一次,我们已经整理了机器模型学习的五大模块,分别是数据,模型,损失函数,优化器,迭代训练:
这里的模型创建是模型模块的一个分支,和数据模块一样,我们先看一下模型模块的具体内容: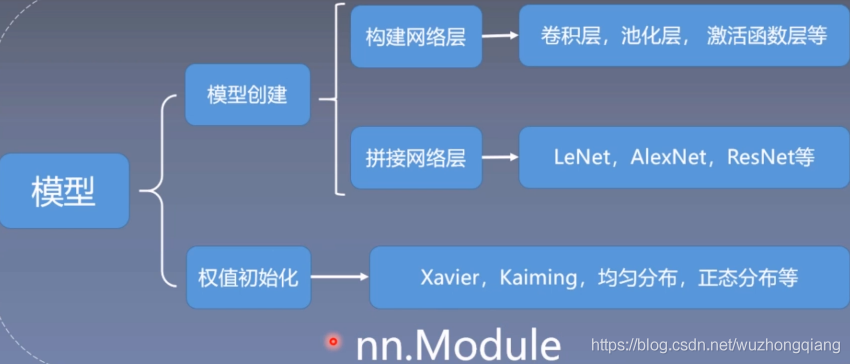
了解了上面这些框架,有利于把知识进行整合起来,到底学习的内容属于哪一块我们从上面的模型创建开始,学习网络层的构建和拼接。
1.1 模型的创建步骤
在模型创建步骤之前,我们先来进行一个分析,下面是我们在人民币二分类任务过程中用到的 LeNet 模型,我们可以看一下 LeNet 的组成。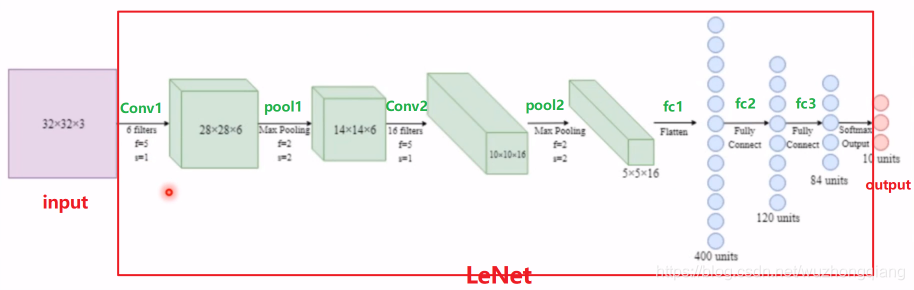
上面是 LeNet 的模型计算图,由边和节点组成,节点就是表示每个数据, 而边就是数据之间的运算。 我们可以发现,LeNet 是一个很大的网络,接收输入,然后经过运算得到输出, 在 LeNet 的内部,又分为很多个子网络层进行拼接组成,这些子网络层之间连接配合,最终完成我们想要的运算。
所以通过上面的分析,我们可以得到构建我们模型的两大要素:
- 构建子模块(比如 LeNet 里面的卷积层,池化层,全连接层)
- 拼接子模块(有了子模块,我们把子模块按照一定的顺序,逻辑进行拼接起来得到最终的 LeNet 模型)
下面还是以纸币二分类的任务去看看如何进行 LeNet 模型的构建,依然是使用代码调试: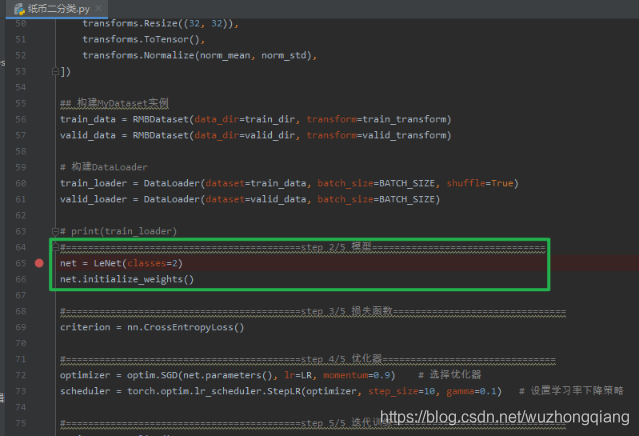
上一次是数据模块部分,这一次,我们进入模型模块的学习,这里可以看到,使用的模型是 LeNet , 我们模型这一行打上断点,然后进行 debug 调试,看看这个 LeNet 是怎么搭建起来的: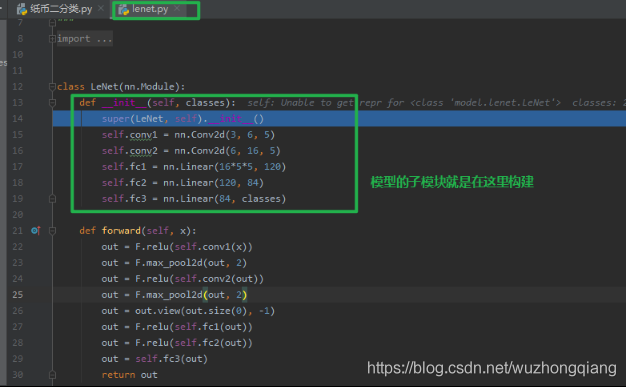
程序运行到断点,点击步入,就进入了lenet.py文件,在这里面有个 LeNet 类,继承了 nn.Module 。 并且我们发现在它的 **__init__** 方法里面实现了各个子模块的构建。所以构建模型的第一个要素 – 子模块的构建就是在这里。
下面的一个问题,就是我们知道了子模块是定义在 LeNet 模型 __init__ 方法里面,那么这些子模块的拼接是在哪里定义呢? 你可能一下子会说出来, 当然是在 forward 里面了, 如果真的是这样,那说明你会用 Pytorch 了。 如果不知道,那么我们可以想想, 我们定义的模型是在哪用到的呢? 只要用到了模型,必然会知道它是怎么拼接的,所以我们就从模型的训练那进行调试,看看是不是真的调用了 forward 方法进行模型拼接。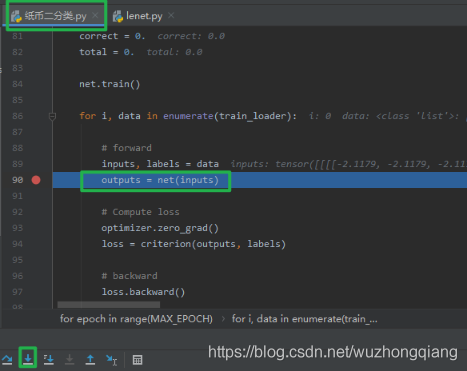
主程序的模型训练部分,我们在 outputs=net(inputs) 打上断点,因为这里开始是模型的训练部分, 而这一行代码正是前向传播, 我们进行步入,看看这个函数的运行原理: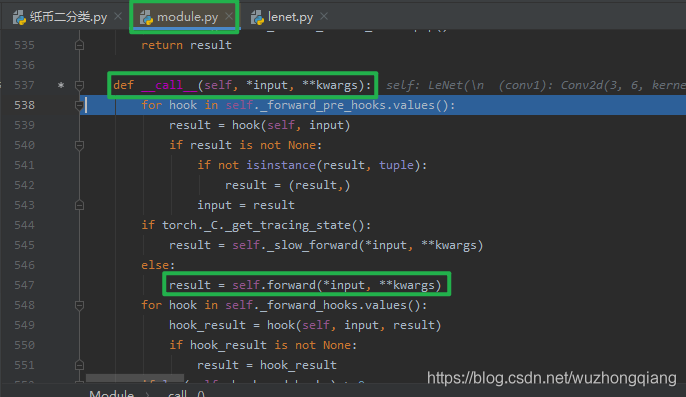
我们发现进入了 module.py 里面的一个 **__call__** 函数, 因为我们的 LeNet 是继承于 Module 的。在这里我们会发现有一行是调用了 LeNet 的 forward 方法。我们把鼠标放在这一行,然后运行到这里,再步入,就会发现果真是调用了 LeNet 的 forward 方法: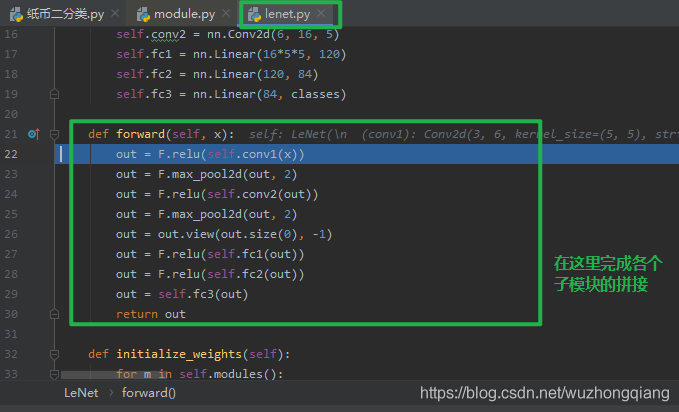
所以,我们基于这个例子,就基本上理清楚了上面构建模型的两个要素:
- 构建子模块, 这个是在自己建立的模型(继承 nn.Module)的
**__init__()**方法 - 拼接子模块, 这个是在模型的
**forward()**方法中
在模型的概念当中,我们有一个非常重要的概念叫做 **nn.Module** , 我们所有的模型,所有的网络层都是继承于这个类的。所以我们非常有必要了解 nn.Module 这个类。
1.2 nn.Module 类
在介绍 nn.Module 之前,我们先介绍与其相关的几个模块, 建立一个框架出来,看看 Module 这个模块在以一个什么样的逻辑存在, 这样的目的依然是把握宏观。
**torch.nn**:这是 Pytorch 的神经网络模块, 这里的 Module 就是它的子模块之一,另外还有几个与 Module 并列的子模块, 这些子模块协同工作,各司其职。
1.2.1 nn.Parameter
首先是 **nn.Parameter** , 在 Pytorch 中,模型的参数是需要被优化器训练的,因此,通常要设置参数为 **requires_grad = True** 的张量。同时,在一个模型中,往往有许多的参数,要手动管理这些参数并不是一件容易的事情。Pytorch 一般将参数用 **nn.Parameter** 来表示,并且用 **nn.Module** 来管理其结构下的所有参数。
## nn.Parameter 具有 requires_grad = True 属性w = nn.Parameter(torch.randn(2,2))print(w) # tensor([[ 0.3544, -1.1643],[ 1.2302, 1.3952]], requires_grad=True)print(w.requires_grad) # True## nn.ParameterList 可以将多个nn.Parameter组成一个列表params_list = nn.ParameterList([nn.Parameter(torch.rand(8,i)) for i in range(1,3)])print(params_list)print(params_list[0].requires_grad)## nn.ParameterDict 可以将多个nn.Parameter组成一个字典params_dict = nn.ParameterDict({"a":nn.Parameter(torch.rand(2,2)),"b":nn.Parameter(torch.zeros(2))})print(params_dict)print(params_dict["a"].requires_grad)
我们可以用 Module 把这些参数管理起来:
# module.parameters()返回一个生成器,包括其结构下的所有parametersmodule = nn.Module()module.w = wmodule.params_list = params_listmodule.params_dict = params_dictnum_param = 0for param in module.parameters():print(param,"\n")num_param = num_param + 1print("number of Parameters =",num_param)
实践当中,一般通过继承 nn.Module 来构建模块类,并将所有含有需要学习的参数的部分放在构造函数中。
#以下范例为Pytorch中nn.Linear的源码的简化版本#可以看到它将需要学习的参数放在了__init__构造函数中,并在forward中调用F.linear函数来实现计算逻辑。class Linear(nn.Module):__constants__ = ['in_features', 'out_features']def __init__(self, in_features, out_features, bias=True):super(Linear, self).__init__()self.in_features = in_featuresself.out_features = out_featuresself.weight = nn.Parameter(torch.Tensor(out_features, in_features))if bias:self.bias = nn.Parameter(torch.Tensor(out_features))else:self.register_parameter('bias', None)def forward(self, input):return F.linear(input, self.weight, self.bias)
1.2.2 nn.functional
**nn.functional**(一般引入后改名为F)有各种功能组件的函数实现。 比如:
- 激活函数系列(
**F.relu**,**F.sigmoid**,**F.tanh**,**F.softmax**) - 模型层系列(
**F.linear**,**F.conv2d**,**F.max_pool2d**,**F.dropout2d**,**F.embedding**) - 损失函数系列(
**F.binary_cross_entropy**,**F.mse_loss**,**F.cross_entropy**)
为了便于对参数进行管理, 一般通过继承 nn.Module 转换为类的实现形式, 并直接封装在 nn 模块下:
- 激活函数变成(
**nn.ReLu**,**nn.Sigmoid**,**nn.Tanh**,**nn.Softmax**) - 模型层(
**nn.Linear**,**nn.Conv2d**,**nn.MaxPool2d**,**nn.Embedding**) - 损失函数(
**nn.BCELoss**,**nn.MSELoss**,**nn.CrossEntorpyLoss**)
所以我们表面上用 nn 建立的这些激活函数, 层, 损失函数, 背后都在 functional 里面具体实现。 但是 nn.Module 这个模块确实非常强大, 除了可以管理其引用的各种参数,还可以管理其引用的子模块。 我们下面就来揭开 nn.Module 的神秘面纱。
1.2.3 nn.Module
今天的重点是 nn.Module 这个模块, 这里面是所有网络层的基类,管理有关网络的属性。
在 nn.Module 中,有 8 个重要的属性, 用于管理整个模型,他们都是以有序字典的形式存在着:
**_parameters**:存储管理属于 nn.Parameter 类的属性,例如权值,偏置这些参数**_modules**:存储管理 nn.Module 类, 比如 LeNet 中,会构建子模块,卷积层,池化层,就会存储在 _modules 中**_buffers**:存储管理缓冲属性, 如 BN 层中的 running_mean , std 等都会存在这里面*****_hooks**:存储管理钩子函数(5 个与 hooks 有关的字典,这个先不用管)
今天学习的重点是前 2 个, **_parameters** 和 **_modules**,下面通过 LeNet 模型代码来观察 nn.Module 的创建以及它对属性管理的一个机制。这里依然开启调试机制, 先在 pythonnet = LeNet(classes=2) 前打上断点,然后 debug 步入到 LeNet 。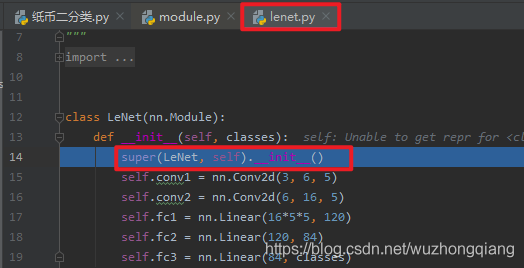
我们可以看到 LeNet 是继承于 nn.Module 的,所以 LeNet 也是一个 Module ,我们看看 **__init__** 方法中的第一行,是实现了父类函数调用的功能,在这里也就是调用了 nn.Module 的初始化函数。我们进入这一个 nn.Module 的 **__init__** 。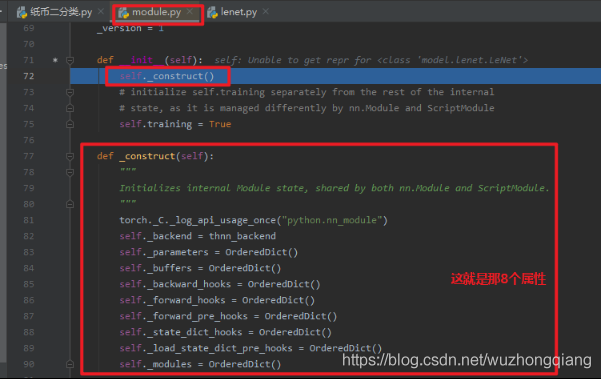
从 Module 类里面的初始化方法中,看到了会调用 _construct 方法实现了 8 个有序字典的一个初始化操作,也就是通过第一行代码,我们的 LeNet 模型就有了 8 个有序字典属性,去帮助我们存储后面的变量和参数。
我们跳回去, 继续往下运行第二行代码,建立第一个子模块卷积层,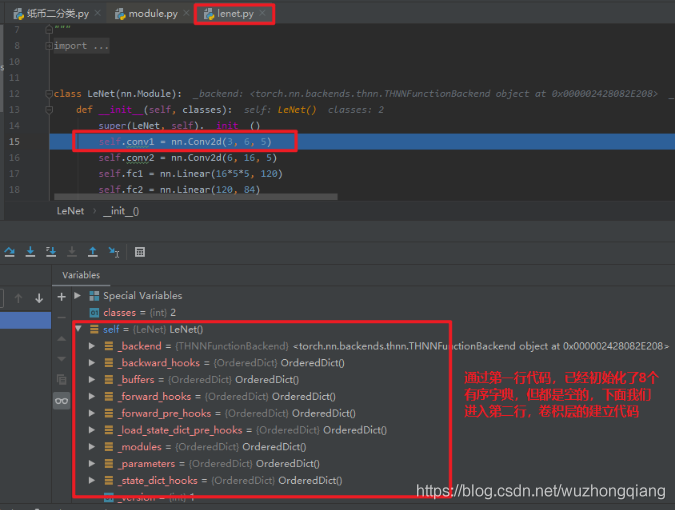
我们使用步入,进入到 **nn.Conv2d** 这个卷积层,我们会发现 **class Conv2d(_ConvNd):** 也就是这个类是继承于 **_ConvNd** 的,在 **Conv2d** 的初始化方法中,依然是先调用父类的初始化方法, 我们进入这个类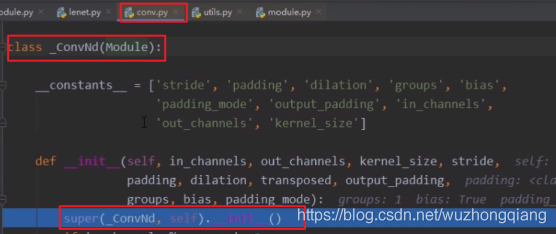
我们发现 **_ConvNd** 也是继承 Module 这个类的,并且初始化方法中也是用了 super 调用了父类的初始化方法。 所以这就说明 Conv2d 这个子模块是一个 Module ,并且也有那 8 个有序字典的属性。
然后我们再跳回去,准备运行第三行代码: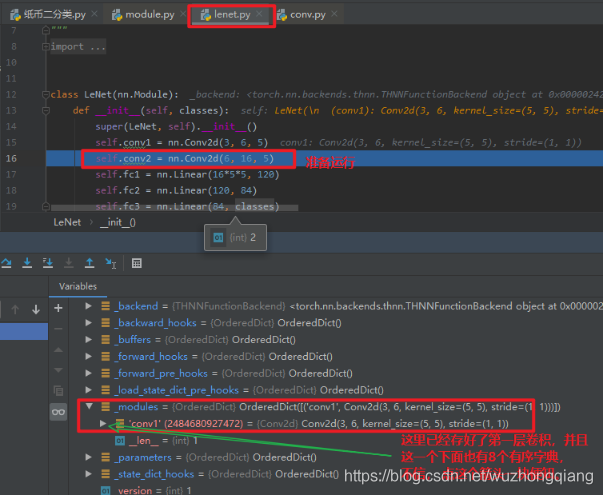
这时候第二行代码运行完了,也就是我们在 LeNet 中建立了第一个子模块 Conv2d , 那么我们可以看到 LeNet 的 **_modules** 这个有序字典中,就记录了这个子模块的信息。 因为这个 Conv2d 也是一个 Module ,所以它也有 8 个有序字典,但是它下面的 _modules 里面就是空的了,毕竟它没有子模块了。 但是它的 **_parameters** 这个字典里面不是空的,因为它有参数,这里会记录权重和偏置的参数信息。 还是点开上面的箭头看看吧: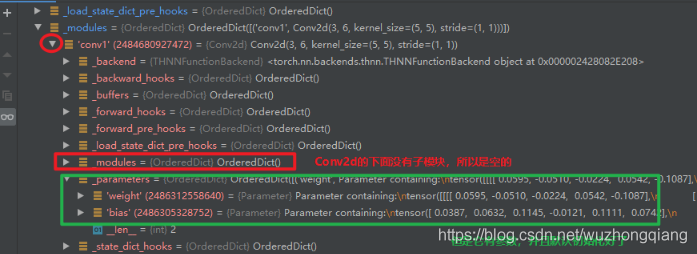
通过上面的调试,我们就看清楚了 LeNet 这个 Module 实现了一个子网络层的构建,并且把它存储到了 **_modules** 这个字典中进行管理。
下面通过构建第二个网络层来观察 LeNet 是如何将这个子模块 Conv2d 存储到这个 **_modules** 字典里面的?上面只是看了存进去了,但是我们不知道是咋存进去的啊? 这样也很不爽, 那就继续调试着, 继续 stepinto 步入第三行的 nn.Conv2d 。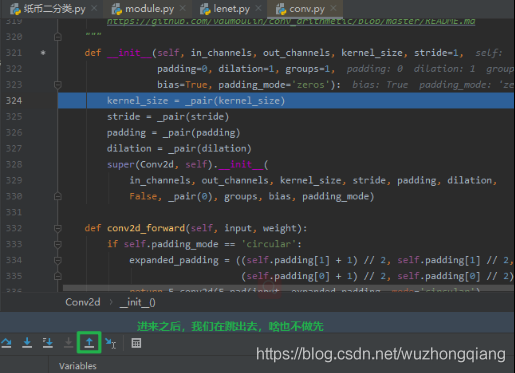
这次我们进来,先啥也不干, 直接跳回去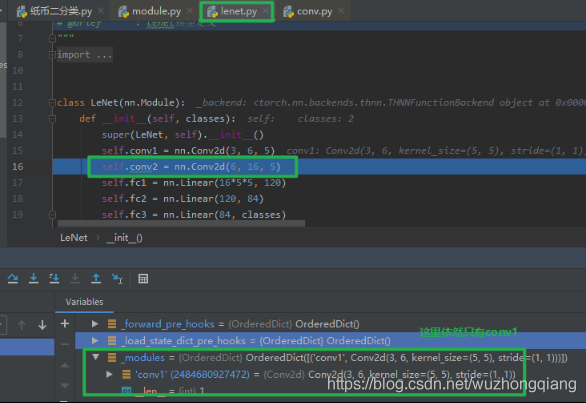
这时候我们会发现 LeNet 这个 Module 的 **_modules** 字典中依然只有 conv1 ,没有出现 conv2 , 这是因为目前只是通过初始化函数实现了一个 Conv2d 的一个实例化,还没有赋值到我们的 conv2 中,只是构建了这么一个网络层,下一步才是赋值到 conv2 这个上面,所以一个子模块的初始化和赋值是两步走的,第一步初始化完了之后,会被一个函数进行拦截,然后再进行第二步赋值, 那么这个函数是啥呢? 它又想干啥呢? 我们可以再次 stepinto 一下,进入这个函数,这次就直接到了这个函数里面(注意我们上面的第一次 stepinto 是跳到了 **__init__** 里面去初始化)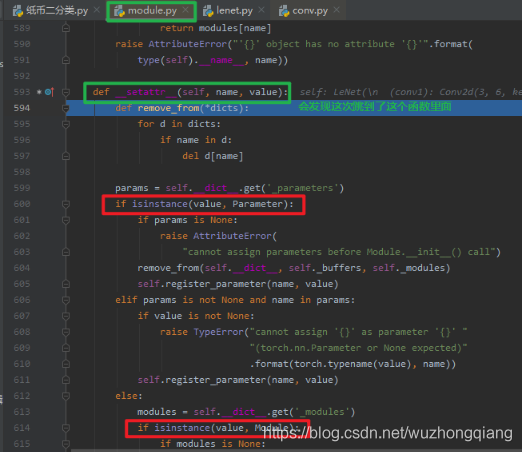
这次到了 **__setattr__** 这就是那个拦截的函数了,我们可以看看在干什么事情,这个方法接收了一个 value , 然后会判断 value 是什么样的类型, 如果是参数,就会保存到参数的有序字典,如果是 Module ,就会保存到模型的有序字典里面。 而这里的 conv2d 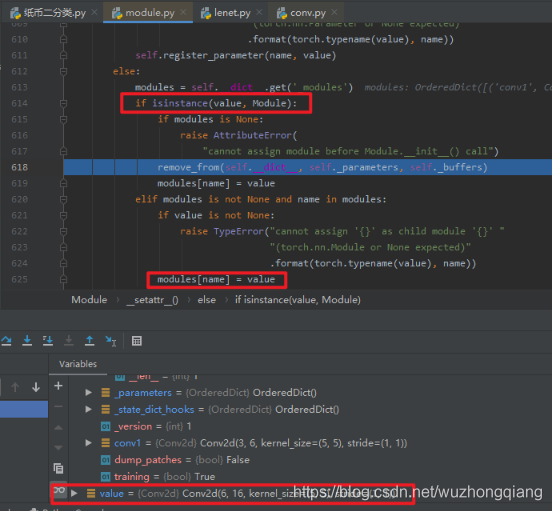
是一个 Module ,所以这个会存入到 **_modules** 字典中, name 就是这里的 conv2 。所以我们再跳回来就会发现 **_modules** 字典中有了 conv2 了。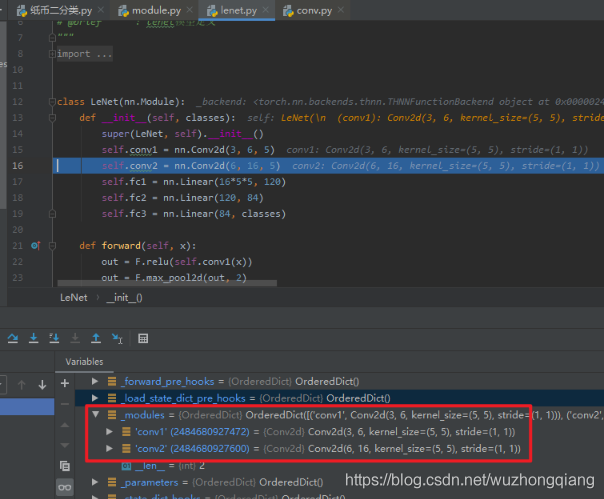
这样一步一步的运行下去。
这就是 nn.Module 构建属性的一个机制了,简单回顾一下,我们是先有一个大的 Module 继承 nn.Module 这个基类, 比如上面的 LeNet ,然后这个大的 Module 里面又可以有很多的子模块,这些子模块同样也是继承于 nn.Module , 在这些 Module 的 **__init__** 方法中,会先通过调用父类的初始化方法进行 8 个属性的一个初始化。 然后在构建每个子模块的时候,其实分为两步,第一步是初始化,然后被 **__setattr__** 这个方法通过判断 value 的类型将其保存到相应的属性字典里面去,然后再进行赋值给相应的成员。 这样一个个的构建子模块,最终把整个大的 Module 构建完毕。
下面对 nn.Module 进行总结:
- 一个 module 可以包含多个子 module( LeNet 包含卷积层,池化层,全连接层)
- 一个 module 相当于一个运算, 必须实现 forward() 函数(从计算图的角度去理解)
- 每个 module 都有 8 个字典管理它的属性(最常用的就是
**_parameters**,**_modules**)
一般情况下,我们都很少直接使用 **nn.Parameter** 来定义参数构建模型,而是通过一些拼装一些常用的模型层来构造模型。这些模型层也是继承自 **nn.Module** 的对象,本身也包括参数,属于我们要定义的模块的子模块。**nn.Module** 提供了一些方法可以管理这些子模块。
**children()**方法:返回生成器,包括模块下的所有子模块。**named_children()**方法:返回一个生成器,包括模块下的所有子模块,以及它们的名字。**modules()**方法:返回一个生成器,包括模块下的所有各个层级的模块,包括模块本身。**named_modules()**方法:返回一个生成器,包括模块下的所有各个层级的模块以及它们的名字,包括模块本身。
其中 **chidren()** 方法和 **named_children()** 方法较多使用。**modules()** 方法和 **named_modules()** 方法较少使用,其功能可以通过多个 **named_children()** 的嵌套使用实现。
下面看一个例子:
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.embedding = nn.Embedding(num_embeddings = 10000,embedding_dim = 3,padding_idx = 1)self.conv = nn.Sequential()self.conv.add_module("conv_1",nn.Conv1d(in_channels = 3,out_channels = 16,kernel_size = 5))self.conv.add_module("pool_1",nn.MaxPool1d(kernel_size = 2))self.conv.add_module("relu_1",nn.ReLU())self.conv.add_module("conv_2",nn.Conv1d(in_channels = 16,out_channels = 128,kernel_size = 2))self.conv.add_module("pool_2",nn.MaxPool1d(kernel_size = 2))self.conv.add_module("relu_2",nn.ReLU())self.dense = nn.Sequential()self.dense.add_module("flatten",nn.Flatten())self.dense.add_module("linear",nn.Linear(6144,1))self.dense.add_module("sigmoid",nn.Sigmoid())def forward(self,x):x = self.embedding(x).transpose(1,2)x = self.conv(x)y = self.dense(x)return ynet = Net()
上面建立了一个神经网络, 包含两个子模块, 分别用的模型容器建立的(这个下面就会说), 我们这里重点是看看这个网络的子模块到底怎么访问到:
i = 0for child in net.children():i+=1print(child,"\n")print("child number",i)
结果如下: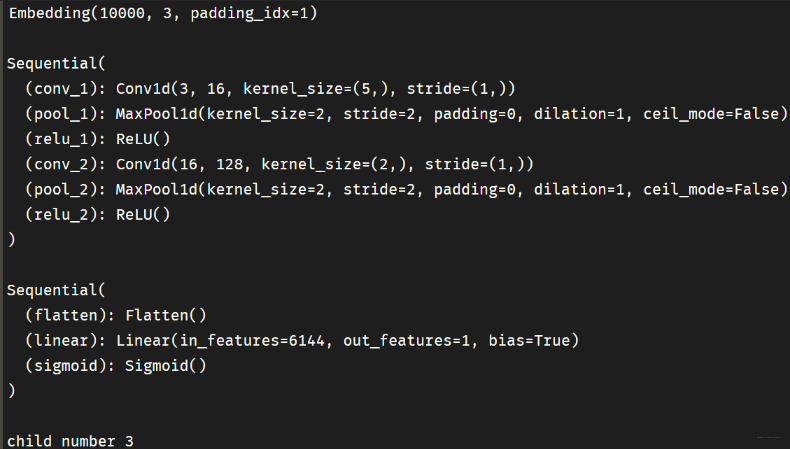
如果是 **net.named_children()**,这个会在模块前面加上 **conv: , dense:** , 表示它们的名字。
下面我们通过 named_children 方法找到 embedding 层,并将其参数设置为不可训练(相当于冻结 embedding 层)。这个在迁移学习的时候非常有用。
children_dict = {name:module for name,module in net.named_children()}print(children_dict)embedding = children_dict["embedding"]embedding.requires_grad_(False) #冻结其参数#可以看到其第一层的参数已经不可以被训练了。for param in embedding.parameters():print(param.requires_grad) # Falseprint(param.numel()) # 30000
关于Pytorch提取神经网络层结构、层参数及自定义初始化,参考这篇文章
2. 模型容器 Containers
上面我们学习的模型的搭建过程,包括两个要素:构建子模块和拼接子模块, 在搭建模型中,还有一个非常重要的概念,那就是模型容器 Containers 。 下面我们就来看看这是个啥东西啊?依然是先观察整体框架: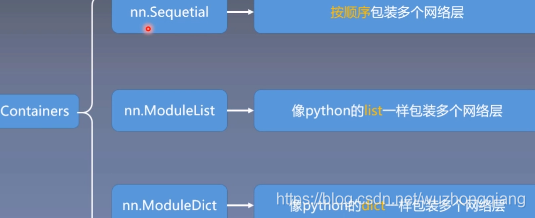
Containers 这个容器里面包含 3 个子模块,分别是 **nn.Sequential**、**nn.ModuleList**、**nn.ModuleDict**,下面我们来看一看:
2.1 nn.Sequential
这是 nn.module 的容器,用于 按顺序 包装一组网络层。
我们知道, 在机器学习中,特征工程部分是一个很重要的模块,但是到了深度学习中,这部分的重要性就弱化了,深度学习中更偏向于让网络自己提取特征,然后进行分类或者回归任务, 所以就像上面的 LeNet 那样,对于图像的特征,我们完全不需要人为的设计, 只需要从前面加上卷积层让网络自己学习提取,后面加上几个全连接层进行分类等任务。 所以在深度学习时代,也有习惯,以全连接层为界限,将网络模型划分为特征提取模块和分类模块以便更好的管理网络。
所以我们的 LeNet 模型,可以把前面的那部分划分为特征提取部分,后面的全连接层为模型部分。
下面我们通过代码来观察,使用 sequential 包装一个 LeNet ,看看是怎么做的:
class LeNetSequential(nn.Module):def __init__(self, classes):super(LeNetSequential, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 6, 5),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, 5),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.classifier = nn.Sequential(nn.Linear(16*5*5, 120),nn.ReLU(),nn.Linear(120, 84),nn.ReLU(),nn.Linear(84, classes),)def forward(self, x):x = self.features(x)x = x.view(x.size()[0], -1)x = self.classifier(x)return x
可以看到,我们的 LeNet 在这里分成了两大部分,第一部分是 features 模块,用于特征提取, 第二部分是 classifier 部分,用于分类。 每一部分都是各种网络的堆叠,然后用 sequential 包装起来。 然后它的 forward 函数也比较简单, 只需要 features 处理输出,然后形状变换,然后 classifier 就搞定。
下面通过代码调试,观察通过 Sequential 搭建的 LeNet 里面的一些属性,并且看看 Sequential 是一个什么样的机制: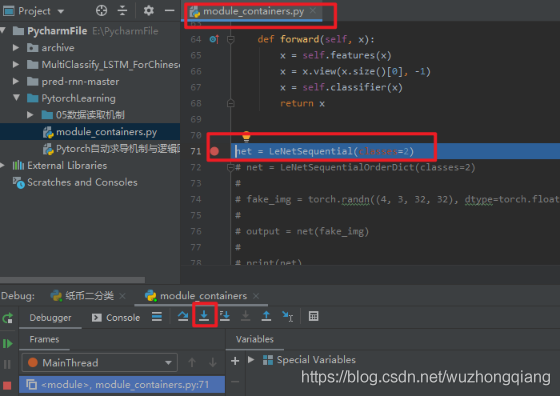
这次调试应该轻车熟路,打断点,debug, 步入即可,这样会到了 LeNetSequential 这个类里面去, 我们通过 super 进行初始化,因为这个继承的也是 nn.Module ,所以肯定也是 8 个属性字典,这个就不管了, stepover 一步步的往下,到一个 Sequential 完成的位置停下来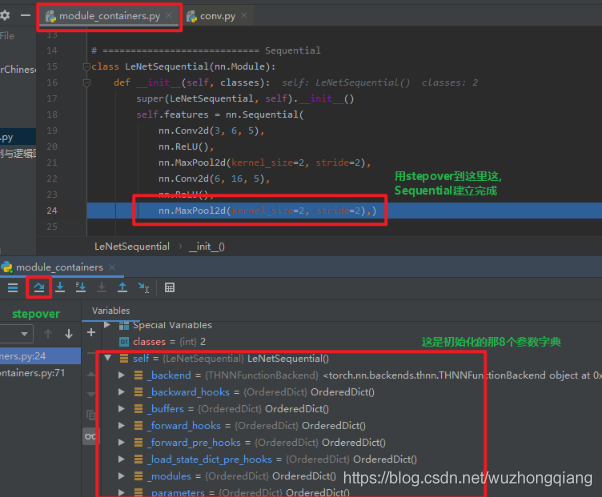
然后,stepinto->stepout->stepinto,进入 container.py 的 Sequential 这个类。会发现 **class Sequential(Module):** , 这说明 Sequential 也是继承与于 Module 这个类的,所以它也会有那 8 个参数字典。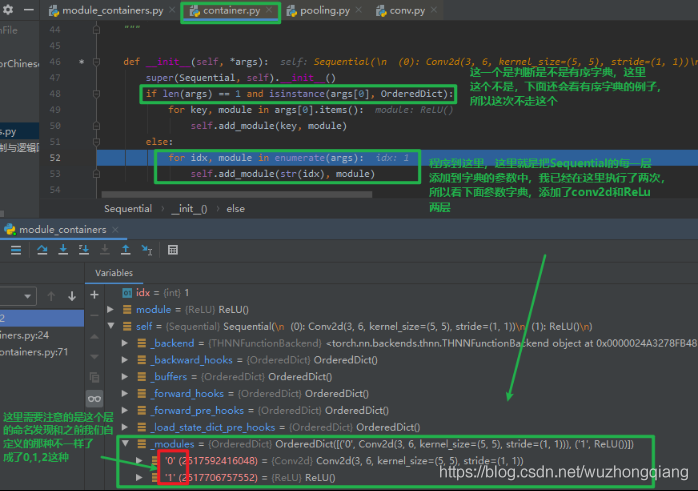
这样,一直 stepover, 直到第 5 个子模块完事,这样一个 Sequential 就建完了。 我们 stepout 回到主程序,然后往下执行,把第一个 Sequential 构建完毕。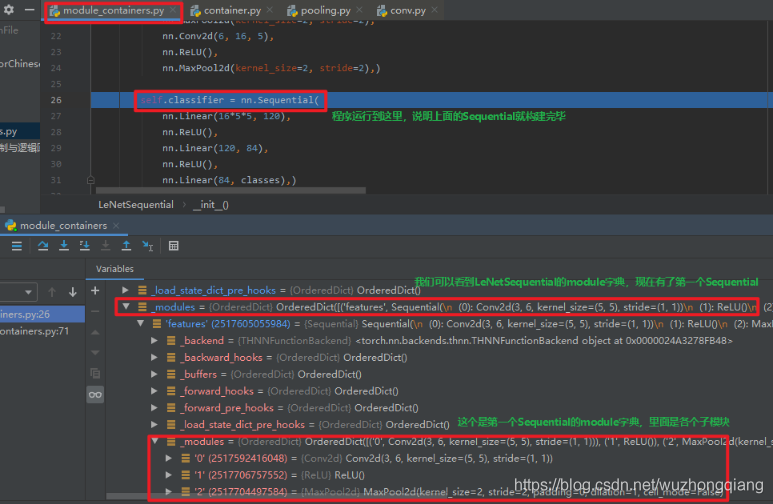
下面的那个 Sequential 构建其实原理和第一个的一样了,所以不再进行调试查看,简单梳理一下 Sequential 的构建机制, 这个依然是继承 Module 类,所以也是在 **__init__** 方法中先调用父类去初始化 8 个有序字典,然后再 **__init__** 里面完成各个子模块的参数存储。 这样,子模块构建完成,还记得我们模型搭建的第一步吗?
接下来,就是拼接子模块, 这个是通过前向传播函数完成的,所以下面我们看看 Sequential 是怎么进行拼接子模块的,依然是调试查看(这部分调试居多,因为这些内部机制,光靠文字写是没法写的,与其写一大推迷迷糊糊,还不如截个图来的痛快), 我们看前向传播: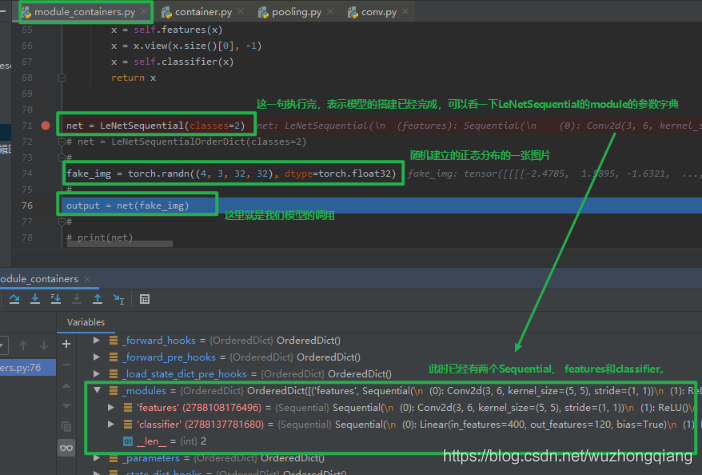
这时候步入这个 net 函数, 看看前向传播的实现过程,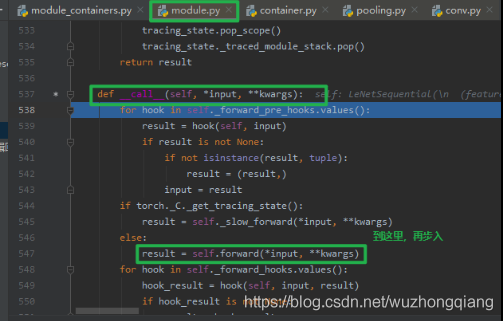
步入之后,就到了 module.py 的 **__call_** 函数, 就是在这里面调用前向传播的: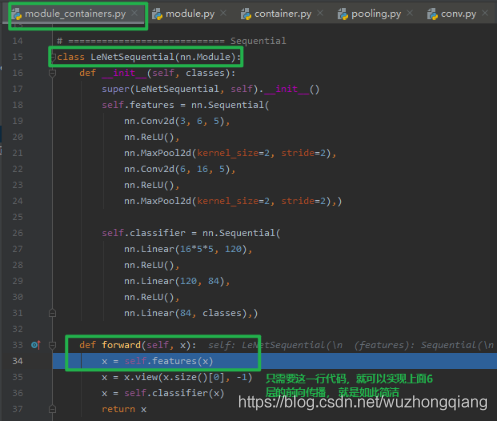
步入之后,我们跳到了 LeNetSequential 类的前向传播函数,我们可以发现,完成第一个 Sequential ,也就是 features 的前向传播,只用了一句代码 **x = self.features(x)**,这句代码竟然实现了 6 个子模块的前向传播,这是怎么做到的呢? 在这行代码步入一探究竟: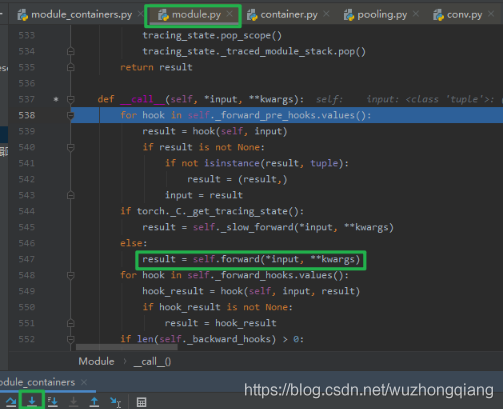
由于 **self.features** 是一个 Sequential , 而 Sequential 也是继承于 Module ,所以我们步入之后,依然是会跳到 module.py 的 `**_call函数, 我们还是 stepout 到前向传播的那一行,然后步入看看 Sequential 的前向传播。<br />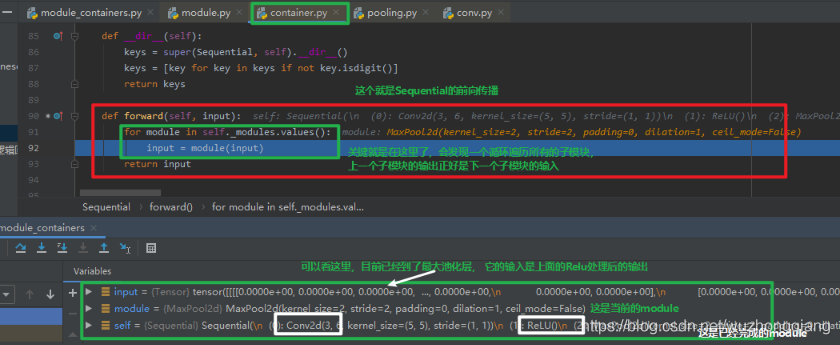<br />从上面可以看出,在 Sequential 的前向传播里面,会根据之前定义时候的那个_module` 那个有序的参数字典,这里面就是存的每个层的信息还记得吗? 前向传播的时候,就是遍历这个东西, 得到每个子模块,进行处理。 这里要注意一下,这是个串联机制,也就是上一层的输出会是下一层的输入**。所以要注意上下模型输入和输出的对应关系,数据格式,形状大小不要出错。
这就是 Sequential 的 forward 的机制运行的步骤了,所以通过调试还是能把这个原理了解的很清楚的,下面的 **self.classifier** 的前向传播也是如此,这里不再过多赘述。
所以模型的拼接这块也简单梳理一下, 这一块的拼接完全是 Sequential 自己实现的, 在 Sequential 定义的时候,会把每一层的子模块的信息存入到它的 **_modules** 这个有序字典中,然后前向传播的时候, Sequential 的 **forward** 函数就会遍历这个字典,把每一层拿出来然后处理数据,这是一个串行,上一层的输出正好是下一层的输入。这样通过这个迭代就可以完成前向传播过程。
下面完成调试,得到我们建好的 LeNetSequential 最终的结构: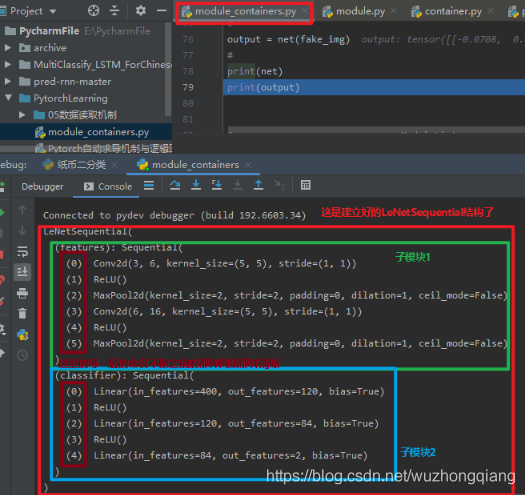
在上一次的学习中,我们会发现网络层是有名字的,比如 conv1, conv2,这种,这样可以通过名字去索引网络层, 而这里成了序号了,如果网络层成千上百的话,很难通过序号去索引网络层,这时候,我们可以对网络层进行一个命名。 也就是第二种 Sequential 的使用方法:
class LeNetSequentialOrderDict(nn.Module):def __init__(self, classes):super(LeNetSequentialOrderDict, self).__init__()self.features = nn.Sequential(OrderedDict({'conv1': nn.Conv2d(3, 6, 5),'relu1': nn.ReLU(inplace=True),'pool1': nn.MaxPool2d(kernel_size=2, stride=2),'conv2': nn.Conv2d(6, 16, 5),'relu2': nn.ReLU(inplace=True),'pool2': nn.MaxPool2d(kernel_size=2, stride=2),}))self.classifier = nn.Sequential(OrderedDict({'fc1': nn.Linear(16*5*5, 120),'relu3': nn.ReLU(),'fc2': nn.Linear(120, 84),'relu4': nn.ReLU(inplace=True),'fc3': nn.Linear(84, classes),}))def forward(self, x):x = self.features(x)x = x.view(x.size()[0], -1)x = self.classifier(x)return x
这里面 Sequential 包装的就是一个有序的字典, 字典中是网络名:网络层的形式。通过这个就可以对每一层网络进行命名, 那它是什么时候进行命名的呢? 当然还是在定义的时候,上面的某张图片里面我其实已经埋好了伏笔: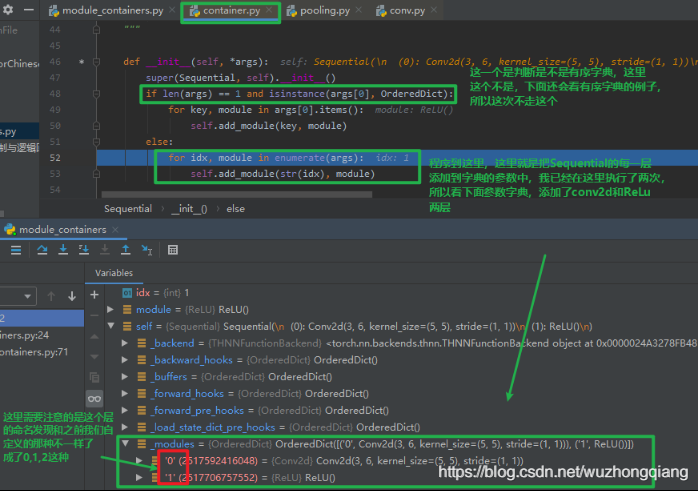
就是它了, 我们会看到, Sequential 的初始化方法里面有个判断的,if后面其实就是判断传入的是不是个有序字典, 我们上次 Sequential 里面直接是各个层,所以当时不满足 **if**,跳到了下面的 **else**,那里面是 **self.add_module(str(idx), module)** 这个很清楚了吧,就是不是有序字典,说明我们没命名,那么就用数字索引命名,然后加入到 **_module** 有序参数字典中。 而这次我们是构建了个有序字典,那么就应该走 **if**,这里面是 **self.add_module(key, module**) , 这一次我们命名了,所以就用我们的命名,把 **key(网络名):value(网络层)** 存入到 **_module** 有序参数字典中。这样,我们搭建的网络层就会有名字了。
下面对我们的 Sequential 进行一个总结:nn.Sequential 是 nn.module 的容器, 用于 按顺序 包装一组网络层
- 顺序性:各网络层之间严格按照顺序构建,这时候一定要注意前后层数据的关系
- 自带forward():自答的 forward 里,通过 for 循环依次执行前向传播运算
2.2 nn.ModuleList
nn.ModuleList 是 nn.module 的容器, 用于包装一组网络层, 以 迭代 方式调用网络层, 主要方法:
**append()**:在 ModuleList 后面添加网络层。**extend()**:拼接两个 ModuleList 。**insert()**:指定在 ModuleList 中位置插入网络层。
我们可以发现,这个方法的作用其实类似于我们的列表,只不过元素换成网络层而已,下面我们学习 ModuleList 的使用,我们使用 ModuleList 来循环迭代的实现一个 20 个全连接层的网络的构建。
class ModuleList(nn.Module):def __init__(self):super(ModuleList, self).__init__()self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(20)])def forward(self, x):for i, linear in enumerate(self.linears):x = linear(x)return x
这一个就比较简单了, ModuleList 构建网络层就可以使用列表生成式构建,然后前向传播的时候也是遍历每一层,进行计算即可。我们下面调试就是看看这个 ModuleList 的初始化,是怎么把 20 个全连接层给连起来的。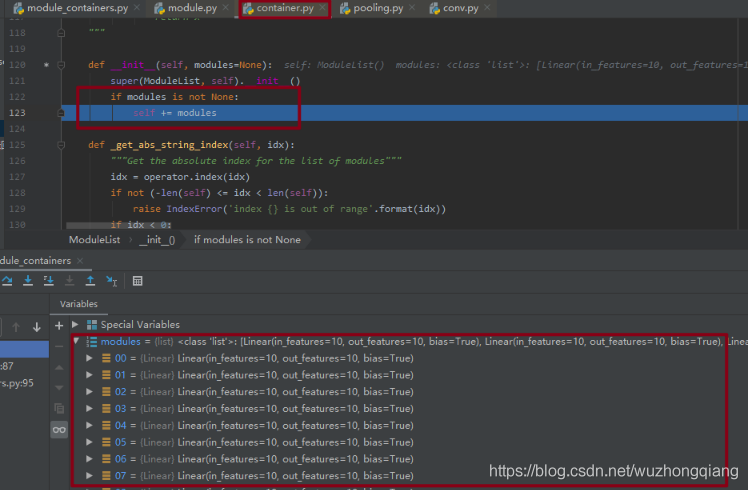
可以看到这个 modules 是一个列表,里面就是这 20 个全连接层。 前向传播也比较简单了,用的 for 循环获取到每个网络层,这里就不调试了。
这样就完成了一个 20 层的全连接层的网络的实现。借助 nn.ModuleList 只需要一行代码就可以搞定。这就是 nn.ModuleList 的使用了,最重要的就是可以迭代模型,索引模型。
2.3 nn.ModuleDict
nn.ModuleDict 是 nn.module 的容器, 用于包装一组网络层, 以索引方式调用网络层, 主要方法:
**clear()**:清空 ModuleDict 。**items()**:返回可迭代的键值对(key-value pairs)**keys()**:返回字典的键(key)**values()**:返回字典的值(value)**pop()**:返回一对键值对, 并从字典中删除
可以通过 ModuleDict 实现网络层的选取, 我们看下面的代码:
class ModuleDict(nn.Module):def __init__(self):super(ModuleDict, self).__init__()self.choices = nn.ModuleDict({'conv': nn.Conv2d(10, 10, 3),'pool': nn.MaxPool2d(3)})self.activations = nn.ModuleDict({'relu': nn.ReLU(),'prelu': nn.PReLU()})def forward(self, x, choice, act):x = self.choices[choice](x)x = self.activations[act](x)return xnet = ModuleDict()fake_img = torch.randn((4, 10, 32, 32))output = net(fake_img, 'conv', 'relu') # 在这里可以选择我们的层进行组合print(output)
这个理解起来应该比较好理解了, 前面通过 **self.choices** 这个 ModuleDict 可以选择卷积或者池化, 而下面通过 **self.activations** 这个 ModuleDict 可以选取是用哪个激活函数, 这个东西在选择网络层的时候挺实用,比如要做时间序列预测的时候,我们往往会用到 GRU 或者 LSTM , 我们就可以通过这种方式来对比哪种网络的效果好。 而具体选择哪一层是前向传播那完成,会看到多了两个参数。也是比较简单的。
到这里我们就学习了三个容器:**nn.Sequential**、**nn.ModuleList**、**nn.ModuleDict** 。 下面总结一下它们的应用场合:
下面就来研究一个网络模型了,这个是 Pytorch 提供的, 叫做 AlexNet 网络模型。
3. AlexNet构建
这是一个划时代的卷积神经网络,2012 年在 ImageNet 分类任务中获得了冠军,开创了卷积神经网络的新时代。 AlexNet 的特点如下:
- 采用 ReLu:替换饱和激活函数, 减轻梯度消失
- 采用 LRN(Local Response Normalization):对数据归一化,减轻梯度消失(后面被 Batch 归一化取代了)
- Dropout:提高全连接层的鲁棒性,增加网络的泛化能力
- Data Augmentation:TenCrop,色彩修改
下面就看看 AlexNet 的结构: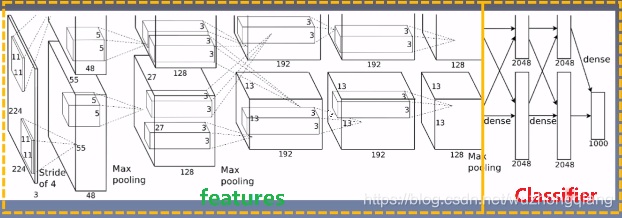
下面看看 AlexNet 的源代码:
class AlexNet(nn.Module):def __init__(self, num_classes=1000):super(AlexNet, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(64, 192, kernel_size=5, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(192, 384, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),)self.avgpool = nn.AdaptiveAvgPool2d((6, 6))self.classifier = nn.Sequential(nn.Dropout(),nn.Linear(256 * 6 * 6, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes),)def forward(self, x):x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return x
它这个就是用 Sequential 进行搭建的,分三部分, 第一部分是一个 Sequential,由一系列的卷积池化模块构成,目的是提取图像的特征, 然后是一个全局的池化层把特征进行整合,最后有一个 Sequential 是全连接层组成的,用于模型的分类。 这样就完成了 AlexNet 网络的搭建, forward 函数汇总也是非常简单了,这里就不再详细赘述了。
到这里就基本上完成了这篇文章的内容,不知道你发现了吗? 如果你理解了这篇文章的内容,就会发现理解像 AlexNet 这样的网络构建非常简单, 当然在 Pytorch 的 models 模块中还有很多其他的经典网络,像googlenet、vgg、ResNet 等很多,学习了今天的知识之后,这些模型的构建都可以去查看了。 不管这些模型多么复杂, 构建依然还是我们的 **nn.Module**、**Sequential**、**ModuleList**、**ModuleDict** 的这些内容去构建的,所以我们依然可以看懂这些网络的逻辑。
4. 总结
今天的学习内容结束, 这次的内容有点多,并且还非常的重要,所以依然是快速梳理总结, 今天的内容主要是分为 3 大块, 第一块就是 Pytorch 模型的构建步骤有两个子模块的构建和拼接, 然后就是学习了非常重要的一个类叫做 nn.Module ,这个是非常重要的,后面的模型搭建中我们都得继承这个类,这就是祖宗级别的人物了。这里面有8个重要的参数字典,其中 **_parameters** 和 **_modules** 更是重中之重,所以以 LeNet 为例,通过代码调试的方式重点学习了 LeNet 的构建过程和细节部分。
第二块是我们的模型容器 Containers 部分,这里面先学习了 nn.Sequential , 这个是顺序搭建每个子模块, 常用于 block 构建,依然是通过代码调试看了它的初始化和自动前向传播机制。 然后是 nn.ModuleList , 这个类似于列表,常用于搭建结构相同的网络子模块, 特点就是可迭代。 最后是 nn.ModuleDict , 这个的特点是索引性,类似于我们的 python 字典,常用于可选择的网络层。
第三块就是根据上面的所学分析了一个非常经典的卷积神经网络 AlexNet 的构建过程, 当然也可以分析其他的经典网络构建的源代码了。当然,只是可以去看懂网络结构的代码,不要奢求一下子就会写,闭着眼就能自己敲出来, 如果你看一遍就能敲出这么复杂的网络结构,那就是超神了,祝贺你。 反正我目前是做不到, 如果想达到用 Pytorch 写神经网络的地步,就需要后面多多实践,还是那句话,无他,唯手熟尔!😉
下面依然是一张思维导图把知识拎起来: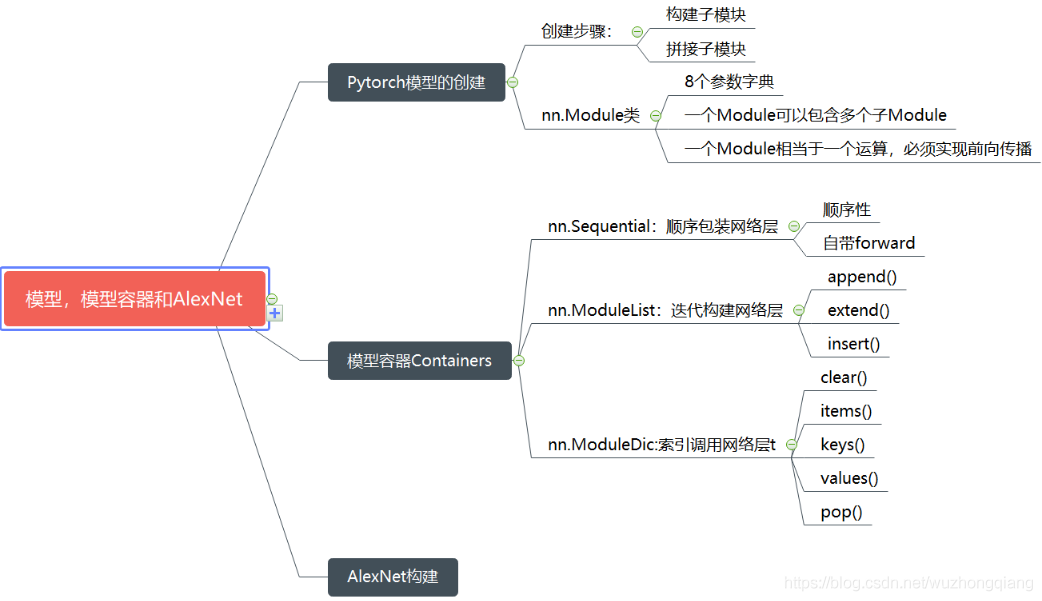
今天的知识就到这里,下一次我们就从这一次的基础上更进一步,学习几个比较重要的子模块,比如卷积,池化, 全连接等。继续rush!😉
所有代码链接:
链接:https://pan.baidu.com/s/1YPmOtLCjsfu8KDGGgJ09Ug提取码:u8ti

若有收获,就点个赞吧
0 人点赞
